centOS7でのSparkのインストールと構成のチュートリアルの詳細な説明
環境の説明:
オペレーティングシステム:centos764ビット3ユニット
centos7-1 192.168.190.130 master
centos7-2 192.168.190.129 slave1
centos7-3 192.168.190.131 slave2
Sparkをインストールするには、次のものを同時にインストールする必要があります。
jdk scale
- jdkをインストールし、jdk環境変数を構成します
jdk、Baiduを自分でインストールして構成する方法については説明しません。
- スカラをインストールする
scalaインストールパッケージをダウンロードします。https://www.scala-lang.org/download/ダウンロードする要件を満たすバージョンを選択し、クライアントツールを使用してサーバーにアップロードします。解凍:
# tar -zxvf scala-2.13.0-M4.tgz
再度変更する/etc/プロファイルファイルに、次のコンテンツを追加します。
export SCALA_HOME=$WORK_SPACE/scala-2.13.0-M4
export PATH=$PATH:$SCALA_HOME/bin
# source /etc/profile //すぐに有効にする
# scala -version //scalaがインストールされているかどうかを確認します
** 3. Sparkをインストール**
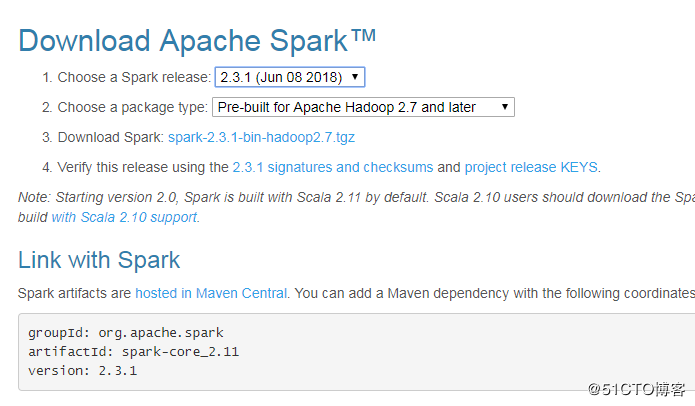
Sparkダウンロードアドレス:http://spark.apache.org/downloads.html
注:ダウンロードするさまざまなバージョンのパッケージがあります。必要なダウンロードとインストールを選択するだけです。
ソースコード:Sparkソースコード。使用するにはコンパイルする必要があり、Scala2.11を使用するにはソースコードを使用してコンパイルする必要があります。
ユーザー提供のHadoopを使用した事前ビルド:「Hadoop無料」バージョン。すべてのHadoopバージョンに適用可能
Hadoop 2.7以降のプレビルド:Hadoop 2.7に基づくプレビルドバージョン。これは、このマシンにインストールされているHadoopバージョンに対応している必要があります。 Hadoop2.6もオプションです。ここにインストールされているhadoopは3.1.0なので、hadoop2.7以降のバージョンに直接インストールしました。
注:hadoopのインストールについては、以前のブログを確認してください。説明は繰り返されません。
centOS7でのSparkのインストールと構成
# mkdir spark
# cd /usr/spark
# tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz
# vim /etc/profile
# Spark環境変数を追加し、PATHの下に追加して、エクスポートします
# source /etc/profile
# confディレクトリに入り、sparkを置きます-env.sh.テンプレートのコピーと名前が変更されたspark-env.sh
# cd /usr/spark/spark-2.3.1-bin-hadoop2.7/conf
# cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
export SCALA_HOME=/usr/scala/scala-2.13.0-M4
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64
export HADOOP_HOME=/usr/hadoop/hadoop-3.1.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/spark/spark-2.3.1-bin-hadoop2.7export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=1G
# confディレクトリに入り、スレーブを配置します.テンプレートのコピーをコピーして、名前をスレーブに変更します
# cd /usr/spark/spark-2.3.1-bin-hadoop2.7/conf
# cp slaves.template slaves
# vim slaves
# ノードドメイン名をスレーブファイルに追加します
# master //ドメイン名はcentos7です-1つのドメイン名
# slave1 //ドメイン名はcentos7です-2つのドメイン名
# slave2 //ドメイン名はcentos7です-3つのドメイン名
スパークを開始
# Sparkを開始する前にhadoopノードを起動します
# cd /usr/hadoop/hadoop-3.1.0/
# sbin/start-all.sh
# jps //開始されたスレッドがhadoopを開始したかどうかを確認します
# cd /usr/spark/spark-2.3.1-bin-hadoop2.7
# sbin/start-all.sh
備考:slave1で\slave2ノードでは、sparkも上記の方法でインストールするか、slave1に直接コピーする必要があります。,slave2ノード
# scp -r /usr/spark root@slave1ip:/usr/spark
起動情報は次のとおりです。
starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.com.cn.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.com.cn.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
Sparkクラスターをテストします。
ブラウザを使用して、マスターノードでsparkクラスタのURLを開きます:http://192.168.190.130:8080 /
総括する
上記は、編集者が紹介したcentOS7でのSparkのインストールと構成のチュートリアルの詳細な説明です。お役に立てば幸いです。ご不明な点がございましたら、メッセージを残してください。編集者が時間内に返信します。
Recommended Posts