ubuntuでhanlpを使用する方法
序文
以前は、ほとんどの中国の単語セグメンテーションにpythonの途切れ途切れの単語セグメンテーションツールを使用していました。単語セグメンテーションツールはAPIをオンラインで呼び出すことです。この単語セグメンテーションツールの原理については、良いブログをお勧めします。
http://blog.csdn.net/daniel_ustc/article/details/48195287.
プロジェクトのニーズに応じて、スタンフォード大学の自然言語処理パッケージstandfordを使用して依存関係ツリーを構築する必要がありますが、Standfordは、中国語の単語のセグメンテーションを実行させないように非常にいたずらをしています(古いエラー)。必死になって、私はサードパーティの単語セグメンテーションツールしか使用できません。 Standfordのソースコードはjavaであるため、対応する単語セグメンテーションツール、つまりhanlpを見つけました。
HanLPのインストールと使用
HanLPの大きなメリットの1つは、オフラインのオープンソースツールキットです。つまり、無料でダウンロードできる無料のコードを提供するだけでなく、収集した辞書を公開することもできます。これは無私の行動です。私がインストールするとき、私は主にこのブログを参照します:
http://m.blog.csdn.net/article/details?id=50938796
ただし、このブログでは主にWindowsでのhanlpの使用方法を紹介しており、ubuntuはlinuxであるため、違いがあります。以下では、主にunbuntuのインストールと使用法を紹介します。
Eclipseをインストールする
ターミナルにsudoget-apt install eclipse-platformと入力してワンクリックインストールを実行し、アプリケーションでeclipseを見つけます
hanlpをダウンロード
hanlpの公式ウェブサイトにアクセスしてください:http://hanlp.linrunsoft.com/services.html
hanlp.jar(プログラムパッケージ)、data.zip(辞書ライブラリ)、hanlp.properties(構成ファイル)をダウンロードします。以下はドキュメントです。ダウンロードする必要はありません。
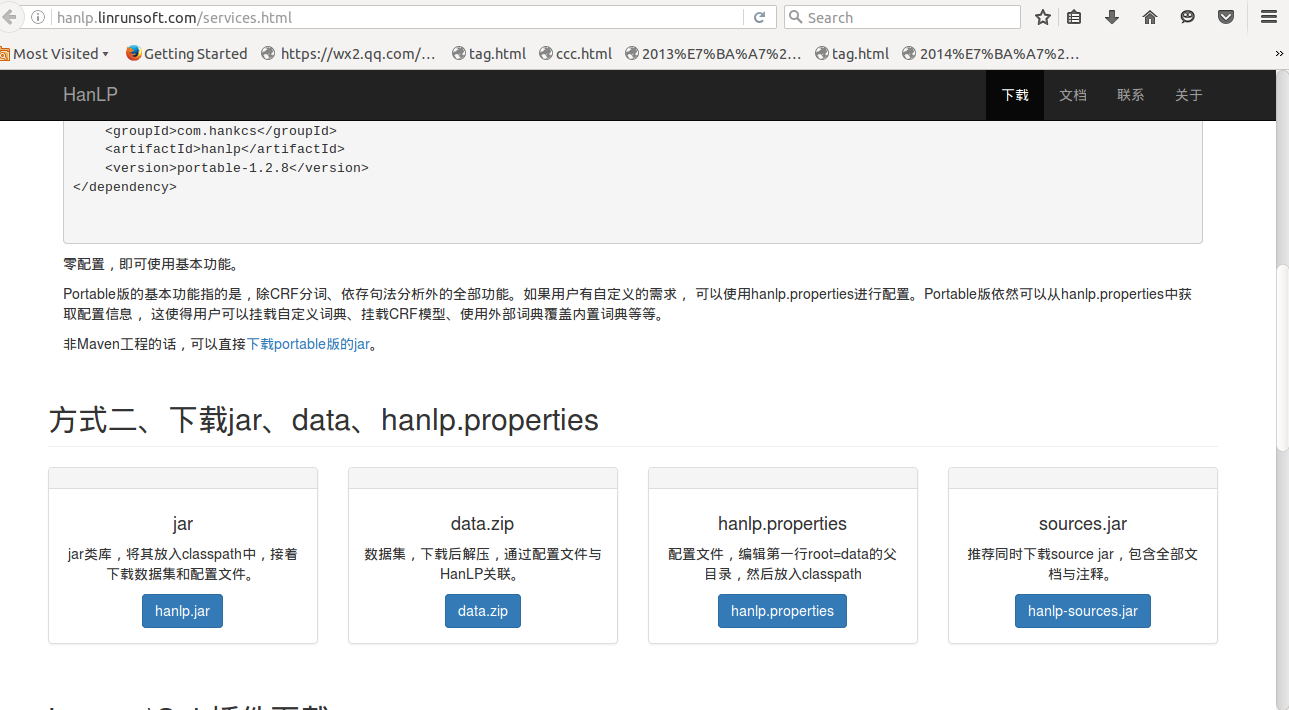
data.zipをダウンロードするとき、ダウンロードリンクは少しわかりにくいです。青いdata-for-1.2.11.zipをクリックすると、Baiduクラウドリンクが表示されます。
jarパッケージをインポートします
hanlpをeclipseにインポートします。特定のプロセスは、次のWebサイトを参照できます。
http://jingyan.baidu.com/article/ca41422fc76c4a1eae99ed9f.html
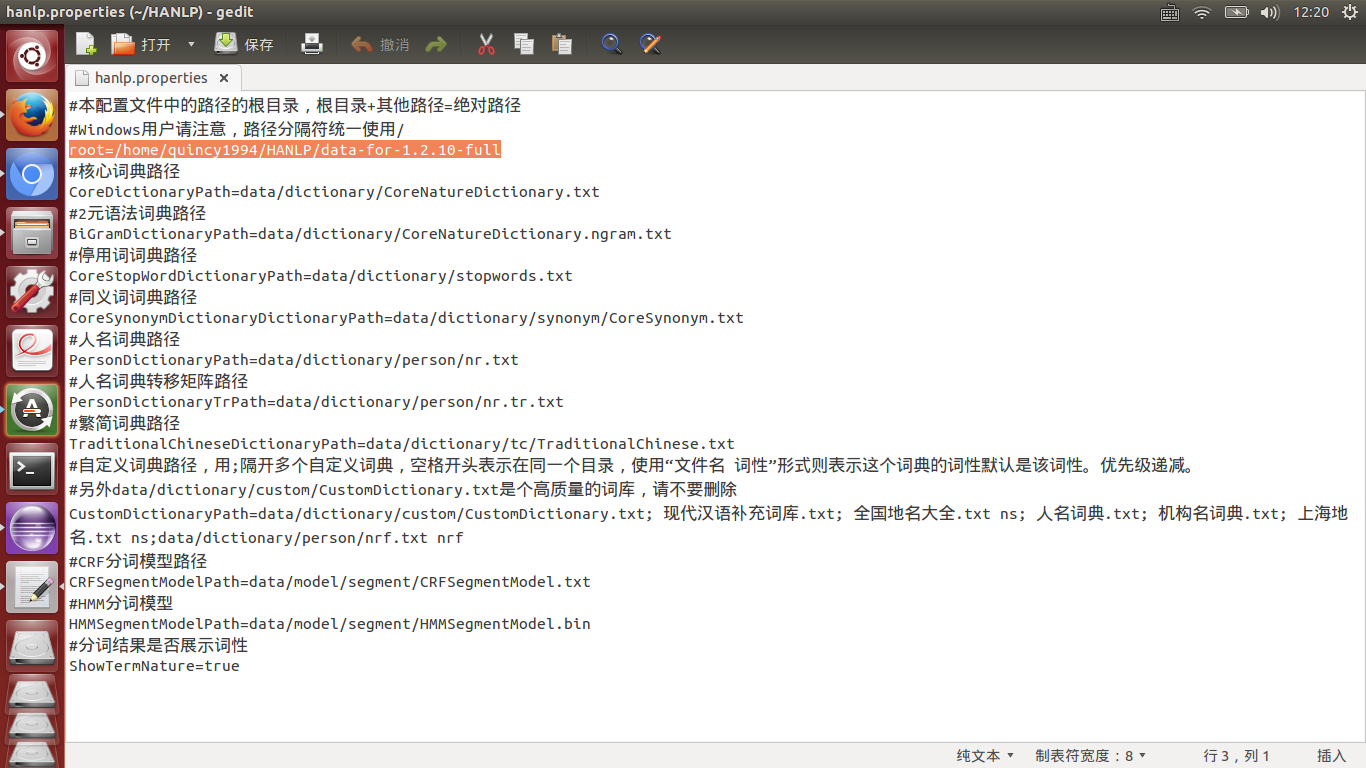
構成ファイルのインポート
hanlp.propertieをプロジェクトのbinディレクトリにコピーし、辞書のパスを変更します
ルートのパスをデータが保存されているパスに変更します(データを解凍することを忘れないでください)
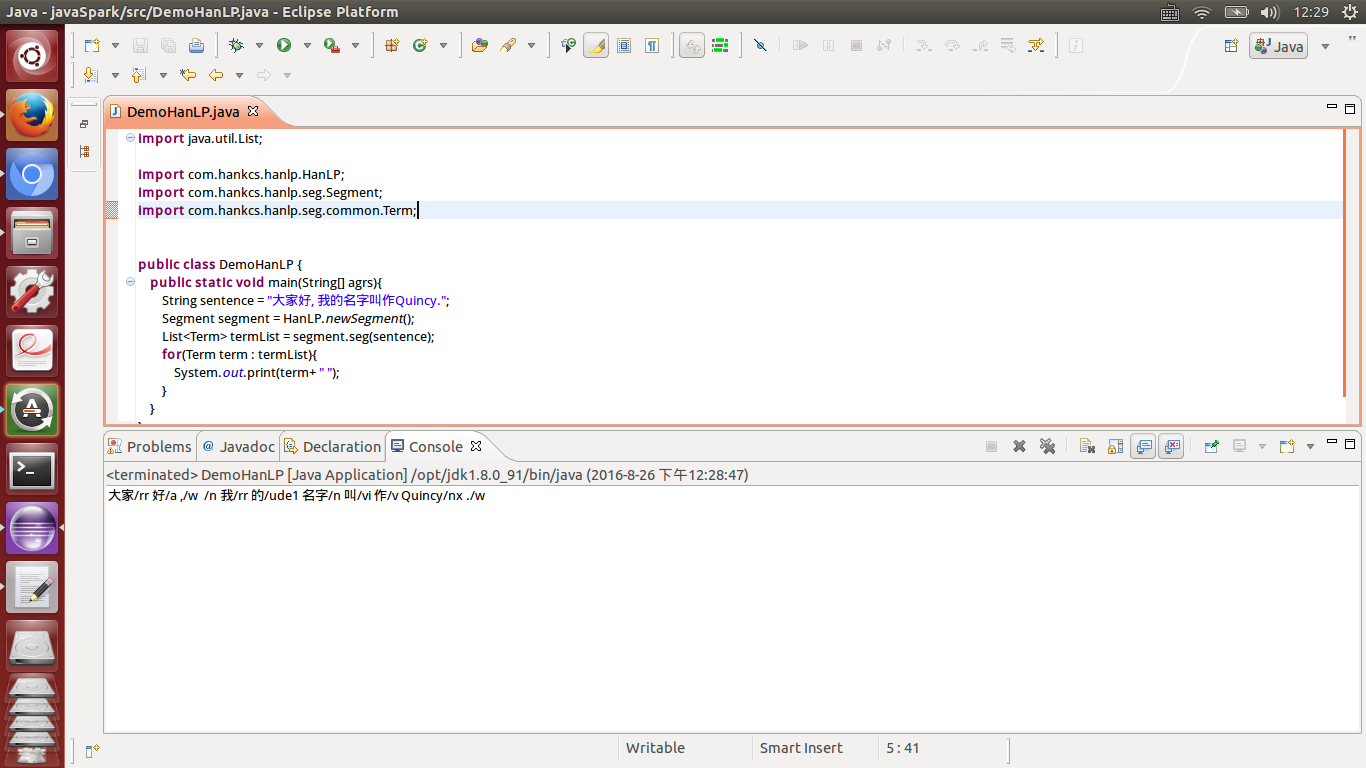
プログラミングコードのデモンストレーション
import java.util.List;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.Term;
public class DemoHanLP {
public static void main(String[] agrs){
文字列文= "みなさん、こんにちは。私の名前はクインシーです。";
Segment segment = HanLP.newSegment();
List
for(Term term : termList){
System.out.print(term+ " ");
}
}
}
動作結果:
この記事はQuincy1994のブログからのものです
Recommended Posts