Python crawler example to get anime screenshots
introduction
I was a little boring before (I was really tired of staying at home), and then I went to station B to watch some python crawler videos, without basic theoretical learning, that is, I started the actual combat directly, and I felt that crawling was the same as memorizing the formula. Okay, at least I can climb something, hhh. I will share my crawler code today.
text
Not much to say, just go to the complete code
ps: There are some problems with this code. Every time I climb to the fate picture, it reports an error to me. I have to use a try to skip it. If anyone can help me find the error and correct it, I will be overwhelmed. grateful
import requests as r
import re
import os
import time
file_name ="Anime screenshots"if not os.path.exists(file_name):
os.mkdir(file_name)for p inrange(1,34):print("--------------------Crawling{}Page content------------------".format(p))
url ='https://www.acgimage.com/shot/recommend?page={}'.format(p)
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
resp = r.get(url, headers=headers)
html = resp.text
images = re.findall('data-original="(.*?)" ', html)
names =re.findall('title="(.*?)"', html)
# print(images)
# print(names)
dic =dict(zip(images, names))for image in images:
time.sleep(1)print(image, dic[image])
name = dic[image]
# name = image.split('/')[-1]
i = r.get(image, headers=headers).content
try:withopen(file_name +'/'+ name +'.jpg','wb')as f:
f.write(i)
except FileNotFoundError:continue
First import the library to be used
import requests as r
import re
import os
import time
Then analyze the URL to be crawled: https://www.acgimage.com/shot/recommend
The following picture is the content of the URL:
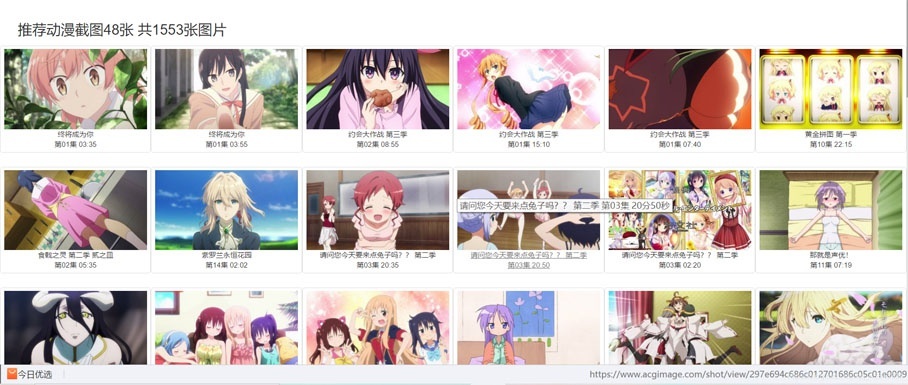
Ok the url has been determined
Let's find headers
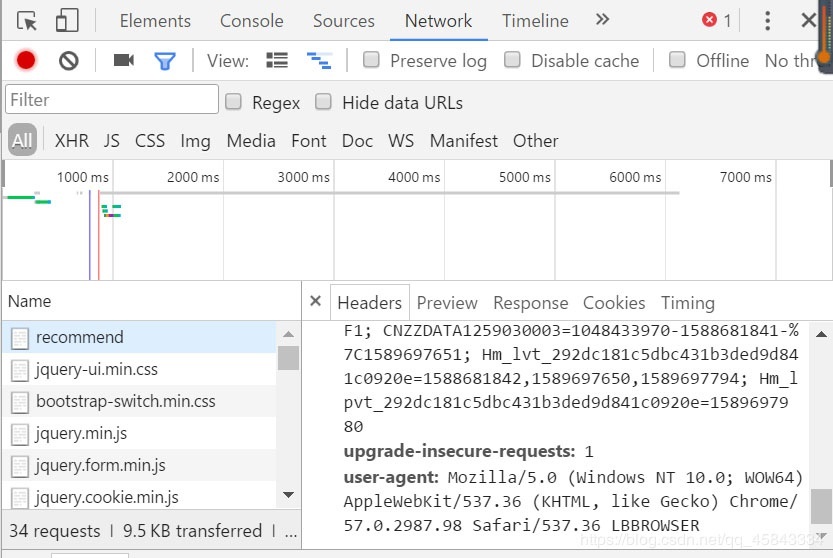
Find user-agent and copy its content to headers
The first step is complete
Below is the code display
url ='https://www.acgimage.com/shot/recommend?page={}'.format(p)
headers ={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36"}
Then retrieve the content of the image to be crawled

You can find the location of the picture from the picture above: data-origina=below
And the name of the picture: title=below content
Then use the regular expression re to retrieve it
images = re.findall('data-original="(.*?)" ', html)
names =re.findall('title="(.*?)"', html)
Just save it at last
i = r.get(image, headers=headers).content
withopen(file_name +'/'+ name +'.jpg','wb')as f:
f.write(i)
There are some details
Like change page
First page URL:
https://www.acgimage.com/shot/recommend
The second page URL: https://www.acgimage.com/shot/recommend?page=2
Then change the number behind the page to jump to the corresponding page
The problem of page change is solved
or p inrange(1,34):
url ='https://www.acgimage.com/shot/recommend?page={}'.format(p)
And put the crawled pictures into the file you created
Os library used
file_name ="Anime screenshots"if not os.path.exists(file_name):
os.mkdir(file_name)
And in order not to affect the crawled website, the sleep function is used
Although the crawling speed is slower
But this is the morality to be observed
time.sleep(1)
The above is my crawling process
I still hope that the boss can solve my mistakes
Many thanks
to sum up
This is the end of this article on how to obtain anime screenshots of python crawlers. For more related python crawlers to obtain animation screenshots, please search ZaLou.Cn
Recommended Posts