Pythonクローラーgerapyクローラー管理
13. Gerapy
学習目標#####
- Gerapyとは何かを理解する
- Gerapyのインストールをマスターする
- マスタージェラピー構成の起動
- Gerapy構成によるスクレイププロジェクト管理のマスター
1. ジェラピー紹介:###
Gerapyは分散型クローラー管理フレームワークであり、Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js開発に基づくPython3をサポートしています。 、Gerapyは私たちを助けることができます:
- クローラーの操作をより便利に制御する
- クローラーのステータスをより直感的に表示する
- クロール結果をよりリアルタイムで表示
- プロジェクト展開のより簡単な実装
- より統一されたホスト管理
2. Gerapyのインストール###
1.次のコマンドを実行し、インストールが完了するのを待ちます
pip3 install gerapy
2.gerapyが正常にインストールされていることを確認します
ターミナルでgerapyを実行すると、次のメッセージが表示されます
“”"
Usage:
gerapy init [–folder=]
gerapy migrate
gerapy createsuperuser
gerapy runserver [host:port]
“”"
3. ジェラピー構成開始###
1.新しいプロジェクトを作成します
gerapy init
このコマンドを実行すると、現在のディレクトリにgerapyフォルダーが生成され、フォルダーに入ると、projectsという名前のフォルダーが見つかります。
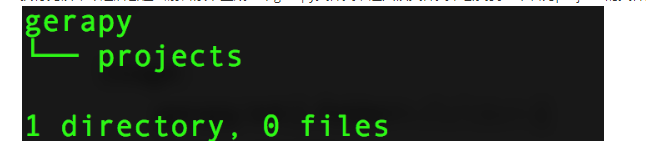
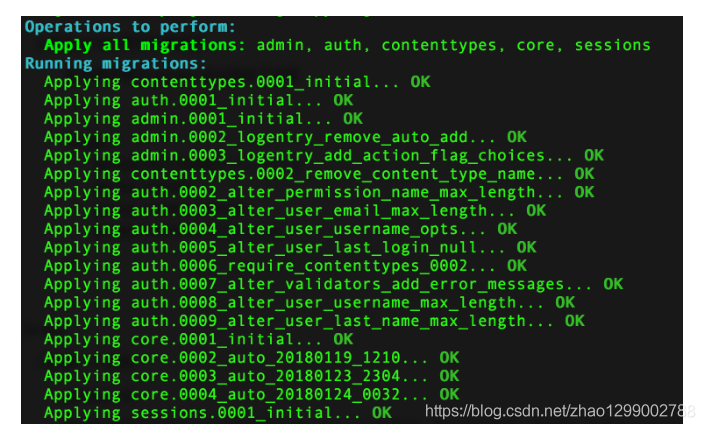
2.データベースを初期化するには(gerapyディレクトリで操作)、次のコマンドを実行します
gerapy migrate
データベースが初期化されると、SQLiteデータベースが生成され、ホスト構成情報や展開バージョンなどが格納されます。
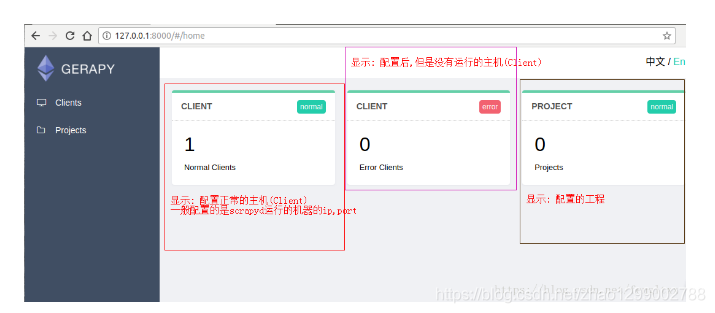
3.ジェラピーサービスを開始します
gerapy runserver
このとき、Gerapyサービスは、gerapyサービスが開始されたマシンのポート8000で有効になっています。ブラウザにhttp:// localhost:8000と入力して、Gerapy管理インターフェイスに入ります。ホスト管理とインターフェイス管理は、管理インターフェイスで実行できます。
4. Gerapy構成を通じてスクレイププロジェクトを管理する###
- ホストを構成します
- スクレイプホストを追加
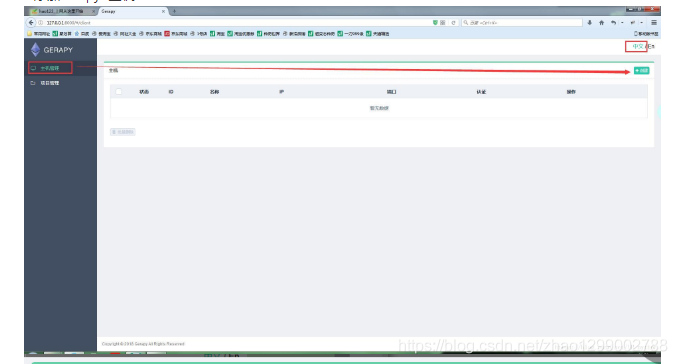
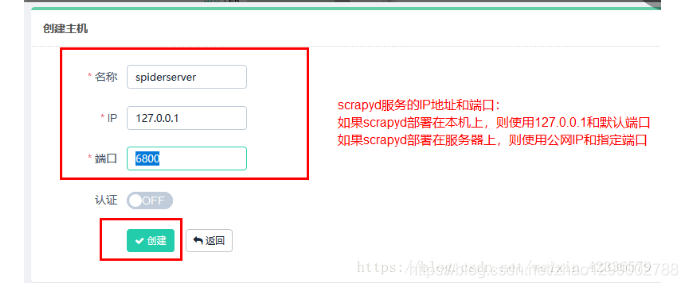
IP、ポート、名前を追加する必要があります。[作成]をクリックして追加を完了します。[戻る]をクリックして、現在追加されているScrapydサービスのリストを表示します。作成が成功すると、リストに追加されたサービスが表示されます。
2.クローラーを実行するには、[スケジュール]をクリックして実行します(構成したスクレイプでクローラーが解放されていることが前提です)。
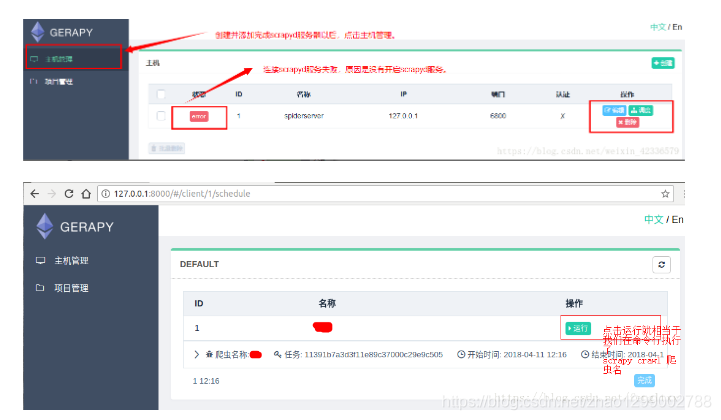
- プロジェクトの構成
- スカーピープロジェクトを/ gerapy / projectsのすぐ下に置くことができます。

- あなたはジェラピーの背景でプロジェクトを見ることができます
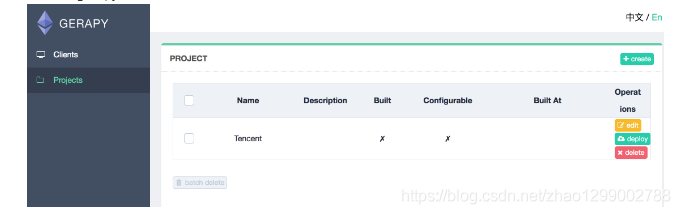
- [デプロイ]をクリックし、[デプロイ]ボタンをクリックしてパッケージ化してデプロイします。右下隅に、Gitのコミット情報と同様にパッケージの説明を入力し、[パッケージ]ボタンをクリックすると、Gerapyがパッケージの成功を促すプロンプトを表示し、パッケージが左側に表示されます。結果とパッケージ名。
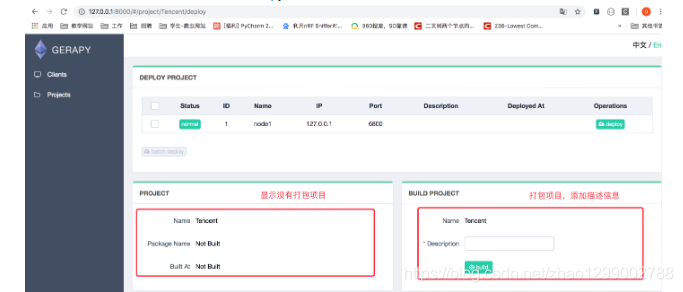
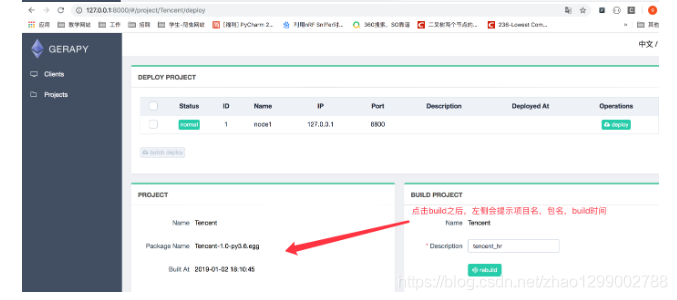
- サイトを選択し、右側の[デプロイ]をクリックして、プロジェクトをこのサイトにデプロイします
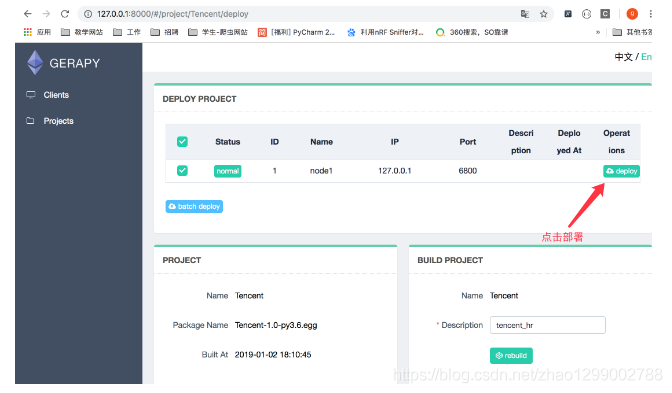
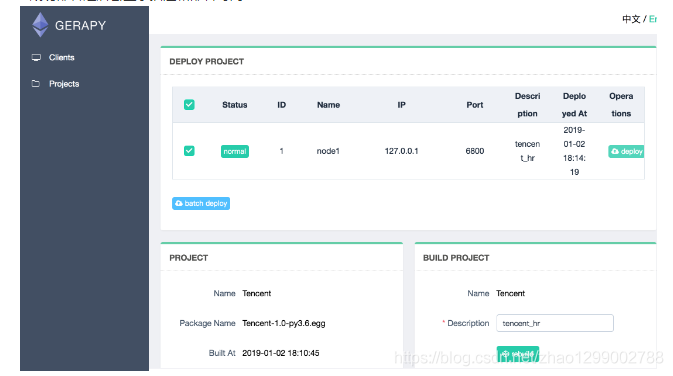
- 展開が成功すると、説明と展開時間が表示されます
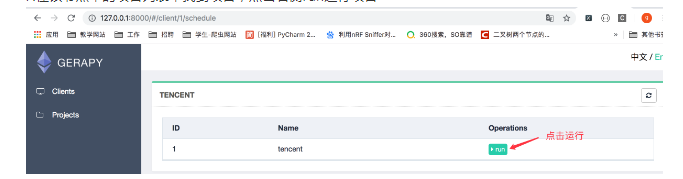
- クライアントインターフェイスに移動し、プロジェクトが展開されているノードを見つけて、[スケジュール]をクリックします
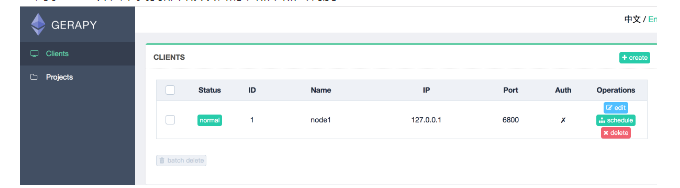
- ノードのプロジェクトリストでプロジェクトを見つけ、右側の[実行]をクリックしてプロジェクトを実行します
補足:###
1. Gerapyはscrapydと関係がありますか??
スクレイプを使用してスクレイプを呼び出してクロールするだけです。コマンドラインを使用してクローラーを起動するだけです。
curl http://127.0.0.1:6800/schedule.json -d project = project name-d spider = crawler name
Greapyの使用は、コマンドラインを使用してクローラーを「小さな手」に変えることです。gerapyでscrapydを構成した後は、コマンドラインを使用する必要はなく、グラフィカルインターフェイスから直接クローラーを起動できます。
概要#####
- Gerapyとは何かを理解する
- Gerapyのインストールをマスターする
- マスタージェラピー構成の起動
- Gerapy構成によるスクレイププロジェクト管理のマスター
Recommended Posts