Centos7でのCeph展開の簡潔な要約
最近、Cephを勉強し、いくつかの環境を展開する必要があります。この記事は、概念の紹介のための第1章、2章、3章、および4章と、実践のための第5章に分かれています。
1 セフの基本的な紹介
Cephは、信頼性が高く、自動リバランス、自動リカバリの分散ストレージシステムです。シナリオによると、Cephは、[オブジェクトストレージ](https://cloud.tencent.com/product/cos?from=10680)、ブロックデバイスストレージ、ファイルシステムサービスの3つの主要部分に分けることができます。仮想化の分野では、Cephブロックデバイスストレージがより一般的に使用されます。たとえば、OpenStackプロジェクトでは、CephブロックデバイスストレージをOpenStackのcinderバックエンドストレージ、Glanceイメージストレージ、およびより直感的な仮想マシンデータストレージに接続できます。 Cephクラスターは、仮想マシンインスタンスのハードディスクとしてraw形式のブロックストレージを提供できます。
他のストレージに対するCephの利点は、ストレージであるだけでなく、ストレージノードの計算能力を最大限に活用することです。各データを保存するときに、データストレージの場所を計算し、データ分散のバランスをとろうとします。同時に、Cephの優れた設計により、CRUSHアルゴリズム、HASHリングなどの方法が使用されているため、従来の単一の障害点の問題が発生せず、スケールが拡大してもパフォーマンスに影響はありません。
2 セフコアコンポーネント
Cephのコアコンポーネントには、Ceph OSD、Ceph Monitor、およびCephMDSが含まれます。
**Ceph OSD **:OSDの完全な英語名はObject Storage Deviceです。その主な機能は、データの保存、データのコピー、データのバランス調整、データの復元など、他のOSDとのハートビートチェックの実行、およびCephMonitorへの変更の報告です。 。通常、ハードディスクはOSDに対応し、ハードディスクのストレージはOSDによって管理されます。もちろん、パーティションもOSDになることができます。
Ceph OSDのアーキテクチャは、物理ディスクドライブ、Linuxファイルシステム、およびCephOSDサービスで構成されています。CephOSDDeamonの場合、Linuxファイルシステムはそのスケーラビリティを明示的にサポートします。一般に、BTRFSなどのいくつかのLinuxファイルシステムがあります。 、XFS、Ext4など。BTRFSには多くの利点と機能がありますが、実稼働環境で必要な安定性にはまだ達していません。通常、XFSをお勧めします。
OSDにはジャーナルディスクと呼ばれる概念もあります。通常、Cephクラスターにデータを書き込む場合、データは最初にジャーナルディスクに書き込まれ、次にジャーナルディスクのデータがファイルシステムに時々(たとえば5秒)更新されます。に。一般に、読み取りと書き込みの待ち時間を短くするために、ジャーナルディスクはSSDを使用し、通常は10G以上を割り当てます。もちろん、より多くのポイントを割り当てることをお勧めします。ジャーナルではCeph OSD機能をすばやく小さくできるため、ジャーナルディスクの概念がCephに導入されました。書き込み操作。ランダム書き込みは、最初に前の連続ジャーナルに書き込まれ、次にファイルシステムにフラッシュされます。これにより、ファイルシステムにマージしてディスクに書き込むための十分な時間が与えられます。一般に、OSDジャーナルとしてSSDを使用すると、効果的にバッファリングできます。バースト負荷。
**Ceph Monitor **:英語名から、Cephクラスターの監視、Cephクラスターの状態の維持、およびOSDマップ、モニターマップ、PGなどのCephクラスター内のさまざまなマップマップの維持を担当するモニターであることがわかります。マップとクラッシュマップ。これらのマップはまとめてクラスターマップと呼ばれます。クラスターマップはRADOSの主要なデータ構造であり、クラスター内のすべてのメンバー、関係、属性、その他の情報、およびデータの配布を管理します。たとえば、ユーザーがCephクラスターにデータを保存する必要がある場合、OSD最初にモニターから最新のマップを取得してから、マップとオブジェクトIDに基づいてデータの最終的な保存場所を計算する必要があります。
**Ceph MDS **:フルネームはCeph MetaData Serverで、主にファイルシステムサービスのメタデータを保存しますが、オブジェクトストレージおよびブロックストレージデバイスはこのサービスを使用する必要はありません。
さまざまなマップの情報を表示するには、次のコマンドを使用できます。cephosd(mon、pg)dump
3 Cephインフラストラクチャコンポーネント
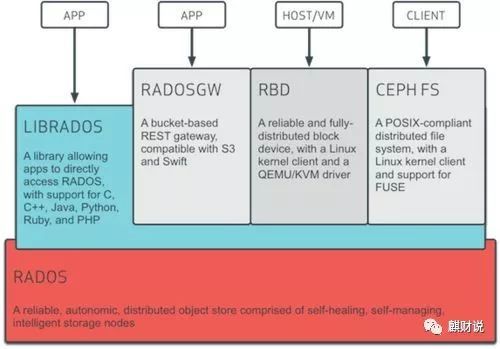
アーキテクチャ図から、最下層がRADOSであることがわかります。RADOS自体は完全な分散オブジェクトストレージシステムであり、信頼性、インテリジェンス、および分散の特性を備えています。Cephは信頼性が高く、拡張性が高く、パフォーマンスが高く、高度に自動化されています。すべてがこのレイヤーによって提供され、ユーザーデータのストレージは最終的にこのレイヤーを介して保存されます。RADOSはCephのコアであると言えます。
RADOSシステムは、主にOSDとモニターの2つの部分で構成されています。
RADOSレイヤーに基づく上位レイヤーはLIBRADOSです。LIBRADOSは、アプリケーションがライブラリにアクセスすることでRADOSシステムと対話できるようにするライブラリであり、C、C ++、Pythonなどの複数のプログラミング言語をサポートします。
LIBRADOSレイヤーの開発に基づいて、RADOSGW、RBD、CEPHFSの3つのレイヤーがあることがわかります。
RADOSGW:RADOSGWは、現在人気のあるRESTFULプロトコルに基づくゲートウェイのセットであり、S3およびSwiftと互換性があります。
RBD:RBDは、LinuxカーネルクライアントとQEMU / KVMドライバーを介して分散ブロックデバイスを提供します。
CEPH FS:CEPH FSは、LinuxカーネルクライアントとFUSEを介してPOSIX互換のファイルシステムを提供します。
4 CephStorageの概要
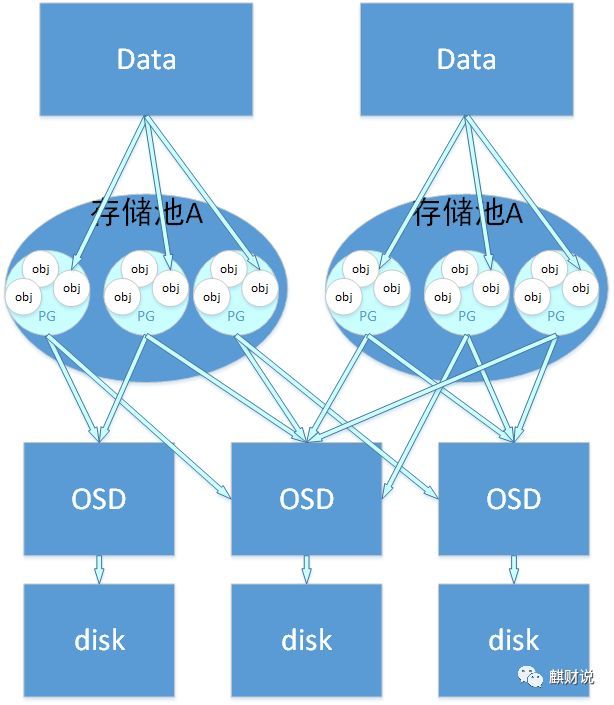
保存されたデータとオブジェクトの関係:ユーザーがCephクラスターにデータを保存したい場合、保存されたデータは複数のオブジェクトに分割されます。各オブジェクトにはオブジェクトIDがあります。各オブジェクトのサイズを設定できます。デフォルトは4MBです。 、オブジェクトは、Cephストレージの最小ストレージユニットと見なすことができます。
オブジェクトとpgの関係:オブジェクトの数が多いため、Cephはオブジェクトを管理するためにpgの概念を導入します。各オブジェクトは最終的にCRUSH計算によって特定のpgにマップされ、1つのpgに複数のオブジェクトを含めることができます。
実験による要約:
(1)PGは、ストレージプールストレージオブジェクトを指定するディレクトリの数であり、PGPは、ストレージプールPGのOSD配布の組み合わせの数です。
(2)PGの増加により、PG内のデータが分割され、同じOSD上で新しく生成されたPG間で分割されます。
(3)PGPの増加により、一部のPGの分布が変化しますが、PG内のオブジェクトは変化しません。
pgとpool:poolの関係も論理的なストレージの概念です。ストレージプールを作成するときは、pgとpgpの数を指定する必要があります。論理的には、オブジェクトが特定のストレージプールに属するのと同じように、pgはストレージプールに属します。 pg。
次の図は、ストレージデータ、オブジェクト、pg、プール、osd、およびストレージディスクの関係を示しています。
- 注:上記は引用された記事です1 *
5 デプロイ
環境への準備
すべてのサーバーがcentos7をインストールします.5192.168.3.8 ceph-admin(ceph-デプロイ)mds1、mon1(monitノードを別のマシンに配置することもできます)
192.168.3.7 ceph-node1 osd1
192.168.3.6 ceph-node2 osd2
-------------------------------------------------
各ノードのホスト名を変更します
# hostnamectl set-hostname ceph-admin
# hostnamectl set-hostname ceph-node1
# hostnamectl set-hostname ceph-node2
-------------------------------------------------
各ノードバインディングのホスト名マッピング
# cat /etc/hosts
192.168.3.8 ceph-admin
192.168.3.7 ceph-node1
192.168.3.6 ceph-node2
-------------------------------------------------
各ノードは接続を確認します
# ping -c 3 ceph-admin
# ping -c 3 ceph-node1
# ping -c 3 ceph-node2
-------------------------------------------------
各ノードでファイアウォールとselinuxをオフにします
# systemctl stop firewalld
# systemctl disable firewalld
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g'/etc/selinux/config
# setenforce 0-------------------------------------------------
各ノードにNTPをインストールして構成します(公式の推奨事項は、クラスター内のすべてのノードにNTPをインストールして構成することです。各ノードのシステム時間が一貫していることを確認する必要があります。独自のntpサーバーを展開しない場合は、NTPをオンラインで同期してください)
# yum install ntp ntpdate ntp-doc -y
# systemctl restart ntpd
# systemctl status ntpd
-------------------------------------------------
各ノードのyumソースを準備します
デフォルトのソースを削除します。外部のソースは遅くなります
# yum clean all
# mkdir /mnt/bak
# mv /etc/yum.repos.d/* /mnt/bak/
アリババクラウドのベースソースとepelソースをダウンロードする
# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
セフソースを追加
# vim /etc/yum.repos.d/ceph.repo
[ ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
gpgcheck=0
priority =1
[ ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
gpgcheck=0
priority =1
[ ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS
gpgcheck=0
priority=1
------------------------------------------------------------
ノードごとにcephuserユーザーを作成し、sudo権限を設定します
# useradd -d /home/cephuser -m cephuser
# echo "cephuser"|passwd --stdin cephuser
# echo "cephuser ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephuser
# chmod 0440 /etc/sudoers.d/cephuser
# sed -i s'/Defaults requiretty/#Defaults requiretty'/g /etc/sudoers
cephuserのsudo権限をテストします
# su - cephuser
$ sudo su -
#
------------------------------------------------------------
相互のssh信頼関係を構成する
今セフ-公開鍵ファイルと秘密鍵ファイルは管理ノードで生成され、次にceph-管理ノード.sshディレクトリを他のノードにコピーします
[ root@ceph-admin ~]# su - cephuser
[ cephuser@ceph-admin ~]$ ssh-keygen -t rsa #キャリッジリターンはずっと
[ cephuser@ceph-admin ~]$ cd .ssh/
[ cephuser@ceph-admin .ssh]$ ls
id_rsa id_rsa.pub
[ cephuser@ceph-admin .ssh]$ cp id_rsa.pub authorized_keys
[ cephuser@ceph-admin .ssh]$ scp -r /home/cephuser/.ssh ceph-node1:/home/cephuser/
[ cephuser@ceph-admin .ssh]$ scp -r /home/cephuser/.ssh ceph-node2:/home/cephuser/
次に、各ノードのcephuserユーザーの下でsshの相互信頼関係を直接確認します。
$ ssh -p22 cephuser@ceph-admin
$ ssh -p22 cephuser@ceph-node1
$ ssh -p22 cephuser@ceph-node2
[ root@ceph-admin ~]# su - cephuser
cephをインストールします-deploy
[ cephuser@ceph-admin ~]$ sudo yum update -y && sudo yum install ceph-deploy -y
クラスターディレクトリを作成する
[ cephuser@ceph-admin ~]$ mkdir cluster
[ cephuser@ceph-admin ~]$ cd cluster/[cephuser@ceph-admin cluster]$ ceph-deploy newceph-admin ceph-node1 ceph-node2
[ cephuser@ceph-admin cluster]$ vim ceph.conf
次のコンテンツを構成ファイルに追加します
osd pool default size =2
mon_clock_drift_allowed =1[cephuser@ceph-admin cluster]$ ceph-deploy install --release=luminous ceph-admin ceph-node1 ceph-node2
監視ノードを初期化し、すべてのキーを収集します
[ cephuser@ceph-admin cluster]$ ceph-deploy mon create-initial
[ cephuser@ceph-admin cluster]$ ceph-deploy gatherkeys ceph-admin
クラスターにOSDを追加する
OSDノードで使用可能なすべてのディスクを確認します
[ cephuser@ceph-admin cluster]$ ceph-deploy disk list ceph-node1 ceph-node2
[ cephuser@ceph-admin ~]$ ssh ceph-node1 "sudo mkdir /var/local/osd0 && sudo chown ceph:ceph /var/local/osd0"[cephuser@ceph-admin ~]$ ssh ceph-node2 "sudo mkdir /var/local/osd1 && sudo chown ceph:ceph /var/local/osd1"[cephuser@ceph-admin ~]$ ceph-deploy osd prepare ceph-node1:/var/local/osd0 ceph-node2:/var/local/osd1
[ cephuser@ceph-admin ~]$ ceph-deploy osd activate ceph-node1:/var/local/osd0 ceph-node2:/var/local/osd1
構成を更新する
[ cephuser@ceph-admin ~]$ ceph-deploy admin ceph-admin ceph-node1 ceph-node2
[ cephuser@ceph-admin ~]$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
[ cephuser@ceph-admin ~]$ ssh ceph-node1 sudo chmod +r /etc/ceph/ceph.client.admin.keyring
[ cephuser@ceph-admin ~]$ ssh ceph-node2 sudo chmod +r /etc/ceph/ceph.client.admin.keyring
テスト
サービスステータス
[ cephuser@ceph-admin ~]$ ceph health
HEALTH_OK
[ cephuser@ceph-admin ~]$ ceph -s
cluster 50fcb154-c784-498e-9045-83838bc3018e
health HEALTH_OK
monmap e1:3 mons at {ceph-admin=192.16.3.8:6789/0,ceph-node1=192.16.3.7:6789/0,ceph-node2=192.16.3.6:6789/0}
election epoch 4, quorum 0,1,2 ceph-node2,ceph-node1,ceph-admin
osdmap e12:2 osds:2 up,2in
flags sortbitwise,require_jewel_osds
pgmap v624:64 pgs,1 pools,136 MB data,47 objects
20113 MB used,82236 MB /102350 MB avail
64 active+clean
マウントテスト
[ cephuser@ceph-admin ~]$ sudo rbd create foo --size 4096-m ceph-node1
[ cephuser@ceph-admin ~]$ sudo rbd map foo --pool rbd --name client.admin -m ceph-node1
[ cephuser@ceph-admin ~]$ sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo
[ cephuser@ceph-admin ~]$ sudo mkdir /mnt/ceph-block-device
[ cephuser@ceph-admin ~]$ sudo mount /dev/rbd/rbd/foo /mnt/ceph-block-device
これで基本的な環境がセットアップされましたが、それを構成したい場合は、まだいくつかの方法があります。
環境に子供用の靴がない場合は、vagrantを使用してシミュレートすることを検討できます。参考資料2の接続は、非常に使いやすいvagrantプロジェクトです。
参考資料:
Recommended Posts