Python3クローラーlearning.md
[ TOC]
ディレクトリ構造####
(1) urllibは、指定されたWebサイトをクロールするだけです。
(2) スクレイピークローラーフレームワーク
(3) BeautifulSoupクローラー分析
0 x00urllib単純なクロール####
1. 初期クローラー
ケース1:Pythonに付属するurl + libによって形成されたurllibパッケージ
#! /usr/bin/python
# 機能:クローラーの最初のレッスン
import urllib.request #指定されたモジュールをurllibパッケージにインポートします
import urllib.parse #分析的使用
# ケース1:
response = urllib.request.urlopen("http://www.weiyigeek.github.io"+urllib.parse.quote("サイバーセキュリティ")) #Url中国の分析
html = response.read() #バイナリ文字列を返すには
html = html.decode('utf-8') #デコード操作
print("ファイルへの書き込み.....")
f =open('weiyigeek.txt','w+',encoding='utf-8') #オンにする
f.writelines(html)
f.close() #シャットダウン
print("ウェブサイトリクエストの結果:\n",html)
# ケース2:
url ="http://placekitten.com/g/600/600"
response = urllib.request.urlopen(url) #url文字列またはリクエストにすることができます()オブジェクト,返回一个オブジェクト
img = response.read()
filename = url[-3:]+'.jpg'withopen(filename,'wb+')as f: #バイナリはここに保存されることに注意してください
f.write(img)
2. Pyクローラーの実装/最適化
ケース1:スパイダーが中国語-英語翻訳のためにYoudao翻訳インターフェースを呼び出す
#! /usr/bin/python
# 機能:レッスン2クローラーのJSON/プロキシ
import urllib.request
import urllib.parse
import json
import time
url ='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'while True:
i =input("翻訳された英語を入力してください(Qと入力して終了します):")if i =='Q' or i =='q':break
data ={}
data['i']= i
data['from']='AUTO'
data['to']='AUTO'
data['doctype']='json'
data['smartresult']='dict'
data['client']='fanyideskweb'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['salt']='15550362545153'
data['sign']='a28b8eb61693e30842ebbb4e0b36d406'
data['action']='FY_BY_CLICKBUTTION'
data['typoResult']='false'
data = urllib.parse.urlencode(data).encode('utf-8')
# ヘッダーの変更
# オブジェクトリクエストをURLし、リクエストヘッダー情報を追加します
req = urllib.request.Request(url, data) #ヘッダーオブジェクト辞書を直接渡すこともできます
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')
req.add_header('Cookie',' YOUDAO_MOBILE_ACCESS_TYPE=1; [email protected]; OUTFOX_SEARCH_USER_ID_NCOO=1911553850.7151666; YOUDAO_FANYI_SELECTOR=ON; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8N5HySla85aD-6kpOw; ___rl__test__cookies=1555036254514; UM_distinctid=16a0f2c1b0b146-0612adf0fe3fd6-4c312c7c-1fa400-16a0f2c1b0c659; SESSION_FROM_COOKIE=fanyiweb')
req.add_header('Referer','http://fanyi.youdao.com/')
# urlリクエストによって返されたオブジェクト
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
jtarget = json.loads(html) #json解析
print("翻訳結果:",jtarget['translateResult'][0][0]['tgt'])
time.sleep(1) #頻繁なリクエストを防ぐために1秒遅らせる
print("ヘッダー情報の要求:",req.headers)print("リクエストURL:",res.geturl())print("ステータスコード:",res.getcode())print("ヘッダーメッセージを返します:\n",res.info())
# 翻訳された英語を入力してください(Qと入力して終了します):whoami
# 翻訳結果:このユーザー情報を表示する
# ヘッダー情報の要求:{'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0','Cookie':' YOUDAO_MOBILE_ACCESS_TYPE=1; [email protected]; OUTFOX_SEARCH_USER_ID_NCOO=1911553850.7151666; YOUDAO_FANYI_SELECTOR=ON; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8N5HySla85aD-6kpOw; ___rl__test__cookies=1555036254514; UM_distinctid=16a0f2c1b0b146-0612adf0fe3fd6-4c312c7c-1fa400-16a0f2c1b0c659; SESSION_FROM_COOKIE=fanyiweb','Referer':'http://fanyi.youdao.com/'}
# リクエストURL: http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule
# ステータスコード:200
# ヘッダーメッセージを返します:
# Server: Tengine
# Date: Fri,12 Apr 201903:23:02 GMT
# Content-Type: application/json;charset=utf-8
# Transfer-Encoding: chunked
# Connection: close
# Vary: Accept-Encoding
# Vary: Accept-Encoding
# Content-Language: en-US
3. クローラーパラメータ設定
ケース3:プロキシを使用してWebサイトを要求する
#! /usr/bin/python3
# クローラーの3番目のレッスン:プロキシ一般urllibは、次のようにプロキシIPステップを使用します
# プロキシアドレスを設定する
# Proxyhandlerを作成する
# オープナーを作成する
# オープナーをインストールする
import urllib.request
import random
url1 ='http://myip.kkcha.com/'
url2 ='http://freeapi.ipip.net/'
proxylist =['116.209.52.49:9999','218.60.8.83:3129']
ualist =['Mozilla/5.0 (compatible; MSIE 12.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',\
' Mozilla/5.0 (Windows NT 6.7; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',\
' Mozilla/5.0 (Windows NT 6.7; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'\
]
proxyip = random.choice(proxylist)
# プロキシ設定パラメータは辞書です{'の種類':'プロキシIP:港'}
proxy = urllib.request.ProxyHandler({'http':proxyip})
# カスタムオープナーを作成する
pro_opener = urllib.request.build_opener(proxy)
pro_opener.addheaders =[('User-Agent',random.choice(ualist))] #ランダムリクエストヘッダー
# オープナーをインストールする
urllib.request.install_opener(pro_opener)
## オープナーを呼び出す.open(url)
## プロキシを使用してリクエストを行う
url2 = url2+proxyip.split(":")[0]with urllib.request.urlopen(url1)as u:print(u.headers)
res = u.read().decode('utf-8')print(res)with urllib.request.urlopen(url2)as u:
res = u.read().decode('utf-8')print(res)
3. クローラーurllibライブラリの例外処理
#! /usr/bin/python3
# 機能:urllib例外処理
from urllib.request import Request,urlopen
from urllib.error import HTTPError,URLError
urlerror ='http://www.weiyigeek.com'
urlcode ='http://www.weiyigeek.github.io/demo.html'
def url_open(url):
req =Request(url)
req.add_header('APIKEY','This is a password!')try:
res =urlopen(req)except(HTTPError,URLError)as e:ifhasattr(e,'code'): #理由属性の前に配置する必要があります
print('HTTPリクエストエラーコード:', e.code)print(e.read().decode('utf-8')) #[注意]これがeです.read
elif hasattr(e,'reason'):print('サーバーリンクに失敗しました',e.reason)else:print("Suceeccful!")if __name__ =='__main__':url_open(urlerror)url_open(urlcode)
################## の結果#####################
# サーバーリンクに失敗しました[Errno 11001] getaddrinfo failed
# HTTPリクエストエラーコード:404
# < html>
# < head><title>404 Not Found</title></head>
# < body>
# < center><h1>404 Not Found</h1></center>
# < hr><center>nginx/1.15.9</center>
# < /body>
# < /html>
4. 爬虫類の定期的なマッチング
ケース4:通常のクローラー使用率
#! /usr/bin/python3
# 機能:通常およびクローラー
from urllib.request import Request,urlopen,urlretrieve
from urllib.error import HTTPError,URLError
import re
import os
def url_open(url):
req =Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')try:
res =urlopen(req)
html = res.read()
except HTTPError as e:print("サーバー要求エラー:",e.code())return0
except URLError as e:print("リンクサーバーの障害:",e.reason())return0else:return html
def save_img(url,dir):
i =0
os.mkdir(dir)
os.chdir(os.curdir+'/'+dir)for each in url:
# 将来的に廃棄されることはお勧めしませんが、それは本当に便利です
urlretrieve(each,str(i)+'.jpg',None)
i +=1else:print("ダウンロード完了!\a\a")
def get_img(url):
res =url_open(url).decode('utf-8')if res ==0:exit("エラー終了のリクエスト")
p = r'<img src="([^"]+\.jpg)"'
imglist= re.findall(p,res)save_img(imglist,'test')print(imglist)if __name__ =='__main__':
url ='http://tieba.baidu.com/f?kw=%E9%87%8D%E5%BA%86%E7%AC%AC%E4%BA%8C%E5%B8%88%E8%8C%83%E5%AD%A6%E9%99%A2&ie=utf-8&tab=album'get_img(url)

WeiyiGeek。定期的およびクローラーの使用率
5. 高度なクローラーの正規化
ケース5:クローラーがプロキシWebサイトのip:portを取得します
#! /usr/bin/python3
# urllibクローラーの最後のレッスン
import urllib.request
from urllib.error import HTTPError,URLError
import re
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')try:
res = urllib.request.urlopen(req)except(HTTPError,URLError)as e:print("エラーが発生しました:",e.code,'間違ったページ:',e.read())return0else:return res.read().decode('utf-8')
def main1(url,filename):
html =url_open(url)if html ==0:exit("リクエストエラー,プログラム終了!")
exp = r'<td>((?:(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){0,3}(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5]))</td>\n(?:\s*?)<td>(?P<port>\d{0,4})</td>' #これはピットです
regres = re.findall(exp,html,re.M)
iplist =[]for each in regres:
ipport = each[0]+':'+ each[1]
iplist.append(ipport)withopen(filename,'w+',encoding='utf-8')as f:for i inrange(len(iplist)):
f.write(iplist[i]+'\n')if __name__ =='__main__':
url ='https://www.xicidaili.com/nn/'main1(url,'proxyip.txt')
######### プロキシの結果を取得する################
# 119.102.186.99:9999
# 111.177.175.234:9999
# 222.182.121.10:8118
# 110.52.235.219:9999
# 112.85.131.64:9999
0 x02スクレイプクローラーフレームワーク####
(1) ひどいインストール構成#####
1.1 アナコンダのインストールプロセス
この方法は、Scrapyをインストールする比較的簡単な方法です(特にWindowsの場合)。この方法を使用してインストールするか、以下の専用プラットフォームインストール方法を使用できます。
Anacondaは、一般的に使用されるデータサイエンスライブラリを含むPythonディストリビューションです。インストールしていない場合は、[https://www.continuum.io/downloadsにアクセスして、対応するプラットフォームパッケージをダウンロードしてインストールできます。 ](https://www.continuum.io/downloads%E4%B8%8B%E8%BD%BD%E5%AF%B9%E5%BA%94%E5%B9%B3%E5%8F%B0%E7%9A%84%E5%8C%85%E5%AE%89%E8%A3%85%E3%80%82)
すでにインストールされている場合は、condaコマンドを使用してScrapyを簡単にインストールできます。
インストールコマンドは次のとおりです。
conda install Scrapy
1.2 Windowsのインストールプロセス
WINDOSでインストールする最良の方法は、wheelファイルを介してインストールすることです。私はWIN10環境にpip3を使用しています。
# 現在の環境:win10+py3.7
pip3 install wheel
pip3 install lxml #対応するバージョンを見つけるために注意を払ってください-lxmlをインストールします
pip3 install zope.interface #zopeをインストールする.interfacepip3 install Twisted
pip3 install pywin32
pip3 install Scrapy #最後にScrapyをインストールします
# pyOpenSSLをインストールします
# 公式ウェブサイトhttpsからホイールファイルをダウンロードしてください://pypi.python.org/pypi/pyOpenSSL#downloads
pip3 install pyOpenSSL-16.2.0-py2.py3-none-any.whl
# Py3.7すべてのライブラリのワンクリックアップグレード
from subprocess import call
from pip._internal.utils.misc import get_installed_distributions
for dist inget_installed_distributions():call("pip install --upgrade "+ dist.project_name, shell=True)
1.3 CentOS、RedHat、Fedora
必要なライブラリがいくつかインストールされていることを確認するには、次のコマンドを実行します。
sudo yum groupinstall development tools
sudo yum install python34-devel epel-release libxslt-devel libxml2-devel openssl-devel
pip3 install Scrapy
1.4 Ubuntu、Debian、Deepin
依存ライブラリのインストール最初に、いくつかの必要なライブラリがインストールされていることを確認し、次のコマンドを実行します。
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
pip3 install Scrapy
1.5 Mac OS
依存ライブラリのインストールMacでScrapyの依存ライブラリを構築するには、Cコンパイラと開発ヘッダーファイルが必要です。これらは通常、Xcodeによって提供されます。次のコマンドを実行してインストールできます。
xcode-select –install
pip3 install Scrapy
インストールを確認した後、コマンドラインに入力します。以下のような結果が表示された場合は、Scrapyが正常にインストールされていることを示しています。
WeiyiGeek.scrapy
(2) くだらない紹介と使用#####
Scrapyは、Pythonベースのクローラーフレームワークです。Webサイトデータをクロールして構造データを抽出するために作成されたアプリケーションフレームワークです。データマイニング、情報処理、または履歴データやその他のニーズの保存に使用できます。
Scrapyを使用してWebサイトをクロールするには、次の4つの手順があります。
- Scrapyプロジェクトを作成する
- アイテムコンテナの定義:辞書に似ていますが、スペルエラーや未定義のフィールドエラーを回避するための追加の保護メカニズムを備えた、クロールされたデータを格納するためのコンテナ。
- クローラーを書く
- ストレージメモリ
フレームの例の画像:
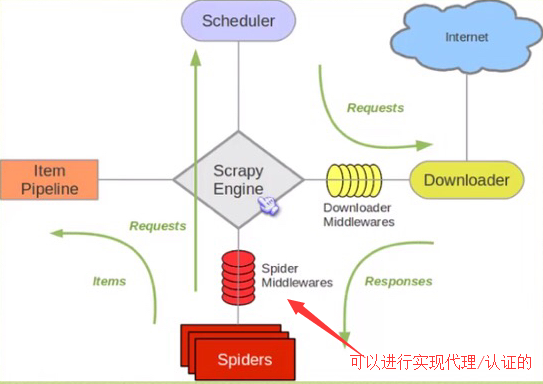
WeiyiGeek.Scrapy
2.1 かすれた一般的なコマンド
scrapy startproject douban #そして、プロジェクトのdoubanを初期化します
scrapy genspider douban_spider movie.douban.com #一般的なクローラーファイルの確立後は、クロールアドレスです
scrapy crawl douban_spider #クロールのためにスクレイププロジェクトを開きます,douban_スパイダープロジェクトのエントリ名
scrapy shell <url> #インタラクティブテストクローラープロジェクトでデータを抽出するためにテストを実行するコード
scrapy shell "http://scrapy.org"--nolog #印刷ログは二重引用符であることに注意してください
scrapy crawl douban_spider -o movielist.json #クロールされたデータを特定の形式で保存する
scrapy crawl douban_spider -o movielist.cvs
2.2 スクレイププロジェクト分析
weiyigeek
│ items.py #データモデルファイル,コンテナ作成オブジェクト(シリアルナンバー,名前,説明,評価)
│ middlewares.py #ミドルウェア設定(クローラーIPアドレスカモフラージュ)
│ pipelines.py #パイプラインを介してデータを書き込む/ディスク上
│ settings.py #プロジェクト設定(USER-AGENT,クロール時間)
│ __init__.py
├─spiders
│ │ douban_spider.py #爬虫類プロジェクトの入り口
│ │ __init__.py
scrapy.cfg #プロフィール情報
2.3 スクレイプセレクターの紹介
Scrapyでは、XPathとCSSに基づく式メカニズムを使用するセレクターが使用されます。4つの基本的な方法があります。
- xpath():xpath式を渡し、式に対応するすべてのノードのセレクターリストリストを返します。#xml解析メソッドxpath構文:response.xpath( "// div [@ class = 'article'] // ol [@ class = 'grid_view'] / li ")#クラスが記事でクラスがgrid_viewの下のolであるdivの下のすべてのliタグを選択します
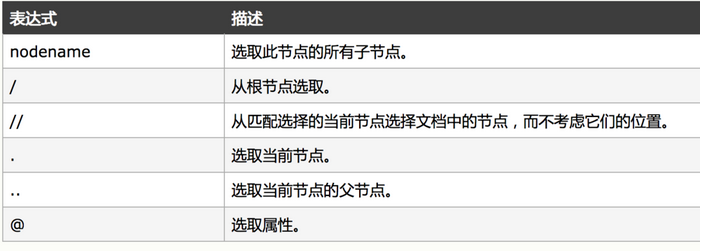
WeiyiGeek.xpath構文属性
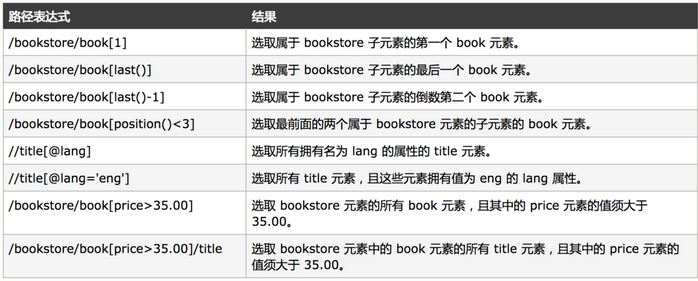
WeiyiGeek。例
-
css():CSS式を渡し、式response.css( '。Classname tag :: method')。extract()に対応するすべてのノードのセレクターリストを返します。#インターセプト文字列
-
extract():ノードをユニコード文字列としてシリアル化し、リストを返します
-
re():渡された正規式に従ってデータを抽出し、ユニコード文字列のリストを返します
2.4 スクレイピーインタラクティブデバッグ
説明:Scrapyターミナルは、スパイダーを起動せずにクロールコードを試してデバッグするためのインタラクティブなターミナルです。
- shelp()-使用可能なオブジェクトとショートカットコマンドのヘルプリストを出力します
- fetch(request_or_url)-指定されたリクエスト(リクエスト)オブジェクトまたはURLに従って新しい応答を取得し、関連するオブジェクトを更新します
- view(response)-このマシンのブラウザで指定された応答を開き、ダウンロードしたhtmlを保存します。
外部リンク(画像やcssなど)を正しく表示できるように、応答本文にタグが追加されます。この操作では一時ファイルがローカルに作成され、ファイルは自動的に削除されないことに注意してください。 - クローラー-現在のクローラーオブジェクト。
- spider-URLを処理するスパイダー。現在のURLにSpiderがない場合、それはSpiderオブジェクトです。
- request-最近取得したページのRequestオブジェクト。replace()を使用してリクエストを変更できます。または、フェッチショートカットを使用して、新しいリクエストを取得します。
- response-最後に取得したページを含むResponseオブジェクト。
- sel-最近取得した応答に基づいて構築されたSelectorオブジェクト。
- 設定-現在のScrapy設定
場合:
> scrapy shell "http://movie.douban.com/chart">>>help(コマンド)>>> request
< GET http://www.weiyigeek.github.io>> response.url
' https://movie.douban.com/chart'>>> response
<200 https://movie.douban.com/chart>>>> response.headers #リクエストヘッダー
>>> response.body #Webページのソースコード
>>> response.text
>>> response.xpath('//title') #xpathセレクターを返す
>>> response.xpath('//title').extract() #xpath式抽出コンテンツ
['< title>\nドゥバン映画ランキング\n</title>']
response.xpath('//title/text()').extract() #テキスト情報を抽出する
['\ nドゥバン映画ランキング\n']>>> response.xpath("//div[@class='pl2']//a").extract_first().strip() # extract_最初に最初に一致するデータを抽出します
'< a href="https://movie.douban.com/subject/25986662/" class="">\nクレイジーエイリアン\n / <span style="font-size:13px;">Crazy Alien</span>\n </a>'
# 抽出用のCSS
>>> sel.css('.pl2 a::text').extract_first().strip()'クレイジーエイリアン\n /'
# Webサイトからリクエストのヘッダー情報を抽出する問題を解決する方法:
from scrapy import Request #インポートモジュール
>>> data =Request("https://www.taobao.com",headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"})>>>fetch(data) #リクエストされたウェブサイトを取得する
2017- 11- 3022:24:14[ scrapy.core.engine] DEBUG:Crawled(200)<GET https://www.taobao.com>(referer: None)>>> sel.xpath('/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]')[<Selector xpath='/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]' data='<a href="https://www.taobao.com/markets/'>]>>> data.headers #セットヘッダーを表示する
{ b'User-Agent':[b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'], b'Accept-Encoding':[b'gzip,deflate']}
# 反復ループの複数の文字列に一致
>>> fetch('http://weiyigeek.github.io')>>> title = response.css('.article-header a::text').extract()>>>for each in title:...print(each)...
セキュリティデバイスポリシーバイパステクノロジの概要.md
プラットフォームのセキュリティ構成に勝つ.md
Python3正規表現の特殊な記号と使用法.md
Python3クローラー学習.md
ディスクの高可用性ソリューション(DBA).md
Nodejs入門学習1.md
Node.jsの紹介とインストール.md
ドメイン制御セキュリティの基礎.md
イントラネット浸透情報検索に勝つ.md
利用性の高いサービスソリューション(DBA).md
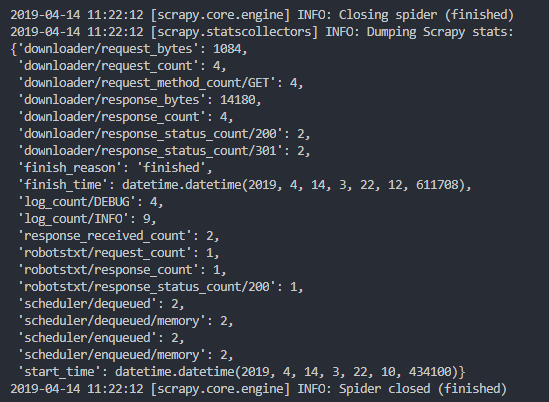
WeiyiGeek.scrapyshell
2.4 スクレイプの簡単な例
scrapy startproject weiyigeek
scrapy genspider blog_spider www.weiyigeek.github.io
'''
items.pyによってキャプチャされたオブジェクトのデータモデルファイルを編集します
'''
import scrapy
classWeiyigeekItem(scrapy.Item):
# items.py取得するオブジェクトを設定し、データモデルファイルを編集します,オブジェクトを作成する(シリアルナンバー,名前,説明,評価)
title = scrapy.Field() #題名
href = scrapy.Field() #タイトルアドレス
time = scrapy.Field() #作成時間
'''
blog_spider.pyクローラーはメインファイルを処理します
'''
# - *- coding: utf-8-*-import scrapy
from weiyigeek.items import WeiyigeekItem #データコンテナのクラスに属性をインポートします(プロジェクト内のアイテムを実際にインポートします.py)classBlogSpiderSpider(scrapy.Spider):
name ='blog_spider' #クローラー名
allowed_domains =['www.weiyigeek.github.io'] #クローラーによって許可されたドメイン
start_urls =['http://www.weiyigeek.github.io/','http://weiyigeek.github.io/page/2/'] #クローラークロールデータアドレス,スケジューラーへ
# リクエストによって返されたページオブジェクトを解析します
def parse(self, response):
sel = scrapy.selector.Selector(response) #スクレイピーセレクター
sites = sel.css('.article-header') #cssセレクターを使用して選択します
items =[]for each in sites:
item =WeiyigeekItem() #データコンテナクラス
item['title']= each.xpath('a/text()').extract()
item['href']= each.xpath('a/@href').extract()
item['time']= each.xpath('div[@class="article-meta"]/time/text()').extract() #ここでの使用に注意してください
items.append(item)
# 画面に出力
print(">>>",item['title'],item['href'],item['time'])return items
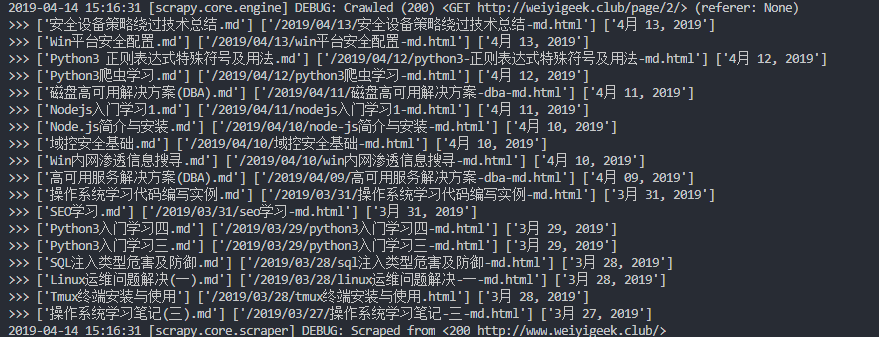
WeiyiGeek。実行結果
(3) くだらないサンプルプロジェクト#####
説明:iQiyiのTOPS250プロジェクトをクロールします。
# Step1.スパイダープロジェクトを作成し、クローラー名を初期化します
scrapy startproject douban
scrapy genspider douban_spider movie.douban.com
'''
Step2.アイテムテンプレートファイルを変更する
'''
classDoubanItem(scrapy.Item):
serial_number = scrapy.Field() #シリアルナンバー
movie_name = scrapy.Field() #映画のタイトル
introduce = scrapy.Field() #前書き
star = scrapy.Field() #星評価
evaluate = scrapy.Field() #評価
describle = scrapy.Field() #説明
'''
Step3.クローラーファイルを変更する
'''
# - *- coding: utf-8-*-import scrapy
from douban.items import DoubanItem #コンテナdoubanをインポートする\items.py
classDoubanSpiderSpider(scrapy.Spider):
name ='douban_spider' #クローラーの名前
allowed_domains =['movie.douban.com'] #クローラーによって許可されたドメイン
start_urls =['https://movie.douban.com/top250'] #クローラークロールデータアドレス,スケジューラーへ
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")for i_item in movie_list:
douban_item =DoubanItem() #モデルの初期化
# テキストを取る()終了とは、その情報を取得することを意味します,extract_first()結果の最初の値をフィルタリングします
douban_item['serial_number']= i_item.xpath(".//div[@class='item']//em/text()").extract_first() #ランク
douban_item['movie_name']= i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first() #名前
descs = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract_first() #
# スペースの問題への対処
desc_str =''for i_desc in descs:
i_desc_str ="".join(i_desc.split())
desc_str += i_desc_str
douban_item['introduce']= desc_str #前書き
douban_item['star']= i_item.xpath(".//span[@class='rating_num']/text()").extract_first() #星
douban_item['evaluate']= i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() #評価の数
douban_item['describle']= i_item.xpath(".//p[@class='quote']/span/text()").extract_first() #説明
yield douban_item #返された結果をアイテムPiplineに押して処理します(強調)
# 次のページの処理機能
next_link = response.xpath("//div[@class='article']//span[@class='next']/link/@href").extract()if next_link:
next_link = next_link[0]yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse) #(強調)
# 説明:
# 1 各forループが終了した後,次のページのリンクを取得する必要があります:next_link
# 2 最後のページに達したときに次のページがない場合,判断する必要があります
# 3 次のアドレスステッチ:2番目のページをクリックすると、ページアドレスはhttpsです。://movie.douban.com/top250?start=25&filter=
# 4 callback=self.parse :コールバックをリクエストする
'''
Step4.構成ファイルを変更する
'''
$ grep -E -v "^#" settings.py
BOT_NAME ='douban' #プロジェクト名
SPIDER_MODULES =['douban.spiders']
NEWSPIDER_MODULE ='douban.spiders'
USER_AGENT =' Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY =0.5
# チャネル設定
ITEM_PIPELINES ={'douban.pipelines.DoubanPipeline':300,}
# ミドルウェア設定のダウンロード
DOWNLOADER_MIDDLEWARES ={'douban.middlewares.my_proxy':543,'douban.middlewares.my_useragent':544,}
# モンゴを設定する_dbデータベース情報
mongo_host ='172.16.0.0'
mongo_port =27017
mongo_db_name ='douban'
mongo_db_collection ='douban_movie''''
Step5.パイプラインを変更する.py
'''
# - *- coding: utf-8-*-import pymongo
from douban.settings import mongo_host ,mongo_port,mongo_db_name,mongo_db_collection
classDoubanPipeline(object):
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
def process_item(self, item, spider):
data =dict(item)
self.post.insert(data)return item
'''
Step6.中価格のドキュメント:middlewares.py
'''
# ipプロキシ中間価格のコンパイル(クローラーIPアドレスカモフラージュ)/ヘッダーユーザー-エージェントはランダムに変装します
import base64
import random
# ファイルの最後にメソッドを追加する:classmy_proxy(object): #プロキシ
def process_request(self,request,spider):
request.meta['proxy']='http-cla.abuyun.com:9030'
proxy_name_pass = b'H622272STYB666BW:F78990HJSS7'
enconde_pass_name = base64.b64encode(proxy_name_pass)
request.headers['Proxy-Authorization']='Basic '+ enconde_pass_name.decode()
# 説明:アブクラウド登録に従ってhttpトンネルリスト情報を購入する
# request.meta['proxy']:'サーバーアドレス:ポート番号'
# proxy_name_pass: b'証明書の番号:キー',bの先頭は文字列base64処理です
# base64.b64encode():変数はbase64処理を行います
# ' Basic ':基本の後にスペースが必要です
classmy_useragent(object): # userAgent
def process_request(self, request, spider):
UserAgentList =["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5","Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5","Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre","Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",]
agent = random.choice(UserAgentList)
request.headers['User_Agent']= agent
## スクレイプクロールを実行すると、上記の真ん中のキーメソッドが表示されます
データをjsonファイルまたはcsvファイルに保存することもできます
- scrapy crawl douban_spider -o movielist.csv
- scrapy crawl douban_spider -o movielist.json
ピットにスクレイピー#####
- Q:ツイストをインストールするときに依存関係の問題がありますか? *

WeiyiGeek。質問1
解決策:[公式ウェブサイトのダウンロードツイストwhlパッケージのインストール](https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted)
Twisted‑19.2.0‑cp37‑cp37m‑win_amd64.whl
毎日の学習で働く####
- 機能:州を見つけるための学校の使用を実現する*
#! /usr/bin/env python3
# - *- coding: utf-8-*-
# 機能:学区分析
import urllib.request
import urllib.parse
from lxml import etree
number =[]
name =[]
file1 =open('2.txt','r',encoding='utf-8')for i in file1:
keyvalue = i.split(" ")
number.append(str(keyvalue[0]))
name.append(str(keyvalue[1]))
file1.close()
def test1(html,parm=""):
dom_tree = etree.HTML(html)
links = dom_tree.xpath("//div[@class='basic-info cmn-clearfix']/dl/dd/text()")for i in links:for v inrange(0,len(number)):if(i.find(name[v][:2])!=-1):return number[v]+ name[v]+parm+"\n"return"見つかりません(または海外)"
file =open('1.txt','r+',encoding='utf-8')
file.seek(0,0)for eachline in file:
url ="https://baike.baidu.com/item/"+urllib.parse.quote(eachline[6:]);
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8') #デコード操作
f =open('c:\\weiyigeek.txt','a+',encoding='utf-8') #オンにする
res =test1(html,str(eachline[6:]))
f.writelines(res)
f.close() #シャットダウン
file.close()
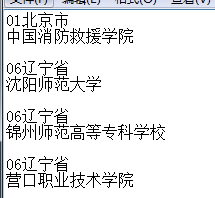
WeiyiGeek。実行後の効果
Recommended Posts