CentOS6.5でのHadoop環境の構築に関する詳細な説明
この記事では、開発サーバーCentOS6.5でHadoopを構築する詳細なプロセスについて詳しく説明します。
SSH接続のパスワードなしの構成
構成プロセスでは、コマンドを実行し、scpコマンドを介してファイルをサーバーにコピーするために、開発サーバーへの頻繁なssh接続が必要になるため、ssh接続に依存する操作。したがって、ローカル環境とサーバーの間にSSHパスワードなしの接続を構成すると、作業効率を効果的に向上させることができます。
私のマシンはすでに公開鍵を生成しているので、既存の公開鍵をサーバーにコピーするだけで済みます。シンプルでエラーのないssh-copy-idコマンドを使用することをお勧めします。公開鍵ファイルの末尾を手動でコピーしてから追加すると、操作上の問題により公開鍵を正しく識別できなくなることがよくあります。
注:公開鍵を生成していない場合は、ssh-keygenコマンドを使用して公開鍵を生成できます。デフォルトの構成に従ってください。
私のMacでは、ssh-copy-idコマンドはまだインストールされていません。 brewコマンドでインストールできます。
brew install ssh-copy-id
次に、公開鍵を指定されたホストにコピーします
ssh-copy-id [email protected]
その中で、root @ 172.20.2.14はアクセスする必要のあるサーバーのusername @ IPに変更されます。プロンプトが表示されたら、パスワードを1回入力します。成功すると、すべてのsshベースのコマンドは、ユーザー名@IPを使用してサーバーに直接アクセスするだけで済みます。
新規ユーザー、ユーザーグループの作成
アクセス許可をより適切に制御し、適切なLinuxの使用習慣を開発するために、最初にユーザー(グループ)dps-hadoopを作成して、hadoopクラスターを管理および使用します。これは、Hadoopクラスター管理に必要な環境構成でもあります。
groupadd dps-hadoop
useradd -d /home/dps-hadoop -g dps-hadoop dps-hadoop
特権をエスカレートするためにsudoを使用する必然的な必要性を考慮して、ユーザーをsudoリストに構成し、/ etc / sudoersファイルを変更します。
vim /etc/sudoers
新しいレコードを追加します。
dps-hadoop ALL=(ALL) ALL
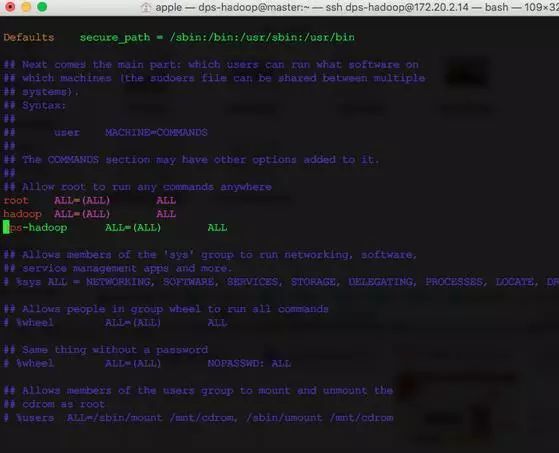
それ以来、私たちは皆、dps-hadoopユーザーを使用して操作しています。
ローカルDNSサーバーを構成する
先ほど、Dockerを使用してローカルDNSサーバーを構築する方法を紹介しました。これはついに便利になります。ローカルDNSサーバーがない場合は、/ etc / hostsファイルを変更することもできます。 CentOSの場合、一時的に有効な構成ファイルは次のとおりです。
/etc/resolv.conf
ファイルの先頭に、ファイルが自動的に生成されるというプロンプトが表示されます。ネットワークサービスを再起動すると、永続的な構成の変更がカバーされます
/etc/sysconfig/network-scripts/ifcfg-eth0
を変更します
DNS1=172.20.2.24
その中で、ifcfg-eth0は、独自のネットワークカード名に変更するだけです。
JDKをインストールする
HadoopはJavaで開発されており、実行するには当然jreに依存する必要があります。書籍を比較する方法を採用しましたが、Oracleの公式ウェブサイトでjdk-8u77をローカルにダウンロードし、scpコマンドを使用してサーバーにコピーします。 jdkが配置されているフォルダーを入力して実行します
scp jdk-8u77-linux-x64.rpm [email protected]:~/download
実際、wgetからダウンロードできますが、コマンドはインターネット上で提供されます
wget --no-cookie --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F" http://download.oracle.com/otn-pub/java/jdk/7u10-b18/jdk-7u10-linux-i586.rpm
何度も試しましたが成功しませんでした。私には愚かな方法があります。それは、ブラウザからダウンロードを取得して、実際のダウンロードアドレスを取得することです。

次に、wget経由でダウンロードします。
wget http://download.oracle.com/otn-pub/java/jdk/8u77-b03/jdk-8u77-linux-x64.rpm?AuthParam=1460511903_6b2f8345927b3fc4f961fbcaba6a01b3
ダウンロード後、冗長な?AuthParamサフィックスを削除するために、名前を1回変更する必要がある場合があります。
mv jdk-8u77-linux-x64.rpm?AuthParam=1460511903_6b2f8345927b3fc4f961fbcaba6a01b3 jdk-8u77-linux-x64.rpm
最後に、jdkをインストールします
rpm -i jdk-8u77-linux-x64.rpm
JAVA_HOMEを構成します
dps-hadoopユーザーの環境変数構成ファイルを変更します。
vim ~/.bashrc
注:インターネットで言及されている環境変数を構成する方法はたくさんあります。失礼な方法は、/ etc / environmentや/ etc / profileなどのグローバル構成ファイルで直接構成することです。これは、すべてのユーザーに有効になります。この方法はお勧めしません。ユーザーレベルの変数には、2つの〜/ .bash_profileと〜/ .bashrcもあります。違いを自分で調べてください。 start-dfs.shなどのスクリプトを実行してHadoopクラスターをリモートで開始および停止する場合は、〜/ .bashrcで構成してください。そうしないと、Hadoopは構成した環境変数を検出できません。
例:エラー:JAVA_HOMEが設定されておらず、見つかりませんでした。
追加
export JAVA_HOME="/usr/java/jdk1.8.0_77"
これはすべてのユーザーに有効になるため、/ etc / environmentで構成することはお勧めしません。
Hadoop2.6.4をインストールします
公式ウェブサイトによると、Hadoopプロジェクトには実際には次のモジュールが含まれています。
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
まず、ミラーステーションからwgetを介して直接ダウンロードします。
wget http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
ユーザーディレクトリに解凍します
tar -xvzf hadoop-2.6.4.tar.gz -C ~/
HADOOP_HOMEを構成し、〜/ .bashrcファイルも変更します。増加する
export HADOOP_HOME="/home/dps-hadoop/hadoop-2.6.4"
他のノードで上記のすべての構成操作を繰り返します。
ユーザーを追加する
マスターから各スレーブノードまでのdps-hadoopユーザーを構成します。sshパスワードなしのアクセス。
DNSサーバーアドレスを変更する
JDKをインストールする
Hadoopをダウンロードして解凍します
Hadoop環境変数を構成する
クラスターを構成する
モジュールの観点から、hadoopクラスターの構成には、HDFS、YARN、およびMapReduceの3つの部分を含める必要があります。
HDFS構成
チューニングに関係なく、関数が実行できることは関数からのみ理解されます。HDFS構成では、namenodeとdatanodeのIP番号とポート番号をそれぞれ構成する必要があります。データバックアップコピーの数。データストレージアドレス。したがって、構成は次のとおりです。
namenode
core-site.xml
< configuration>
< property>
< name>hadoop.tmp.dir
< value>/home/dps-hadoop/tmpdata
< /property>
< property>
< name>fs.default.name
< value>hdfs://master:54000/
< /property>
hdfs-site.xml
< configuration>
< property>
< name>dfs.namenode.name.dir
< value>/home/dps-hadoop//namedata
< /property>
< property>
< name>dfs.replication
< value>2
< /property>
Datanode
core-site.xml
< configuration>
< property>
< name>hadoop.tmp.dir
< value>/home/dps-hadoop/tmpdata
< /property>
< property>
< name>fs.default.name
< value>hdfs://master:54000/
< /property>
hdfs-site.xml
< configuration>
< property>
< name>dfs.datanode.data.dir
< value>/home/dps-hadoop/datadir
< /property>
core-site.xmlには、これまで言及していないhadoop.tmp.dirの構成のみがあります。この構成は、一時ファイルのストレージパスを変更して、システムの再起動による一時ファイルの損失を回避するためのものです。これにより、クラスターが使用できなくなる可能性があります。
2016- 04- 28 注意:
< property>
< name>fs.default.name
< value>hdfs://master:54000/
< /property>
この構成は、core-site.xml構成ファイルで構成する必要があります。以前の構成は間違っています。それ以外の場合、各hdfsノードはクラスター内にありません。
HDFSクラスターを開始します
ハードディスクを使用するのと同じように、HDFSも使用前にフォーマットする必要があります
bin/hdfs namenode -format
次に開始します
sbin/start-dfs.sh
コンソールから、HDFSクラスターのステータスを表示できます
http://172.20.2.14:50070/
エピソード
起動中にWARNログが見つかりました。
16 /04/19 13:59:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
ローカルライブラリを読み込めません。スタックオーバーフローに関する回答から判断すると、主に3つの可能性があります。
java.library.path環境変数が指定されていません。
ローカルライブラリはシステムと互換性がありません。 (64ビットシステム、32ビットネイティブライブラリが提供されます)
GLIBCバージョンは互換性がありません
fileコマンドで表示
file lib/native/*
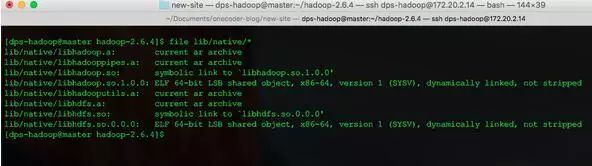
すでに64ビットのネイティブライブラリです。
log4j.propertiesを変更して、ローカルにロードされたデバッグレベルを開きます
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=DEBUG
もう一度やり直して問題を見つけてください
16 /04/19 14:27:00 DEBUG util.NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: /home/dps-hadoop/hadoop-2.6.4/lib/native/libhadoop.so.1.0.0: /lib64/libc.so.6: version `GLIBC_2.14’ not found (required by /home/dps-hadoop/hadoop-2.6.4/lib/native/libhadoop.so.1.0.0)
沿って
ldd --version
ローカル環境のバージョンは2.12であることがわかりました。これは、システムバージョンをアップグレードせずに解決するのは困難です。ログをERRORに変更してください。今のところ、ログが表示されたり心配したりすることはありません。
YARN構成
YARNでは、マスターノードはResourceManagerと呼ばれ、スレーブノードはNodeManagerと呼ばれます。理解によると、NodeManagerとResouceManagerの通信アドレスを通知する必要があります。 ResourceManagerの場合、すべてのスレーブノードがスレーブで構成されています。したがって、構成は次のとおりです。
NodeManager
yarn-site.xml
< configuration>
< property>
< name>yarn.resourcemanager.hostname
< value>master
< /property>
糸を開始し、マスターノードが実行します
. sbin/start-yarn.sh
MapReduce JobHistoryServer
MapReduceの場合、デフォルトでは特別な構成は必要ありません。 Hadoopは、タスクの実行履歴を管理するサービスJobHistoryServerを提供します。オンデマンドで開始するだけです。
mr-jobhistory-daemon.sh stop historyserver
この時点で、基本的なHadoopクラスターが開始されています。
クラスター管理環境のWebUIアドレス
デフォルトでは、Hadoopは、マスターノードで開始されるクラスターステータスを表示するためのWebサービスを提供します。デフォルトのポートは次のとおりです。
HDFSクラスター管理。デフォルトのポートは50070です。 http:// master:50070 /
ResourceManager管理、デフォルトポート8088 http:// master:8088 /
JobHistoryのデフォルトポート19888http:// master:19888
Recommended Posts