Pythonガベージコレクションメカニズムの詳細な分析
導入する
ガベージコレクションメカニズムがあるのはなぜですか
Pythonのガベージコレクションメカニズムは(GC)と省略されます。プログラムの実行中にデータを保存するために多数の変数を生成します。一部の変数は使用されなくなり、変数が占めるメモリスペースを解放するためにクリーンアップする必要がある場合があります。一部の比較的低レベルの言語(C言語、アセンブリ言語など)では、メモリスペースの解放はプログラマーが手動で実行する必要があります。基盤となるハードウェアを直接処理するこの種の操作は非常に危険で面倒であり、Cに基づいています。この懸念を解決するために、この言語で開発されたPythonには独自のガベージコレクションメカニズムがあり、開発者はメモリ使用量をあまり気にせずに開発に専念できます。
name ="yunya" #ユンヤは名前を変えるつもりです
name ="yunyaya" #元々、yunyaという名前は使用されていませんが、クリーンアップする必要があります。そうしないと、メモリスペースを占有します。幸い、Pythonのガベージコレクションメカニズムは、クリーンアップに役立ちます。"yunya"
ヒープ領域とスタック領域の概念
Python変数の基本的な原則について以前に書いた記事を読む場合は、ヒープ領域とスタック領域のメモリについてある程度理解している必要があります。まだ読んでいないかどうかは関係ありません。リンクは次のとおりです。
Python変数と基本的なデータタイプ
基礎となる動作原理
参照数
簡単に言えば、参照カウントは、ヒープ領域の変数値にバインドされたスタック領域の変数名をカウントすることです。示されているように:
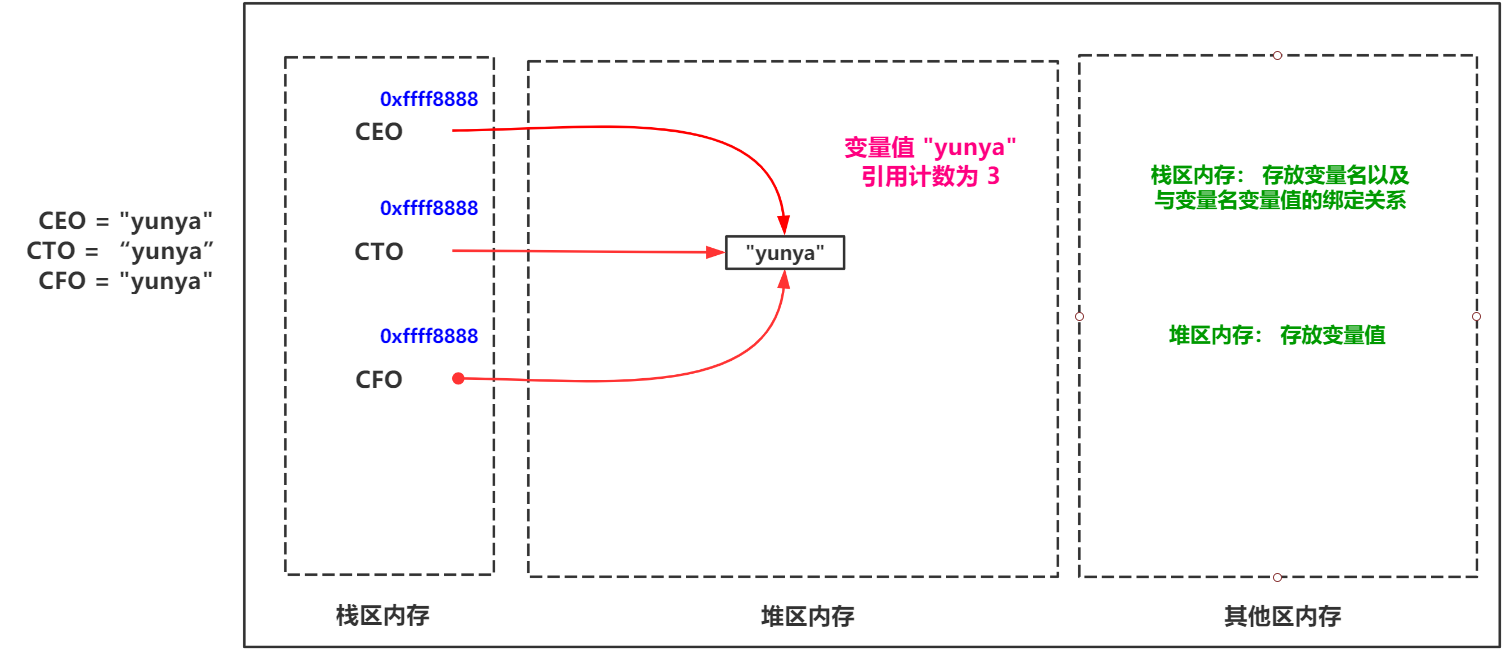
delを使用するか、変数名を再割り当てすると、変数値の参照カウントは-1になります。参照カウントが0の場合、次にPythonメモリリサイクルメカニズムがメモリスキャンを実行すると、変数値はガベージとしてリサイクルされます。
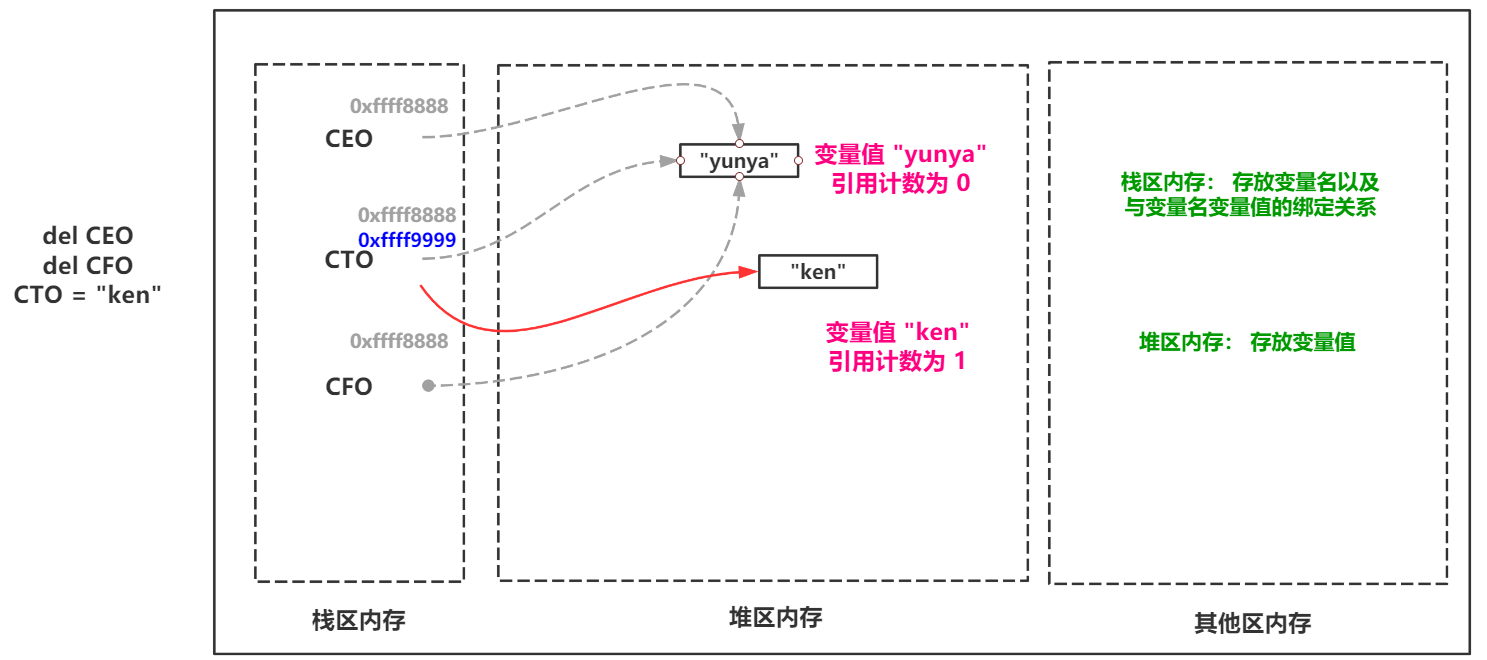
したがって、ここでは、Pythonメモリ回復メカニズムで最も基本的で最も一般的に使用される参照カウントの概要を示します。
循環参照-メモリリーク
参照カウントは、Pythonのメモリ回復メカニズムで最も頻繁に使用されるメカニズムですが、特定の欠点もあります。次のコードを見てみましょう。
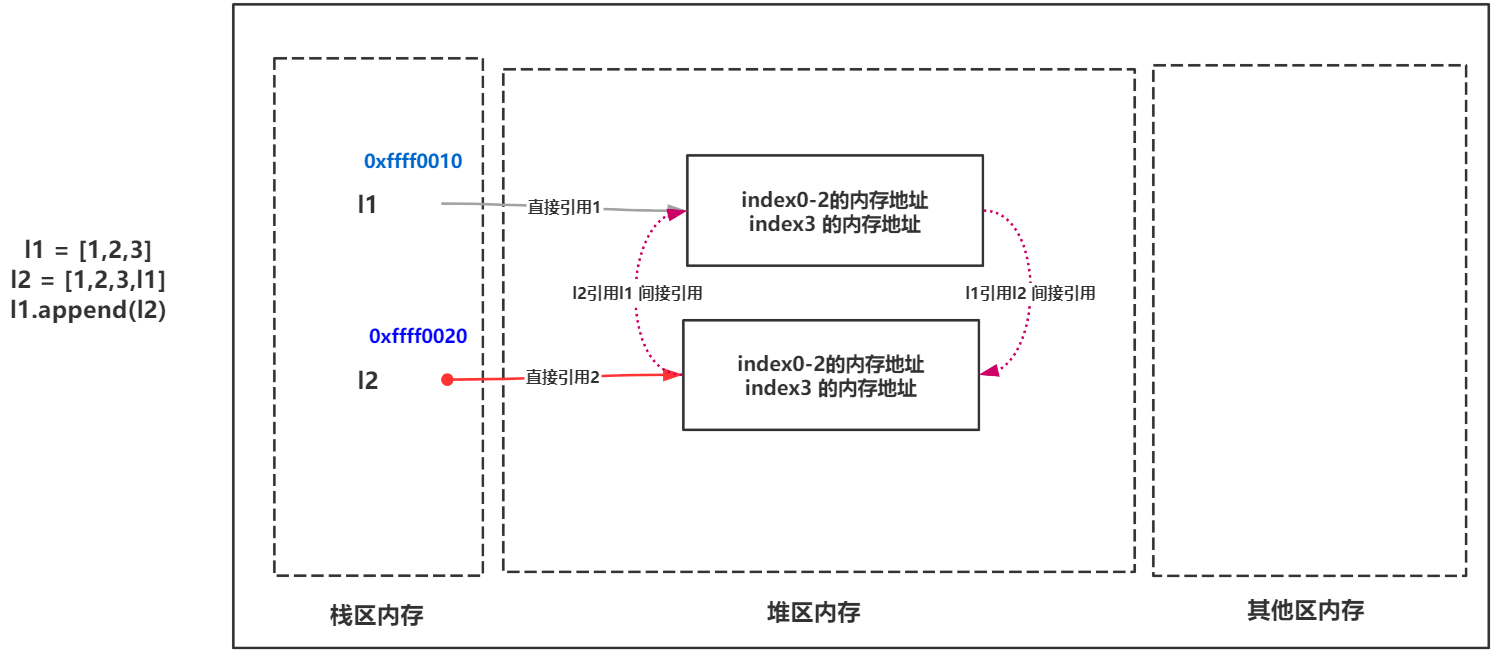
l1 =[1,2,3]
l2 =[1,2,3,l1]
l1.append(l2) #append()メソッドは、要素値をリストに追加するために使用されます
l1
[1,2,3,[1,2,3,[...]]]
l2
[1,2,3,[1,2,3,[...]]]
これで、l1とl2はすべて相互に参照されます。したがって、この種の参照は循環参照(相互参照とも呼ばれます)と呼ばれ、循環参照には問題が発生します。
- l1変数値の参照カウントは現在2です
- l2変数値の参照カウントは現在2です
- dell1とdell2を使用する場合はどうですか?
- それらの参照変数はすべて1減少しますが、参照メソッドの変数名はすべて互いに削除されます。これらの変数値がガベージ変数になるのは当然のことです。参照数だけに基づいてこれらのガベージ変数をクリーンアップすることは不可能です。
del l1
del l2
# 今li1またはli2にアクセスするにはどうすればよいですか?アクセスできませんが、それらの変数値はまだメモリに存在し、参照カウントは2から1に変更されます。
マーククリア
マーククリアとは、アプリケーションの使用可能なメモリスペースが使い果たされると、スタック領域のスキャンを開始し、スタック領域の変数名に沿ってヒープ領域の変数値をマークすることを意味します。ヒープ領域にスタック領域がない場合変数名に対応するデータはガベージデータと見なされ、Pythonガベージコレクションメカニズムによってクリーンアップされます。

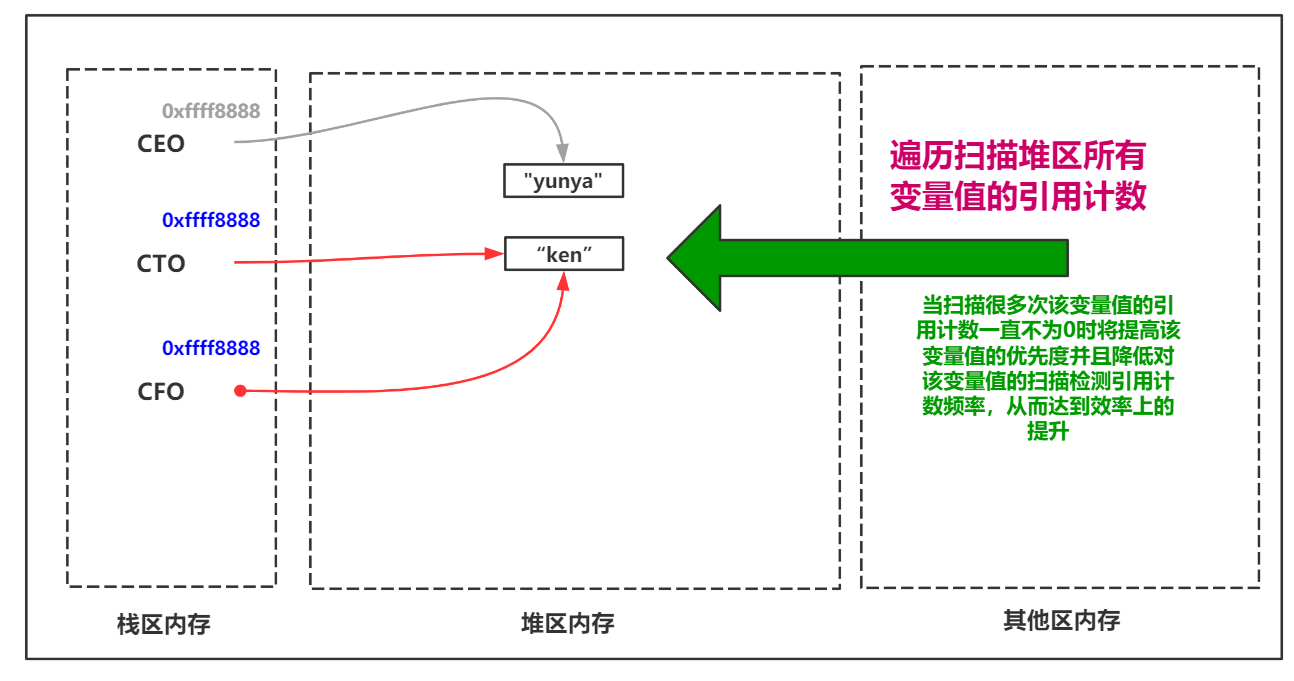
効率問題の解決策-世代別コレクション
参照カウントベースのガベージコレクションメカニズムは、クリーンアップ操作を実行する前に、ヒープ領域全体の変数値の参照カウントをトラバースします。これには非常に時間がかかるため、Pythonのガベージコレクションメカニズムにより、世代別のコレクション戦略が追加され、効率が向上します。
参照
https://www.zalou.cn/article/161474.htm
上記は、Pythonガベージコレクションメカニズムの詳細な分析です。Pythonガベージコレクションメカニズムの詳細については、ZaLou.Cnの他の関連記事に注意してください。
Recommended Posts