Centos7hadoopクラスターのインストールと構成
再印刷する場合は、必ず元のアドレスを指定してください:[http://dongkelun.com/2018/04/05/hadoopClusterConf/](http://dongkelun.com/2018/04/05/hadoopClusterConf/)
序文:##
この記事でインストールおよび構成されているhadoopは分散クラスターです。スタンドアロン構成については、[centos7 hadoopスタンドアロンモードのインストールと構成](http://dongkelun.com/2018/03/23/hadoopConf/)を参照してください。
私が使用する3つのcentos7の場合、最初に共通環境を構成し([CentOS初期環境構成](http://dongkelun.com/2018/04/05/centosInitialConf/))、それぞれIPを設定します:192.168.44.138、192.168.44.139、192.168.44.140、エイリアスmaster、slave1に対応slave2
1、 最初にjdk(私がインストールした1.8)をインストールして構成します##
2、 各仮想マシンのIPに個別の名前を付けます##
各仮想マシンで実行
vim /etc/hosts
下部に追加:
192.168.44.138 master
192.168.44.139 slave1
192.168.44.140 slave2
各仮想マシンにpingを実行して、pingを実行できることを確認します
ping master
ping slave1
ping slave2
3、 SSHパスワードなしのログイン##
3台すべてのマシンがシークレットなしで通信できることを確認してください。[linuxsshsecret free login](http://dongkelun.com/2018/04/05/sshConf/)を参照してください。
3、 ハドゥープをダウンロード(マシンごと)##
ダウンロードリンク:[http://mirror.bit.edu.cn/apache/hadoop/common/](http://mirror.bit.edu.cn/apache/hadoop/common/)、hadoop-2.7.5.tar.gzをダウンロードしました
4、 / optディレクトリ(各マシン、自分の習慣に応じたディレクトリ)に解凍します##
tar -zxvf hadoop-2.7.5.tar.gz -C /opt/
5、 hadoop環境変数を構成します(マシンごと)##
vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.5export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
6、 hadoopの構成(マスターのみ)##
構成ファイルのファイルパスとポートは、独自の習慣に従って構成されます
6.1 スレーブを構成する###
slaves1ファイルのlocalhostを削除する必要があります。今回は、2つのスレーブノードを使用して、マスターをNameNodeとしてのみ使用するか、マスターをNameNodeとDataNodeの両方として使用して、マスターをスレーブに追加できます。
vim /opt/hadoop-2.7.5/etc/hadoop/slaves
slave1
slave2
6.2 hadoop-env.sh ###を構成します
vim /opt/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
検索#使用するjava実装。次の行を次のように変更します。
export JAVA_HOME=/opt/jdk1.8.0_45
6.3 core-site.xml ###を構成します
vim /opt/hadoop-2.7.5/etc/hadoop/core-site.xml
< configuration><property><name>hadoop.tmp.dir</name><value>file:///opt/hadoop-2.7.5</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://master:8888</value></property></configuration>
6.4 hdfs-site.xml ###を構成します
vim /opt/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
dfs.replicationは通常3に設定されていますが、今回は2つのスレーブのみが使用されるため、dfs.replicationの値は2に設定されます。
< configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:50090</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:///opt/hadoop-2.7.5/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:///opt/hadoop-2.7.5/tmp/dfs/data</value></property></configuration>
6.5 構成yarn-site.xml
vim /opt/hadoop-2.7.5/etc/hadoop/yarn-site.xml
< configuration><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
6.6 mapred-site.xml ###を構成します
cd /opt/hadoop-2.7.5/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
< configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
6.7 上記の構成のファイルを他のノードの/opt/hadoop-2.7.5/etc/hadoop/ディレクトリに転送します###
scp -r slaves hadoop-env.sh core-site.xml hdfs-site.xml yarn-site.xml hdfs-site.xml root@slave1:/opt/hadoop-2.7.5/etc/hadoop/
scp -r slaves hadoop-env.sh core-site.xml hdfs-site.xml yarn-site.xml hdfs-site.xml root@slave2:/opt/hadoop-2.7.5/etc/hadoop/

7、 開始と停止(マスターのみ)##
7.1 hdfsの開始と停止###
hdfsを初めて起動するときは、次のようにフォーマットする必要があります。
cd /opt/hadoop-2.7.5./bin/hdfs namenode -format
起動:
. /sbin/start-dfs.sh
やめる:
. /sbin/stop-dfs.sh

検証、ブラウザ入力:http://192.168.44.138:50070
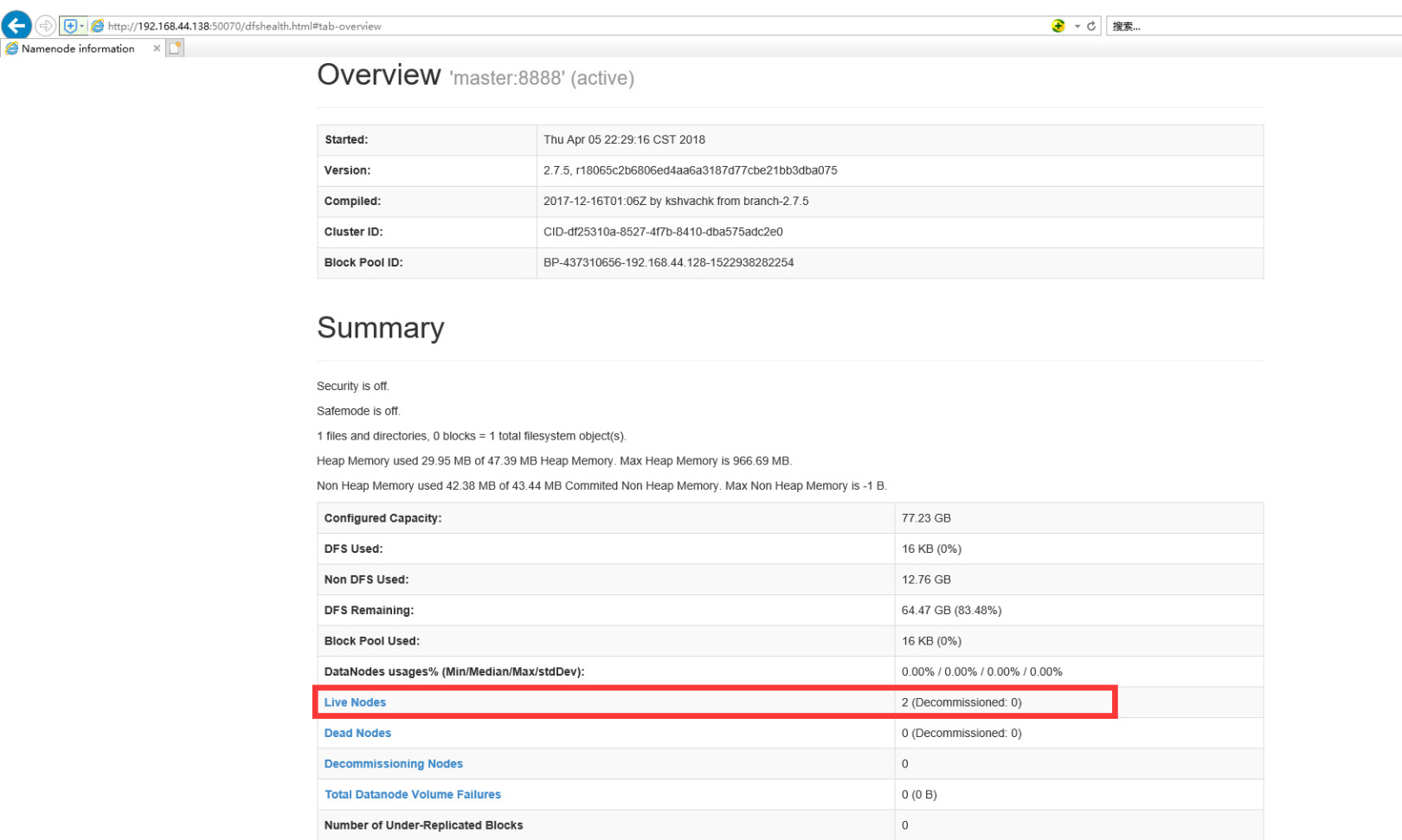
簡単な検証hadoopコマンド:
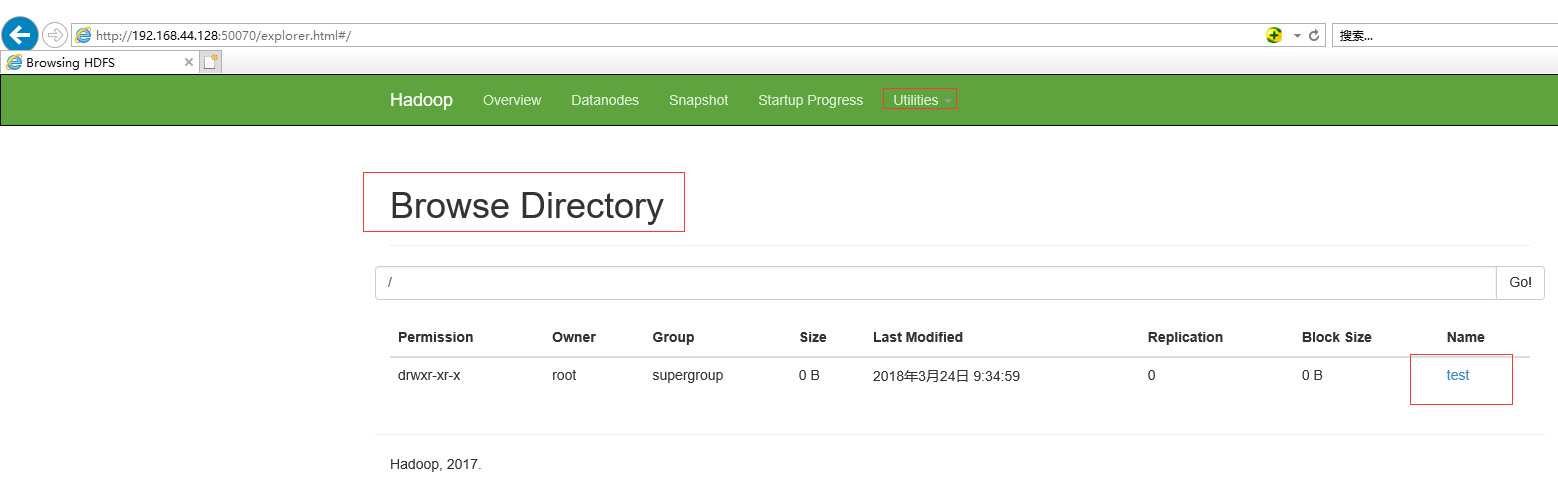
hadoop fs -mkdir /test
ブラウザで確認してください。以下のように表示されれば、成功を意味します。
7.2 糸の開始と停止###
起動:
cd /opt/hadoop-2.7.5./sbin/start-yarn.sh
. /sbin/stop-yarn.sh
ブラウザビュー:http://192.168.44.138:8088

jpsビュープロセス
master:

slave1:

slave2:

各ノードのプロセスが図のようになっている場合、hadoopクラスターは正常に構成されています。
参考文献##
http://www.powerxing.com/install-hadoop-cluster/
Recommended Posts