How to use PYTHON to crawl news articles
In this article, we will discuss how to use Python to crawl news articles. This can be done using convenient newspaper packaging.
Introduction to Python newspaper package##
You can use pip to install the newspaper package:
pip install newspaper
After the installation is complete, you can start. The newspaper can work by grabbing an article from a given URL, or by finding links to other news on the web. Let's start by dealing with an article. First, we need to import the Article class. Next, we use this class to download content from the URL to our news article. Then, we use the parse method to parse the HTML. Finally, we can use .text to print the text of the article.
Climb an article###
from newspaper import Article
url ="https://www.bloomberg.com/news/articles/2020-08-01/apple-buys-startup-to-turn-iphones-into-payment-terminals?srnd=premium"
# download and parse article
article =Article(url)
article.download()
article.parse()
# print article text
print(article.text)
You can also get other information about the article, such as links to images or videos embedded in the post.
# get list of image links
article.images
# get list of videos - empty inthiscase
article.movies
Download all articles linked on the webpage###
Now, let's see how to link all news articles to the web page. We will use the following news.build method to achieve this. Then, we can use the article_urls method to extract the article URL.
import newspaper
site = newspaper.build("https://news.ycombinator.com/")
# get list of article URLs
site.article_urls()
Using the above objects, we can also get the content of each article. Here, all article objects are stored in list.site.articles. For example, let's get the content of the first article.
site_article = site.articles[0]
site_article.download()
site_article.parse()print(site_article.text)
Now, let's modify the code to get the top ten articles:
top_articles =[]for index inrange(10):
article = site.articles[index]
article.download()
article.parse()
top_articles.append(article)
caveat!
When using the newspaper, an important note is that if you run newspaper.build with the same URL multiple times,
The package will be cached and then deleted articles that have been scraped. For example, in the code below, we run Newspaper.build twice and get different results. When running it the second time, the code only returns the newly added link.
site = newspaper.build("https://news.ycombinator.com/")print(len(site.articles))
site = newspaper.build("https://news.ycombinator.com/")print(len(site.articles))
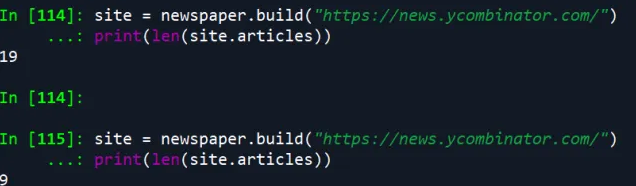
It can be adjusted by adding an extra parameter to the function call, as shown below:
site = newspaper.build("https://news.ycombinator.com/", memoize_articles=False)
How to get the article summary###
The newspaper package also supports some NLP functions. You can check by calling the nlp method.
article = top_articles[3]
article.nlp()
Now, let's use the summary method. This will try to return the article summary.
article.summary()
You can also get a list of keywords from the article.
article.keywords
How to get the most popular Google keywords###
The newspaper has some other cool features. For example, we can use the hot method to easily use it to attract the most popular searches on Google.
newspaper.hot()
The package can also return a list of popular URLs, as shown below.
newspaper.popular_urls()
Recommended Posts