A quick introduction to Python regular expressions
Regular expressions are often used in program development, such as data (format) verification, replacing character content, and extracting string content, etc., but at present, many developers are only understanding or basic knowledge of regular expressions. Used stage. Once you encounter large-scale use of regular expressions (such as web crawlers), it can be said that you are basically blind. In this article, I will lead you to learn regular expressions using Python. Before reading this article, you need to master the basic knowledge of Python, or have basic knowledge of other development languages, because basically every language uses regular expressions in a similar way.
Zero, regular expression basics####
- Extract characters (string)
Sometimes we need to get a piece of content from a string. This piece of content may be a character or a string of characters. If you use a verbatim comparison to traverse, it is not only time-consuming and labor-intensive, but also error-prone. Then at this time we can use the character matching function in regular expressions. Regular expressions provide us with 4 character matching methods, see the following table:
| Syntax | Description | Example | matchable string |
|---|---|---|---|
| . | Match any character except line break "\n" | ab | acb, adb, a2b, a~b |
| | Escaping, changing the original meaning of a character after the transferred character | a[b.\]c | abc, ac, a\c | |
| [] | Match any character in brackets | a[b,c,d,e]f | abd, acf, adf, aef |
| [^] | Except for the characters in parentheses, all other characters match | a[^a,b,c,d,e]f | a1f, a#f, azf, agf |
- Predefined characters
The so-called predefined characters are the characters reserved for us in regular expressions to match formatted content, such as \d for matching numbers and \s for matching whitespace characters. We can use the predefined characters to quickly match the content in a string that meets the requirements. The content of the predefined character matching can also be matched by the character matching method mentioned above, but the amount of code will be relatively larger. The following table lists the predefined characters:
| Syntax | Description | Example | matchable string |
|---|---|---|---|
| ^ | What string to start with | ^123 | 123abc、123321、123zxc |
| $ | What string ends with | 123$ | abc123、321123、zxc123 |
| \ b | Match word boundaries, not any characters | \basd\b | asd |
| \ d | Match numbers 0-9 | zx\dc | zx1c, zx2c, zx5c |
| \ D | Match non-digits | zx\Dc | zxvc, zx$c, zx&c |
| \ s | match whitespace characters | zx\sc | zx c |
| \ S | Match non-whitespace characters | zx\Sc | zxac, zx1c, zxtc |
| \ w | Match letters, numbers and underscores | zx\wc | zxdc, zx1c, zx_c |
| \ W | matches non-letters, numbers and underscores | zx\Wc | zx c, zx$c, zx(c |
The following points need to be noted in the predefined characters:
- \ b matches only a position. One side of this position is the characters that make up the word, and the other side is the non-word character, the beginning or end of the string. \b is zero width.
- \ w The range of matching in different encoding languages is different. In a language that uses ASCII code, it matches [a-zA-Z0-9_], while in a language that uses Unicode code, it matches [a-zA- Z0-9_] and special characters such as Chinese characters and full-width symbols.
- Limited number
In some cases we need to match repeated content, then we can use the quantity limit mode to operate. The quantity is limited as follows:
| Syntax | Description | Example | matchable string |
|---|---|---|---|
| * | Match 0 to many times | zxc* | zx, zxccccc |
| + | Match 1 to many times | zxc+ | zxc, zxccccc |
| ? | Match 0 or 1 time | zxc? | zxc、zx |
| { m} | Match m times | zxc{3}vb | zxcccvb |
| { m,} | Match m or more times | zxc{3,}vb | zxcccvb, zxccccccccvb |
| {, n} | Match 0 to n times | zxc{,3}vb | zxvb, zxcvb, zxccvb, zxcccvb |
| { m,n} | Match m to n times | zxc{1,3} | zxcvb, zxccvb, zxcccvb |
- assertion
Assertion, also known as zero-width assertion, refers to matching when the assertion expression is True, but does not match the content of the assertion expression. Like ^ stands for the beginning, $ stands for the end, and \b stands for the word boundary, the pre-assertion and the next predicate have similar functions. They only match certain positions and do not occupy characters during the matching process, so they are called zero-width. The so-called position refers to the left side of the first character, the right side of the last character and the middle of adjacent characters in the string. There are four types of zero-width assertion expressions:
- Assert after zero-width negative review (? <!exp),表达式不成立时匹配断言后面的位置,成立时不匹配。例如 \w+(?<zxc)\d,匹配不以 zxc 结尾的字符串;
- Zero-width negative review look-ahead assertion (?!exp), the expression matches the position before the assertion, and does not match if it is true. For example: \d(?!zxc)\w+, match the string that does not start with zxc;
- Advance assertion (?=exp), when the assertion is true, match the position in front of the assertion. For example, to match the re in regular in the string "a regular expression", we can write re(?=gular);
- Post an assertion (?<=exp). When the assertion is true, match the position after the assertion. For example, for the string "egex represents regular expression", if you want to match re other than regex and regular, you can use re(?!g ), the expression limits the position to the right of re, which is not followed by the character g. The difference between first and last is whether the character after that position can match the expression in the brackets.
- Greedy/non-greedy
Regular expressions will match as many characters as possible. This is called greedy mode. Greedy mode is the default mode of regular expressions. But sometimes the greedy mode will cause unnecessary trouble for us. For example, we need to match the "Jack123Chen" in the string "Jack123Chen123Chen", but the greedy mode matches "Jack123Chen123Chen". At this time, we need to use non-greedy Mode to solve this problem, the commonly used expressions of non-greedy mode are as follows:
| Grammar | Description |
|---|---|
| *? | Match 0 or more times, but repeat as little as possible |
| +? | Match 1 or more times, but repeat as little as possible |
| ?? | Match 0 or 1, but repeat as little as possible |
| { m,}? | Match m or more times, but repeat as little as possible |
| { m,n}? | Match m or n times, but repeat as little as possible |
- other
The above content is commonly used in regular expressions. Let's look at the grammar that is not commonly used but is equally powerful.
- OR matching is also called matching branch, which means that as long as there is a branch matching, it is considered a match, which is similar to the OR statement we use in development. OR matching uses | to split the branch. For example, we need to match English names, but in English, the surname and first name may be separated by ·, or separated by spaces, then we can use OR matching to Deal with this problem. The format is as follows: [A-Za-z]+·[A-Za-z]+|[A-Za-z]+\s[A-Za-z]+
- Combination, combining several items into a unit, this unit can be modified by symbols such as * +? |, and the string matching this combination can be memorized to provide a waiting reference. Grouping is represented by (). For example, the regular expression to get the date can be written like this: \d{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]| 3[01]). The first group (0[1-9]|1[0-2]) represents the regular match of the month, and the second group (0[1-9]|[12][0-9]|3[01] ) Represents the regular match of the day.
1. Python uses regular expressions####
Using regular expressions in Python is very simple, the re module provides us with regular expression support. There are three steps to use:
- Convert the regular expression string to an instance of Pattern;
- Use the Pattern instance to process the characters to be matched, the matching result is a Match instance;
- Use the Match instance to perform subsequent operations.
There are six commonly used re methods in Python, namely: compile, match, search, findall, ** split** and sub, the following will explain these six methods.
- compile
The function of the compile method is to convert a regular expression string into a Pattern instance. It has two parameters pattern and flags. The pattern parameter type is string type, and it receives regular expression strings, flags. The type is int, and the received is the number of the matching pattern. The flags parameter is optional, and the default value is 0 (ignoring case). The flags matching modes are as follows:
| Matching mode | Description |
|---|---|
| re.I | Ignore case |
| re.M | Multi-line matching mode |
| re.S | Any matching mode |
| re.L | Predefined character matching mode |
| re.U | Limited character matching mode |
| re.V | Detailed Mode |
The above six modes are rarely used in actual development, we just need to understand. Using compile is very simple, as follows:
import re
pattern = re.compile(r'\d')
- match
The function of match is to use the Pattern instance to match from the left side of the string. If it matches, it returns a Match instance, and if it does not match, it returns None.
import re
def getMatch(message):
pattern = re.compile(r'(\d{4}[-year])(\d{2}[-month])(\d{2}day{0,1})')
match = re.match(pattern, message)if match:print(match.groups())for item in match.groups():print(item)else:print("Did not match")if __name__ =='__main__':
message ="The conference begins on January 23, 2019"getMatch(message)
message ="Conference in 2019-01-23 held"getMatch(message)
In the code, we use the groups method, which is used to obtain the matched string groups. After arriving here, many readers will wonder why the first paragraph can match the year, month and day, but the second paragraph cannot? This is because the match method matches from the beginning of the string. The results of the code operation are as follows:
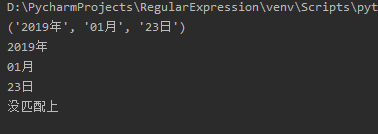
- search
The search method is the same as the match method, except that the search method matches the entire string. Modify the getMatch method in the code in the previous section to match the year, month and day in the second paragraph.
import re
def getMatch(message):
pattern = re.compile(r'(\d{4}[-year])(\d{2}[-month])(\d{2}day{0,1})')
match = re.search(pattern, message)if match:print(match.groups())for item in match.groups():print(item)else:print("Did not match")if __name__ =='__main__':
message ="The conference begins on January 23, 2019"getMatch(message)
message ="Conference in 2019-01-23 held"getMatch(message)
The results of the above code operation are as follows:
[ The external link image transfer failed. The source site may have an anti-leech link mechanism. It is recommended to save the image and upload it directly (img-VmTrXNxa-1575984679614)(https://s2.ax1x.com/2019/12/03/QQ8fR1.png) ]
4. findall
The function of the findall method is to match the entire string and return all matching results in the form of a list.
import re
def getMatch(message):
pattern = re.compile(r'\w+')
match = re.findall(pattern, message)if match:print(match)else:print("Did not match")if __name__ =='__main__':
message ="my name is Zhang San"getMatch(message)
message ="Zhang San is me"getMatch(message)
The code running result is as follows:
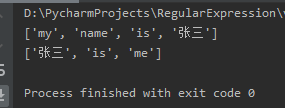
- split
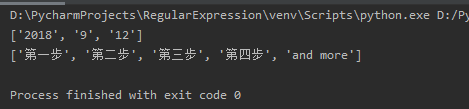
The split method uses specified characters to split a string.
import re
def getMatch(message):
pattern = re.compile(r'-')
match = re.split(pattern, message)if match:print(match)else:print("Did not match")if __name__ =='__main__':
message ="2018-9-12"getMatch(message)
message ="first step-Second step-third step-the fourth step-and more"getMatch(message)
The results of the above code operation are as follows:
- sub
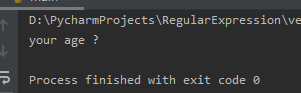
The sub method is used to replace strings. It accepts 5 parameters, three of which are commonly used:
- pattern, Pattern instance
- string, the string to be replaced
- repl, representing the new string to be replaced or the replacement method that needs to be performed
- count, the number of replacements, the default is 0 to replace all
import re
def getMatch(match):return match.group(0).replace(r'age','age')if __name__ =='__main__':
message ="your age?"
pattern=re.compile(r'\w+')print(re.sub(pattern,getMatch,message))
The code running result is as follows:
Three, summary
Regular expressions in Python are very convenient to use. The code shown above can be copied directly and used in the project with slight modifications. The content is not much, mainly to explain how to use the code, I hope everyone fully understands and masters the writing of regular expressions.
Recommended Posts