Pythonクローラー|コグニティブクローラーのリクエストとレスポンス
クローラーを学ぶことの利点と必要性
Pythonクローラーは、ブラウザーをシミュレートしてWebページを開き、Webページで必要なデータを取得することです。
Pythonクローラーの学習は、楽しいだけでなく、Pythonプログラミング言語の基本的な知識も提供します。エンターテインメントとラーニングのコンビネーションを実現するためのIT業界への参入への近道と言えます。小説や面白い写真を読むのが好きですか?仕事を探すことはまだ企業のニーズを一つずつ選別しています!操作やデータ分析のための参照データはありません!暇なときは、クローラーに「ポケットマネー」を稼ぐための小さな要求をしたいと思っています。クローラーはそれをすばやく完了するのに役立ちます。
Pythonクローラーは、習得しやすく、使いやすく、楽しいものとして認識されています。このシリーズの記事には、理論的な知識+ダイアグラムコード、ケース+コンテンツの概要が含まれています。どの知識ポイントについての理解を深めたい場合は、コメント領域にメッセージを残すことができます。 。
Pythonクローラーを学習するには、Pythonソフトウェアを使用する必要があります。Anacondaには、多くのPythonライブラリを統合する独自のpythonコンパイラがあります。構成とインストールは非常に便利です。入門学習に非常に適しています。
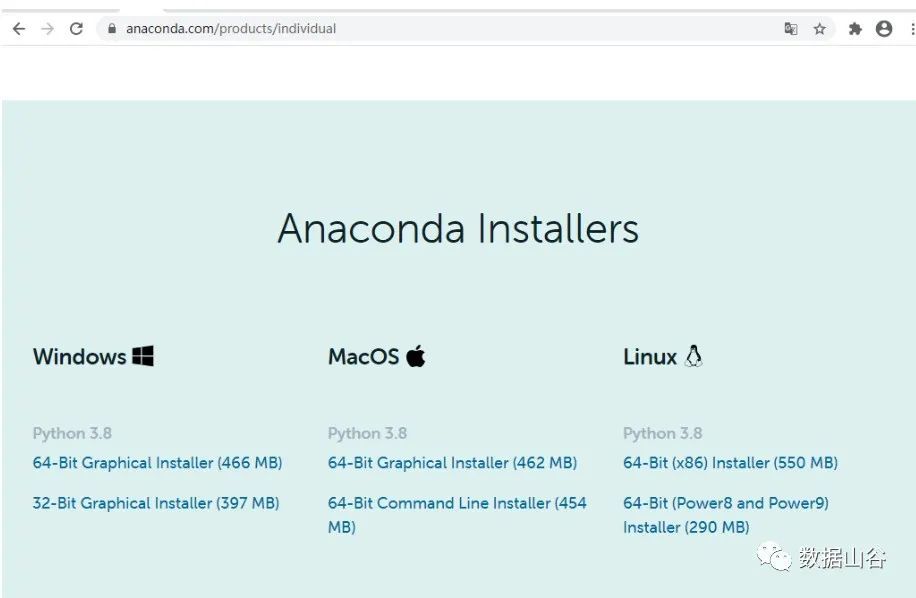
**01 **anacondaソフトウェアのダウンロードとインストール##
アナコンダソフトウェアインストールの公式ウェブサイトアドレス:https://www.anaconda.com/products/individual
**02 **Pythonオンラインコンパイラの推奨事項##
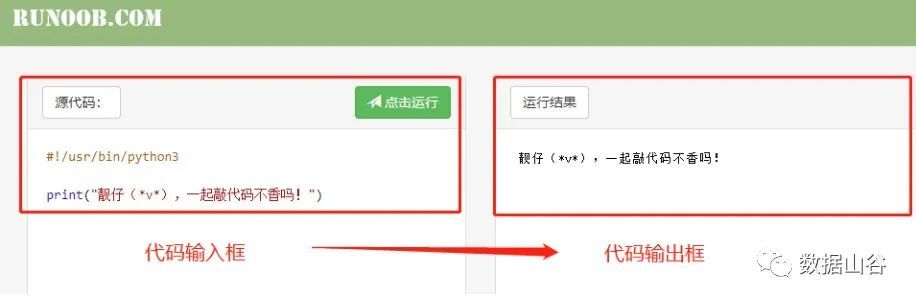
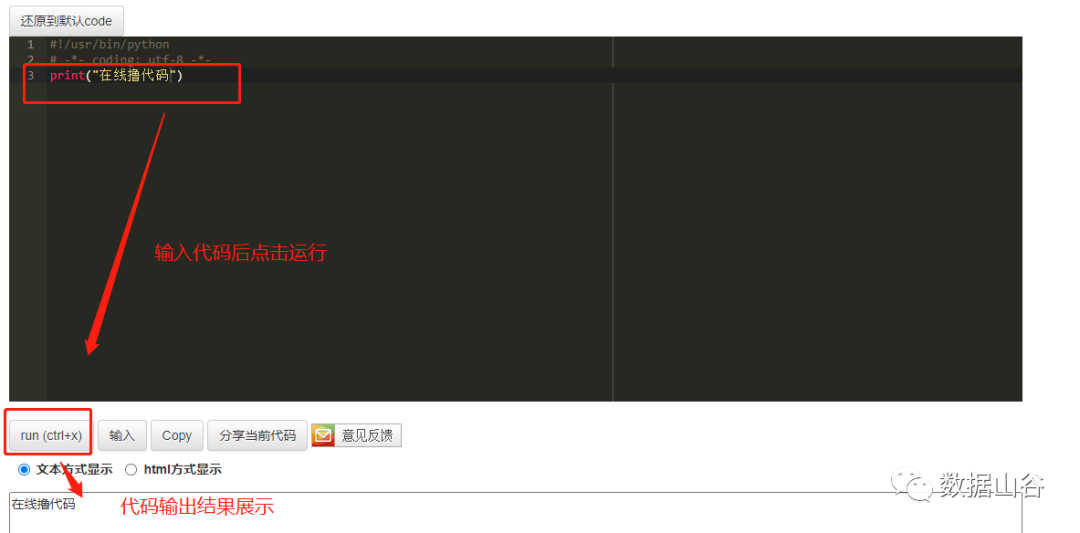
空き時間を利用でき、オフィスが不便な場合は、2つのオンラインコードPython3.0ブラウザリンクをお勧めします。
- https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3
- http://www.dooccn.com/python3/
**03 **クローラーの基本原則##
「武器」ツールを準備してから、「チート」について説明します。クローラーとは何ですか。クローラーはどのようにデータをクロールしますか。クローラーの基本原理は何ですか?
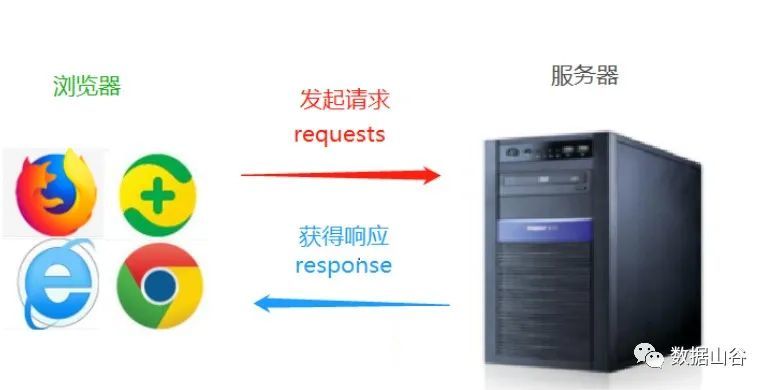
Webスパイダーは、特定のルールに従ってWebサイトを要求し、データと情報を自動的に取得するプログラムまたはスクリプトです。
**04 **基本原則-リクエストはリクエストを開始します##
HTTPライブラリターゲットサイトを介して要求を開始する、つまり要求を送信する場合、要求には追加のヘッダーやその他の情報を含めて、サーバーが応答するのを待つことができます。
Webサイトのリンクを開くと、クライアント(Google、Firefoxなど)からサーバー(Baidu Webサイトを開いたサーバーなど)にリクエストを送信し、サーバーがリクエストを受信して処理し、クライアントに返します(例:Google、Firefox)。ブラウザ)、ブラウザに表示されたデータを見ました。
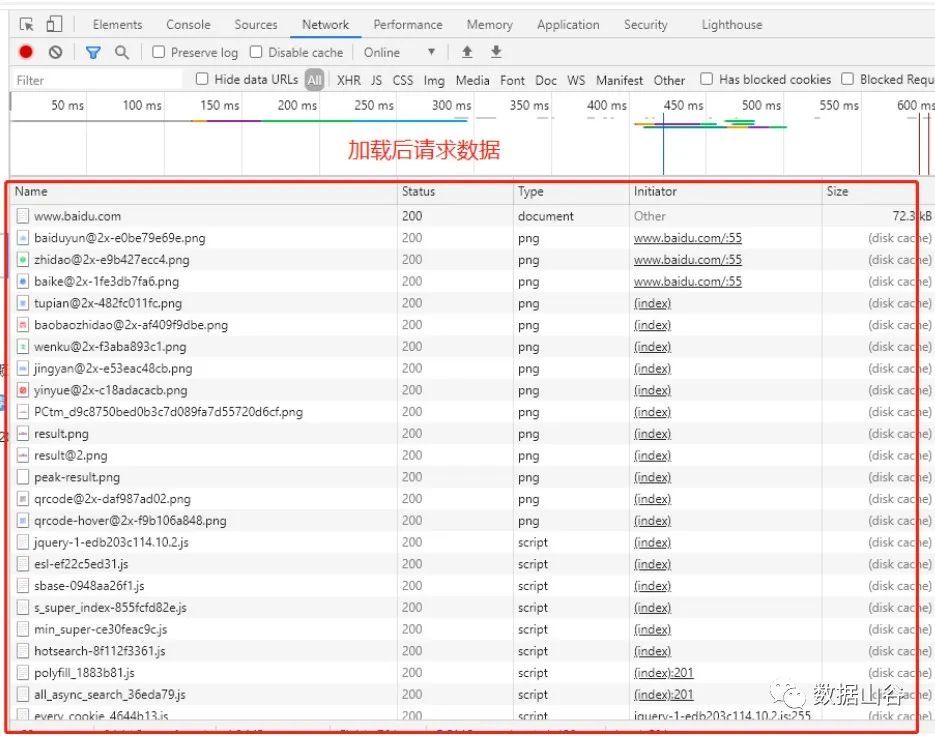
その中で、Elementsは、Webページのソースコードを検索し、DOMノードとCSSスタイルをリアルタイムで編集します。Webページの要求が開始された後、NetworkはHTTP要求によって取得された各要求リソースの情報を分析します。ネットワークのパラメータ値は、私たちの研究の主な内容です。
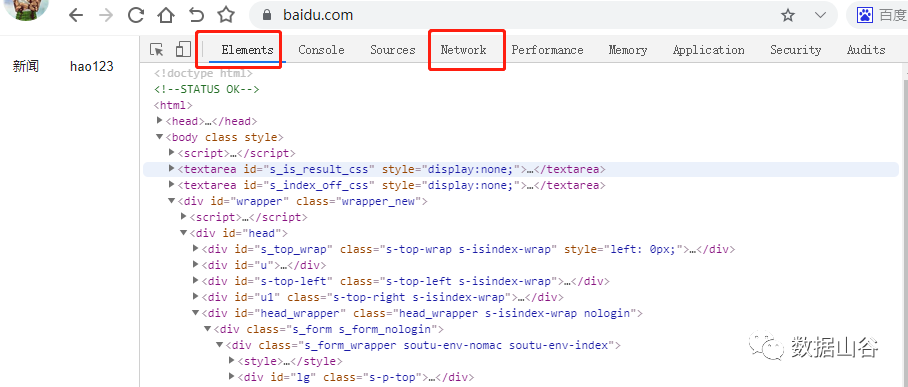
ネットワーク関連のパラメータは次のとおりです。
- ヘッダー:要求URL、HTTPメソッド、応答ステータスコード(例:200、404など)、要求ヘッダーと応答ヘッダーとそれぞれの値、要求パラメーターなどを含むHTTPヘッダー情報を一覧表示します。
- プレビュー:選択したリソースタイプ[JSON、画像、テキスト]に応じて、対応するプレビューを表示するプレビューパネル。
- 応答:フォーマットされていないリソースのコンテンツを含むHTTP応答情報を表示します。
- Cookie:リソースのHTTP要求および応答プロセスでCookie情報を表示します。
- タイミング:リソースリクエストの詳細情報には時間がかかります。
**05 **基本原則-リクエストリクエストメソッド##
リクエストとはリクエストのことです。ブラウザにリンクアドレスを入力し、検索をクリックして[またはEnterキーを押して]リクエストを送信してください。
リクエストメソッドには、主にGetとPost、Head、Put、Delete、Optionsなどの2種類があります。クローラーで最も一般的に使用されるメソッドはPostとGetであり、他のメソッドはほとんど関与しないため、簡単に紹介します。
- Getは、データを読み取り、指定されたページ情報を要求するために使用されます。リクエストまたはサーバーの特定のリソースを送信し、HTTPリクエストヘッダーとプレゼンテーションデータのセット(たとえば、HTMLテキスト、写真、ビデオなど)を介してクライアントに返します。
- 投稿とは、サーバーにデータを送信することです。現在、ほとんどすべてのデータ送信操作は投稿リクエストによって完了しています。
- Headは、HTTP要求ヘッダー情報のみをクライアントに返します。
- PutとPostは、どちらもサーバーにデータを送信するという点で非常に似ています。PUTは通常、リソースの保存場所を指定し、POSTのデータ保存場所はサーバー自体によって決定されます。
- 削除とは、特定のリソースを削除することです。
- オプションリクエストは、クライアントがサーバーのパフォーマンスを表示するためのものです。
リクエストの例:
# リクエスト時にリンクアドレスとしてURLアドレスを直接指定できます
requests.get(url='https://www.baidu.com/s?ie=utf-8&wd=ボールドガール25')
**06 **基本原則-標準形式の後にURL ##が続きます
要求されたURL [ユニフォーム/ユニバーサルリソース識別子]は、ユニフォームリソースロケーターのフルネームです。URLは主に、リソースの命名とリソースのパスまたは場所の提供という2つの目的で使用されます。この場合、Webページのドキュメントや画像などのユニフォームリソースロケーターと呼ばれます。 、動画はURLで指定できます。
HTTPプロトコル:http://またはhttps://;サーバーのリンクアドレス。例:
http//baidu.com
ブラウザでハゲ少女25を検索すると、URLリンクアドレスが変更され、リンクのs?ie = utf-8&wd = bald girl 25は[utf-8]コードを指定し、[bald girl25]は検索キーワードを指定します。
次のようにURLアドレスを指定します。
url ="https://www.baidu.com/s?ie=utf-8&wd=ボールドガール25"
**07 **基本原則-リクエストリクエストヘッダー##
リクエストヘッダーとは、ユーザーエージェント、ホスト、Cookie、その他の情報など、リクエスト時のヘッダー情報を指します。リクエスト本文とは、フォーム送信時のフォームデータなど、リクエスト中に送信された追加データを指します。多くのウェブサイトは、アクセスを申請するときにリクエストヘッダーがないとアクセスできないか、文字化けしたコードを返します。簡単な解決策は、ブラウザの動作を装うリクエストヘッダーを追加するなど、アクセス用のブラウザのふりをすることです。
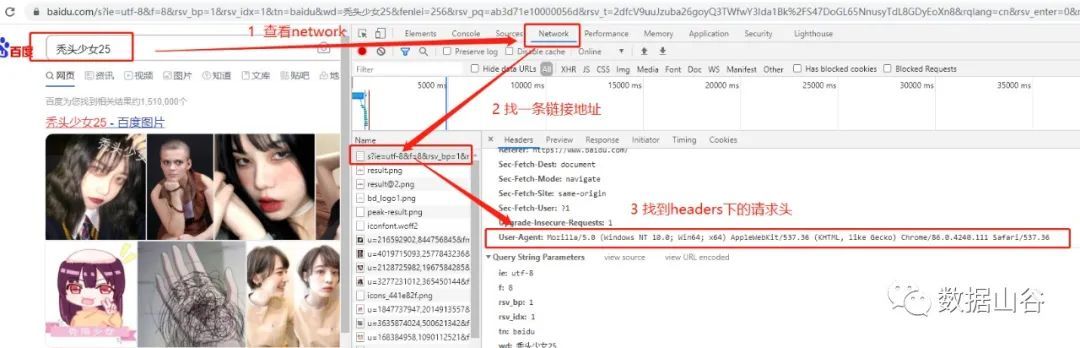
リクエストヘッダーの例:
# リクエストヘッダーを辞書タイプとして定義する
headers ={"User-Agent":"Mozilla/5.0(Windows NT 10.0; WOW64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
**08 **基本原則-応答は応答コンテンツを取得します##
サーバーが正常に応答できる場合は、応答を受け取ります。応答の内容は、取得するページの内容です。タイプは、HTML、Json文字列、バイナリデータ(写真やビデオなど)などです。
次に、リクエスト、リクエストヘッダー、リターンを組み合わせて、簡単なリクエストレスポンスを完成させましょう。
**09 **基本原則-リクエストレスポンスの例##
まず、Pythonにインポートされたネットワークリクエストリクエストモジュールをインストールする必要があります[このモジュールは、pipインストールリクエストを使用してターミナルにインストールする必要があります]。
アクセスリンクでリクエストヘッダーを見つけて辞書として定義します。Getrequestメソッドを使用してリンクアドレスを渡し、リクエストヘッダーを使用してレスポンスコンテンツを取得します。応答によって返される結果は、次のようなアクセスステータスです。<Response [200]> 、Response.textは、テキストコンテンツ全体を返します。
コード例は次のとおりです。
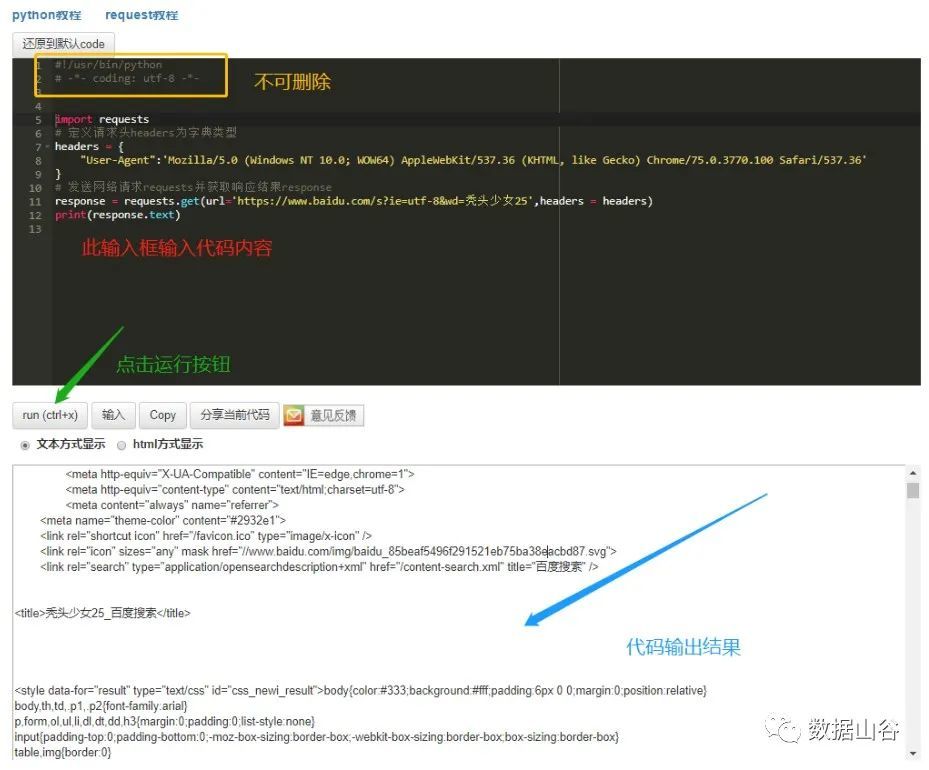
import requests
# リクエストヘッダーを辞書タイプとして定義する
headers ={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
# ネットワーク要求要求を送信し、応答結果応答を取得します
response = requests.get(url='https://www.baidu.com/s?ie=utf-8&wd=ボールドガール25',headers = headers)
# 印刷応答は戻りステータスを出力します、印刷応答.テキストはWebページのテキストを出力します
print(response.text)
Pythonオンラインエディタを使用した操作は次のとおりです。
**10 **基本原則-知識キーワードの要約##
リクエスト(リクエストの開始)、レスポンス(レスポンスの取得)、get(データの読み取り、指定されたページ情報のリクエスト)、post(サーバーへのデータの送信)、url(統一されたリソースロケーター、Webページのドキュメント、画像、およびビデオの指定) 、Hearders(要求された場合のヘッダー情報)。
Recommended Posts