Web Scraping with Python
I have been reading this book recently, because I have a need to learn English at the same time, so please translate it:
First of all, this book is about Python 3.X, and mainly talks about BeautifulSoup
Chapter Three, Start Crawling
The examples mentioned in the previous book are more than enough for crawling static single webpage data (like the webpage we made before for you to practice). In this chapter, we are going to start trying to crawl real web pages with multiple pages or even multiple sites.
Crawlers are called crawlers because they can crawl data across web pages. At their core are some cyclic units. These units download a page from a web site (URL), then find another web site from this web page, and then continue. Download web pages, and so on.
Note that although you can crawl the entire network, it certainly does not require such a large amount of work every time. The examples in the previous book can run very well on static single web pages, so you must carefully consider how to make your crawler work more efficiently when writing a crawler.
(It’s so tiring to translate verbatim, let’s flip through the general idea later^.^)
- First introduce how to crawl data in a domain:
The book gives an example of the game of "Six Degrees of Wikipedia" and "Six Degrees of Kevin Bacon". Looking at the tone, this thing seems to be very famous. I don't know what it is. Who knows to tell me about it. The rough meaning is that any two entries in the Wikipedia can be connected by words within six.
After that, I gave an example in the book. Forgive me for my ignorance, I don't know who the names are.
It is useless to say more, just go to the code, to play this game you first need to learn to find the link in the web page:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html)
for link in bsObj.findAll("a"):
if 'href' in link.attrs:
print(link.attrs['href'])
The reason why the findAll parameter is "a" is because after clicking on the web page to view the source code, you can see that the link to the entry is included in this structure (I guess it should be)
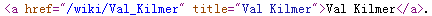
However, link.attrs in BeautifulSoup is a dictionary type. You can use link.attrs['href'] to call href, which is the value of the link address.
That's all for today, I found out that I didn't understand it as soon as I wrote it.
Recommended Posts