One article to get regular expressions in Python
Detailed re module###
This article explains in detail regular expressions and the re module in Python
- What is regular expression
- Regular expression function
- Metacharacters and their meaning
- Detailed re module
- Regex modifier
- Regular expression example

<!- - MORE-->
Contents of this article###
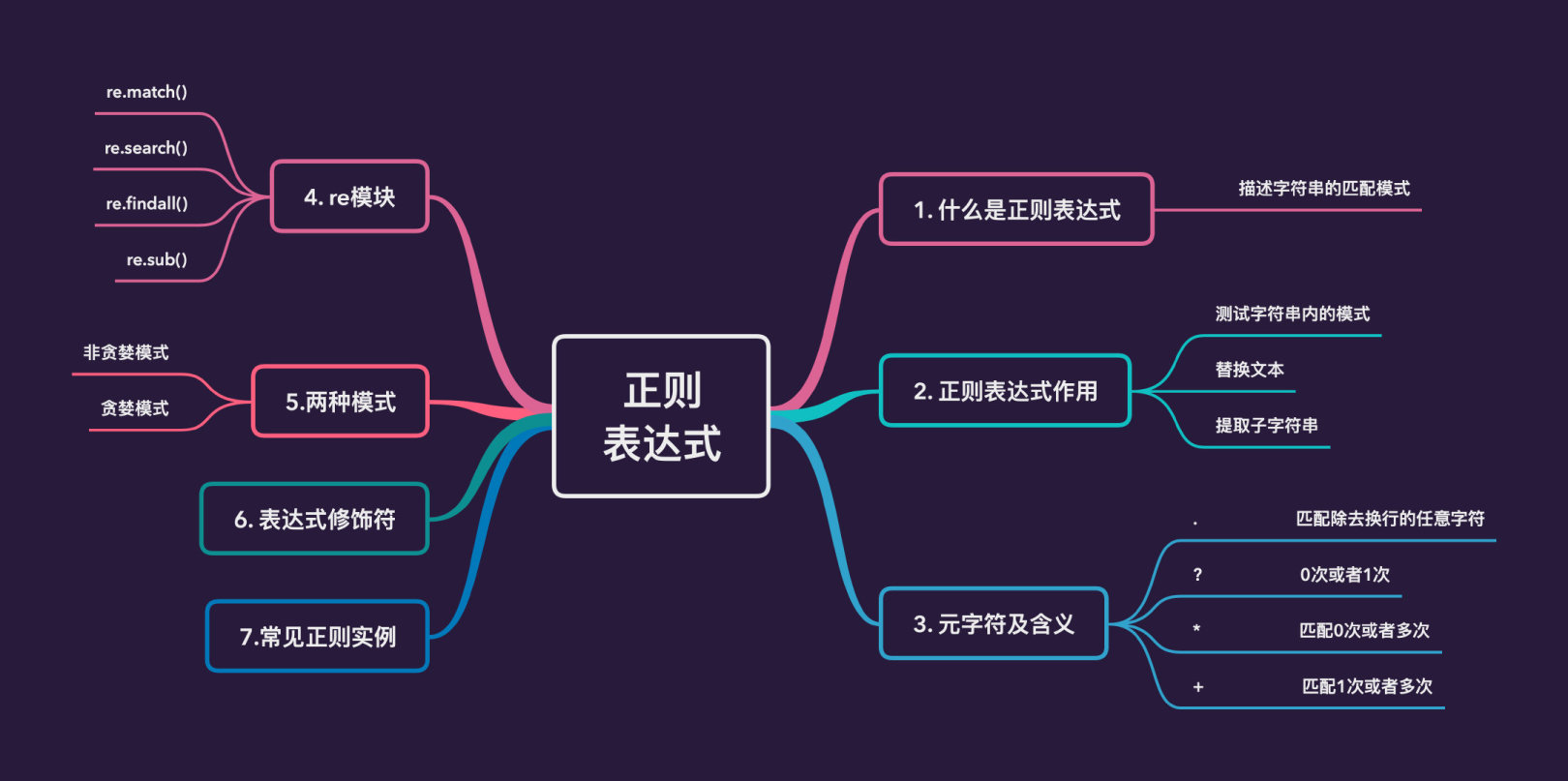
What is a regular expression
Regular expression (regular expression) describes a string matching pattern (pattern), can be used to check whether a string contains a certain substring, replace the matched substring, or extract from a string that meets a certain condition Substring etc.
Regular expression function###
By using regular expressions, you can:
- Test the pattern within the string
For example, you can test the input string to see if a phone number pattern or a credit card number pattern appears in the string. This is called data verification. - Replacement text
You can use regular expressions to identify specific text in a document, delete the text completely or replace it with other text. - Extract substrings from strings based on pattern matching
You can search for specific text in the document or in the input field, such as the content that you need directly from the content of the webpage through the crawler
Metacharacters and their meaning
Commonly used metacharacters
| Symbol | Meaning |
|---|---|
| Dot. | Matches any character except line breaks |
| Asterisk* | Match 0 or more arbitrary characters |
| question mark? | Match 0 or 1 any character (non-greedy mode) |
| ^ | Start position |
| $ | End position |
| \ s | matches any blank |
| \ S | matches any non-blank |
| \ d | matches a digit |
| \ D | matches a non-digit |
| \ w | matches a word character, contains numbers and letters |
| \ W | matches a non-word character, including numbers and letters |
| abcd | Match any character in abcd |
| ^ abcd | matches any character that does not include abcd |
| Match the previous content one or more times | |
| { n} | match n words (fixed) |
| { n,} | Match at least n times |
| { n,m) | match n to m times |
| x | y |
| () | Match the content in the brackets |
Metacharacters
The following is a relatively complete metacharacter matching table
| Metacharacter | description |
|---|---|
| \ | Put the next character token, or a backward quote, or an octal escape character. For example, "\n" matches\n. "\N" matches a newline character. The sequence "" matches "" and "(" matches "(". It is equivalent to the concept of "escape character" in many programming languages. |
| ^ | Match the beginning of the input line. If the Multiline property of the RegExp object is set, ^ also matches the position after "\n" or "\r". |
| $ | Matches the end of the input line. If the Multiline property of the RegExp object is set, $ also matches the position before "\n" or "\r". |
| Match the preceding sub-expression any number of times. For example, zo* can match "z", as well as "zo" and "zoo". *Equivalent to {0,}. | |
| Match the preceding sub-expression one or more times (greater than or equal to 1 time). For example, "zo+" can match "zo" and "zoo", but not "z". +Equivalent to {1,}. | |
| ? | Matches the preceding subexpression zero or one time. For example, "do(es)?" can match "do" or "does". ? Equivalent to {0,1}. |
| {* n*} | n is a non-negative integer. Match confirmed n times. For example, "o{2}" cannot match the "o" in "Bob", but it can match the two o's in "food". |
| {* n*,} | n is a non-negative integer. Match at least n times. For example, "o{2,}" cannot match the "o" in "Bob", but it can match all o in "foooood". "O{1,}" is equivalent to "o+". "O{0,}" is equivalent to "o*". |
| {* n*,m} | m and n are non-negative integers, where n<=m. Match at least n times and match at most m times. For example, "o{1,3}" will match the first three o's in "fooooood" as a group, and the last three o's as a group. "O{0,1}" is equivalent to "o?". Please note that there can be no spaces between the comma and the two numbers. |
| ? | When the character immediately follows any other qualifiers (*,+,?, {n}, {n,}, {n,m}), the matching mode is non-greedy. The non-greedy mode matches the searched string as little as possible, while the default greedy mode matches the searched string as much as possible. For example, for the string "oooo", "o+" will match "o" as much as possible and get the result "oooo", and "o+?" will match "o" as little as possible, and get the result'o', ' o','o','o' |
| . Dot | matches any single character except "\n" and "\r". To match any character including "\n" and "\r", use a pattern like "\s\S". (Does not match newline characters) |
| ( pattern) | Match pattern and get this match. The obtained matches can be obtained from the generated Matches collection, the SubMatches collection is used in VBScript, and the $0...$9 properties are used in JScript. To match parenthesis characters, use "(" or ")". |
| (?: pattern) | Non-acquisition matching, matching the pattern but not obtaining the matching result, and not storing it for later use. This is useful when using the or character "( |
| (?= pattern) | Non-acquisition matching, positive positive pre-check, matching the search string at the beginning of any string matching pattern, the match does not need to be acquired for future use. For example, "Windows(?=95 |
| (?! pattern) | Non-acquisition matching, forward negative pre-check, matching the search string at the beginning of any string that does not match the pattern, the match does not need to be acquired for future use. For example, "Windows(?!95 |
| (?<= pattern) | Non-acquisition matching, reverse positive pre-check, similar to positive positive pre-check, but in the opposite direction. For example, "(?<=95 |
| (?<! patte_n) | Non-acquisition matching, reverse negative pre-check, similar to forward negative pre-check, but in the opposite direction. E.g"(? <!95 |
| x | y |
| xyz | Character set. Match any one character contained. For example, "abc" can match the "a" in "plain". |
| ^ xyz | Negative character set. Match any character not included. For example, "^abc" can match any character of "plin" in "plain". |
| az | Character range. Match any character in the specified range. For example, "az" can match any lowercase alphabetic character from "a" to "z". Note: Only when the hyphen is inside the character group and appears between two characters, can it represent the range of characters; if it is out of the beginning of the character group, it can only represent the hyphen itself. |
| ^ az | Negative character range. Match any character that is not in the specified range. For example, "^az" can match any character that is not in the range of "a" to "z". |
| \ b | Match the boundary of a word, that is, the position between the word and the space (that is, the "match" of regular expressions has two concepts, one is the matching character, the other is the matching position, where \b is the matching position of). For example, "er\b" can match "er" in "never" but not "er" in "verb"; "\b1*" can match "1*" in "1_23", but it cannot match "1*" in "21*3". |
| \ B | Match non-word boundaries. "Er\B" can match the "er" in "verb" but not the "er" in "never". |
| \ cx | matches the control character specified by x. For example, \cM matches a Control-M or carriage return character. The value of x must be one of AZ or az. Otherwise, treat c as a literal "c" character. |
| \ d | matches a digit character. Equivalent to 0-9. grep needs to add -P, perl regular support |
| \ D | matches a non-digit character. Equivalent to ^0-9. grep should add -P, perl regular support |
| \ f | matches a form feed character. Equivalent to \x0c and \cL. |
| \ n | matches a newline character. Equivalent to \x0a and \cJ. |
| \ r | matches a carriage return character. Equivalent to \x0d and \cM. |
| \ s | Matches any invisible characters, including spaces, tabs, form feeds, etc. Equivalent to \f\n\r\t\v. |
| \ S | matches any visible character. Equivalent to ^ \f\n\r\t\v. |
| \ t | matches a tab character. Equivalent to \x09 and \cI. |
| \ v | matches a vertical tab character. Equivalent to \x0b and \cK. |
| \ w | matches any word character including the underscore. Similar but not equivalent to "A-Za-z0-9_", the "word" character here uses the Unicode character set. |
| \ W | matches any non-word character. Equivalent to "^A-Za-z0-9_". |
| \ xn | matches n, where n is the hexadecimal escape value. The hexadecimal escape value must be two digits long. For example, "\x41" matches "A". "\X041" is equivalent to "\x04&1". ASCII encoding can be used in regular expressions. |
| * num* | matches num, where num is a positive integer. A reference to the obtained match. For example, "(.)\1" matches two consecutive identical characters. |
| * n* | Identifies an octal escape value or a backward reference. If n has at least n acquired sub-expressions before, then n is a backward reference. Otherwise, if n is an octal number (0-7), then n is an octal escape value. |
| * nm* | Identifies an octal escape value or a backward reference. If there are at least nm sub-expressions before nm, then nm is a backward reference. If there are at least n acquisitions before nm, n is a backward reference followed by the text m. If the preceding conditions are not met, if both n and m are octal numbers (0-7), then nm will match the octal escape value nm. |
| * nml* | If n is an octal digit (0-7), and both m and l are octal digits (0-7), match the octal escape value nml. |
| \ un | matches n, where n is a Unicode character represented by four hexadecimal digits. For example, \u00A9 matches the copyright symbol (©). |
| \ p{P} | Lowercase p means property, which means Unicode property, and is used as a prefix for Unicode regular expressions. The "P" in the brackets represents one of the seven character attributes of the Unicode character set: punctuation characters. The other six attributes: L: letters; M: mark symbols (generally not appearing alone); Z: separators (such as spaces, newlines, etc.); S: symbols (such as mathematical symbols, currency symbols, etc.); N: numbers ( Such as Arabic numerals, Roman numerals, etc.); C: other characters. **Note: This syntax part of the language is not supported, for example: javascript. * |
| <> | Match the beginning (<) and end (>) of a word (word). For example, regular expression <the> It can match the "the" in the string "for the wise", but it cannot match the "the" in the string "otherwise". Note: This meta character is not supported by all software. |
| ( ) | Define the expression between (and) as a "group" (group), and save the characters that match this expression to a temporary area (a regular expression can save up to 9), they can use \1 to \9 to quote. |
Detailed re module###
There module is provided in python to deal with regular expression problems. Here are a few commonly used methods
re.match
re.match tries to match a pattern from the starting position of the string. If the matching is not successful at the starting position, match() returns none.
This method returns a regular matching object
Syntax
import re
re.match(pattern, string, flags=0)
Parameter Description#####
| Parameters | Description |
|---|---|
| pattern | matched regular expression |
| string | The string to match. |
| flags | Flags, used to control the matching mode of regular expressions, such as: case-sensitive, multi-line matching, etc. |
demo
- Get content through
group() - Get the range through
span()
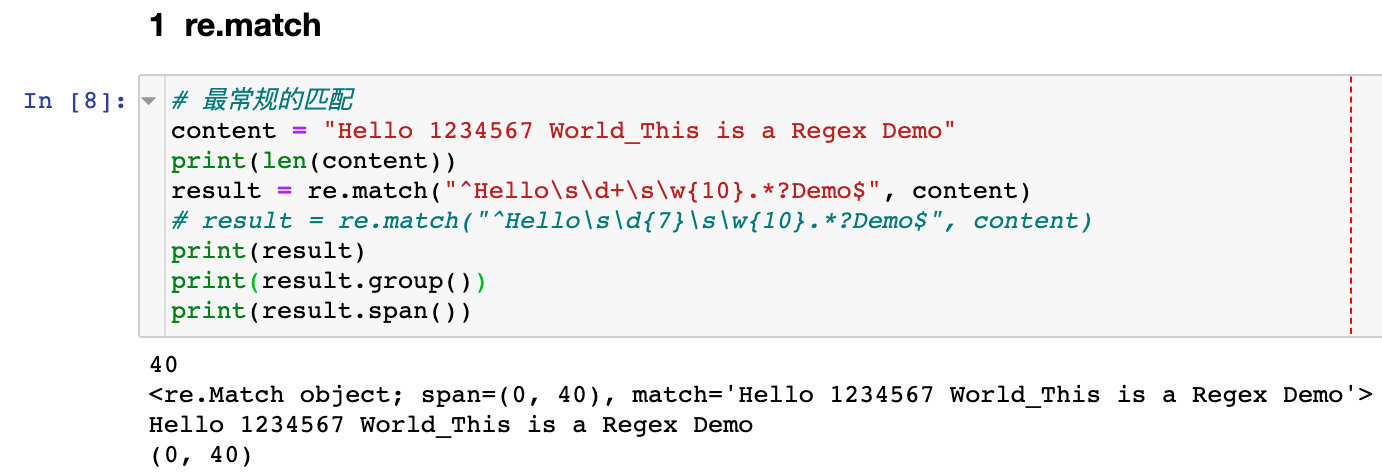
# Most regular match
content ="Hello 1234567 World_This is a Regex Demo"print(len(content))
result = re.match("^Hello\s\d+\s\w{10}.*?Demo$", content) #Must be matched from the starting position
# result = re.match("^Hello\s\d{7}\s\w{10}.*?Demo$", content)print(result)print(result.group())print(result.span())
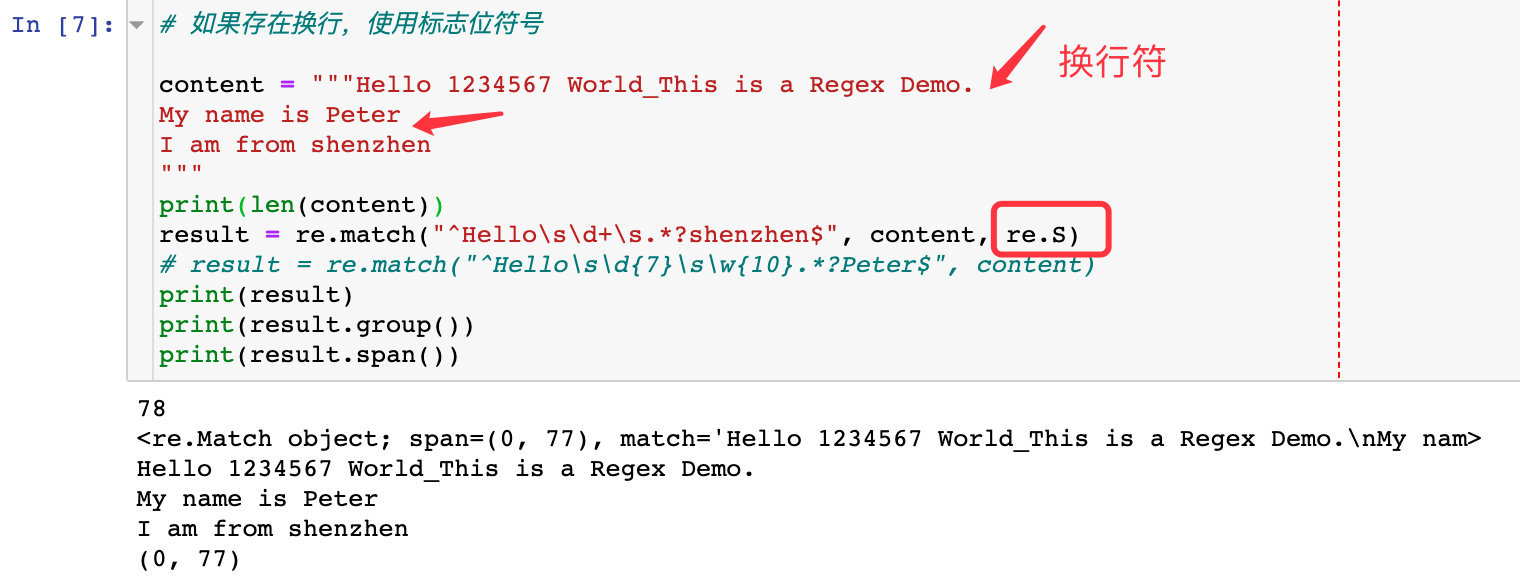
If there is a newline character, use the flag re.S
# If there is a newline, use the flag symbol
content ="""Hello 1234567 World_This is a Regex Demo.
My name is Peter
I am from shenzhen
"""
print(len(content))
result = re.match("^Hello\s\d+\s.*?shenzhen$", content, re.S)
# result = re.match("^Hello\s\d{7}\s\w{10}.*?Peter$", content)print(result)print(result.group())print(result.span())
line ="Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*?', line, re.M|re.I)if matchObj:print("matchObj.group() : ", matchObj.group()) #All content returned
print("matchObj.group(1) : ", matchObj.group(1)) #Return to the first()Content in
print("matchObj.group(2) : ", matchObj.group(2)) #2nd
else:print("No match!!")

re.matchUse as little as possible
re.matchUse as little as possible
re.matchUse as little as possible
re.search
re.search scans the entire string and returns the first successful match, otherwise it returns None. This method does not require starting from the starting position. Once the first content that meets the requirements is found, it will stop searching
You can use the group(num) or groups() matching object function to get the result of the matching expression.
Function syntax
re.search(pattern, string, flags=0)
Parameter Description#####
| Parameters | Description |
|---|---|
| pattern | matched regular expression |
| string | The string to match. |
| flags | Flags, used to control the matching mode of regular expressions, such as: case-sensitive, multi-line matching, etc. |
demo
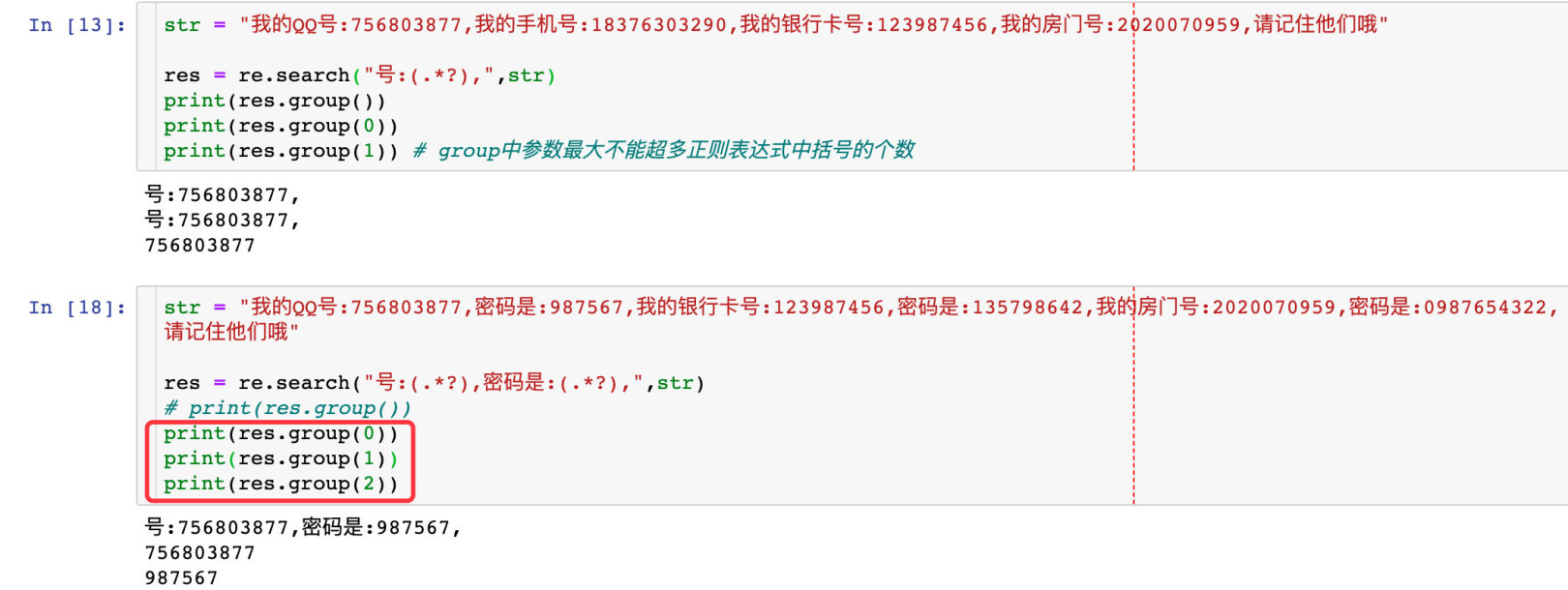
- Return the first element that matches successfully
- The parameters in the group() method cannot exceed the number of parentheses
re.findall
re.findall scans the entire string and returns all eligible elements in the form of list
grammar#####
findall(pattern, string, flags=0)
Parameter Description#####
| Parameters | Description |
|---|---|
| pattern | matched regular expression |
| string | The string to match. |
| flags | Flags, used to control the matching mode of regular expressions, such as: case-sensitive, multi-line matching, etc. |
demo
The result is in list form

If the extracted content contains multiple .*?, then the return is still in the form of a list, but the elements inside become a tuple form

re.sub
Use regular expressions to replace certain content in a string
grammar#####
re.sub(pattern, repl, string, count)
Parameter Description#####
The meanings of the parameters are:
- Regular expression
- Replaced content
- Raw string
- The number of replacements, the default is 0, replace all
demo



sub special processing####
re.sub allows special processing of matching items using functions


Two modes###
Two modes refer to: greedy mode and non-greedy mode
3 Symbols
We often use 3 symbols in regular expressions:
- Dot.: indicates that the match is any character except the newline character
- Question mark?: It means 0 or 1 match
- Asterisk*: means matching 0 or any characters
demo
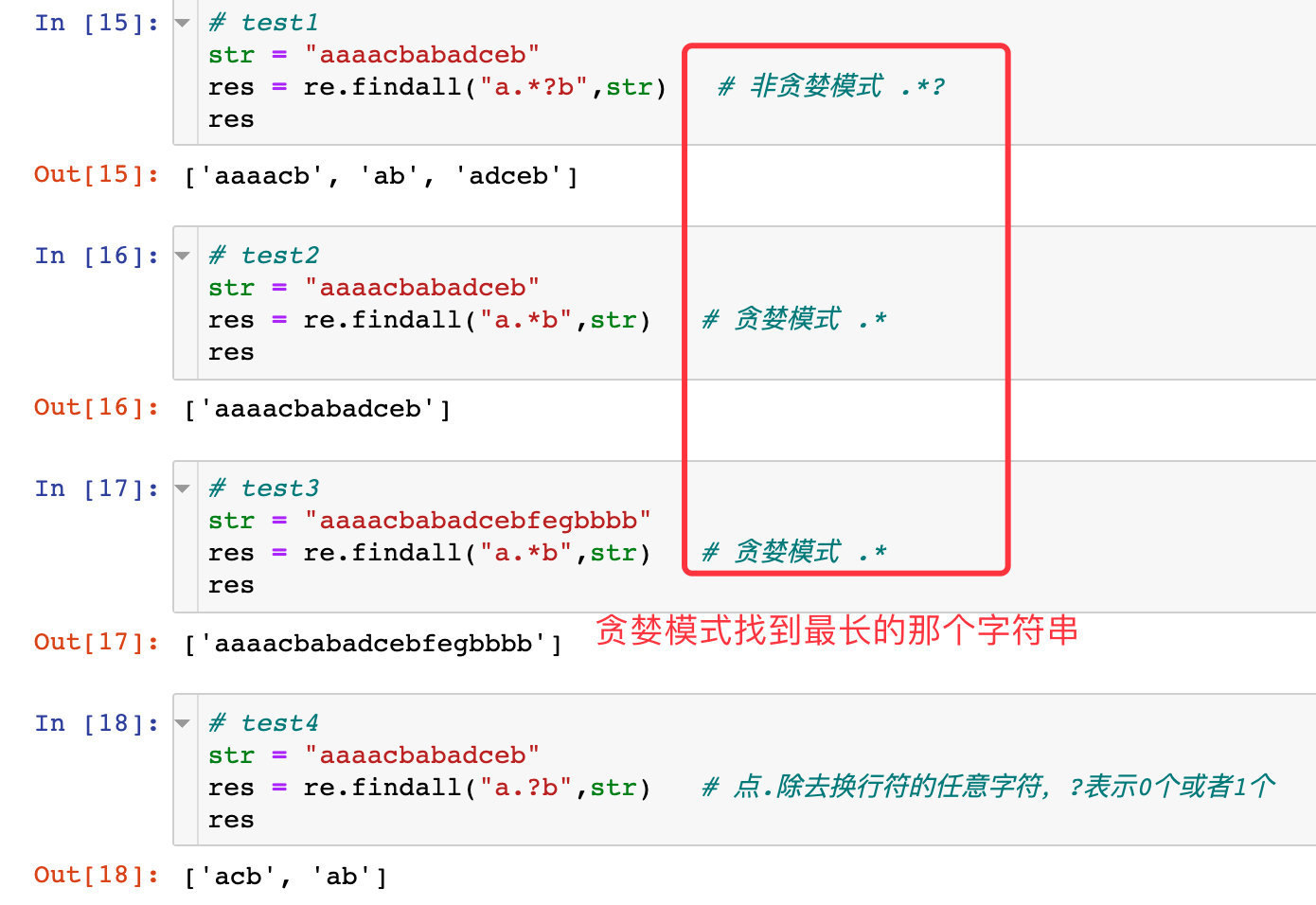
Explanation####
- In the non-greedy mode example above, the question mark is used? , Which means non-greedy mode, when it starts to match that
aaaacbhas met the requirements, the first one is found; then it starts to match again, it matchesab; it matches againadceb - In the greedy mode example, the program will find the longest string that meets the requirements
- In the last example,
.?is used, which means that there can only be 0 or 1 elements between ab, so there are only two cases in the result
Regex modifier-optional flag
Regular expressions can contain some optional flag modifiers to control the matching pattern. The modifier is specified as an optional flag. Multiple flags can be specified by bitwise OR (|) them. For example, re.I | re.M is set to I and M flags:
| Modifier | Description |
|---|---|
| re.I | Make matches case insensitive |
| re.L | Do locale-aware matching |
| re.M | Multi-line matching, affects ^ and $ |
| re.S | Make. match all characters including newline |
| re.U | Analyze characters according to the Unicode character set. This flag affects \w, \W, \b, \B. |
| re.X | This flag allows you to write regular expressions more easily by giving you a more flexible format. |
Regular expression example###
Character matching
| Example | Description |
|---|---|
| python | matches "python". |
Character class
| Example | Description |
|---|---|
| Ppython | Match "Python" or "python" Choose a letter from Pp to match |
| rubye | match "ruby" or "rube" ye choose one match |
| aeiou | Match any letter in the brackets Match a letter in aeiou |
| 0- 9 | Match any number. Similar to 0123456789 matches any number of digits |
| az | match any lowercase letter |
| AZ | matches any uppercase letter |
| a-zA-Z0-9 | Match any letter and number |
| ^ aeiou | All characters except aeiou letters ^ means inversion operation |
| ^0- 9 | Matches characters except digits |
Special character class
| Example | Description |
|---|---|
| . | Match any single character except "\n". To match any character including'\n', use a pattern like'.\n'. |
| \ d | matches a digit character. Equivalent to 0-9. |
| \ D | matches a non-digit character. Equivalent to ^0-9. |
| \ s | Matches any blank character, including spaces, tabs, form feeds, etc. Equivalent to \f\n\r\t\v. |
| \ S | matches any non-blank character. Equivalent to ^ \f\n\r\t\v. |
| \ w | matches any word character including the underscore. Equivalent to'A-Za-z0-9_'. |
| \ W | matches any non-word character. Equivalent to'^A-Za-z0-9_'. |
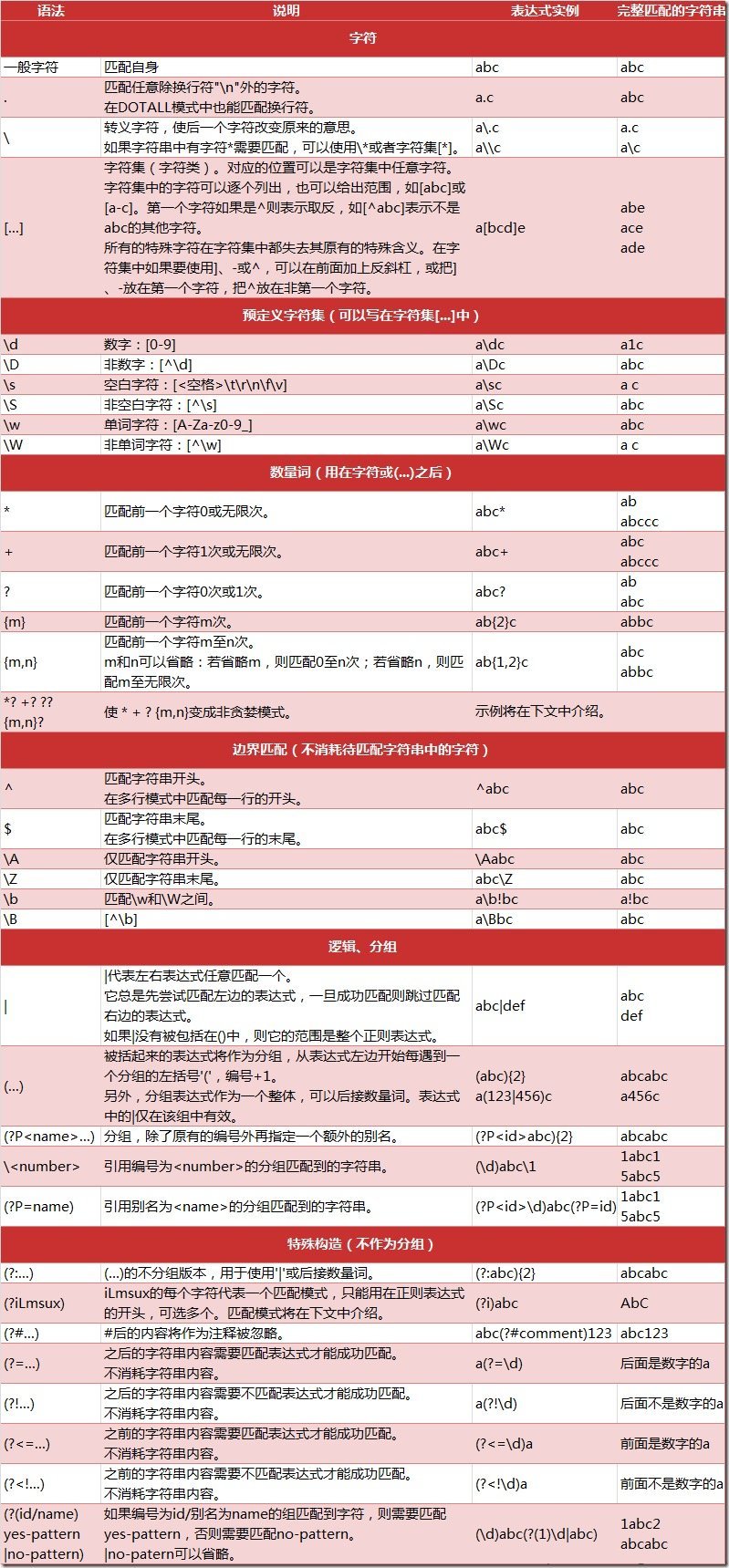
to sum up###
References
Novice Course-Regular Expression
Regular expression online test
[ Regular Expression Complete](https://blog.csdn.net/qq_28633249/article/details/77686976?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none- task-blog-BlogCommendFromMachineLearnPai2-1.nonecase)
Recommended Posts