09.Python3の共通モジュール
モジュールの定義と分類####
モジュールとは何ですか?#####
関数は関数をカプセル化し、使用するソフトウェアはn個の複数の関数で構成されている場合があります(最初にオブジェクト指向を検討してください)。たとえば、Douyinのソフトウェアでは、すべてのプログラムを1つのファイルに書き込むことはできないため、ファイルを分割して、組織構造を改善し、コードが冗長にならないようにする必要があります。 10個のファイルを追加した後、各ファイルが同じ機能(機能)を持つ可能性があります。どうすればよいですか?したがって、これらの同じ関数をファイルにカプセル化すると、一般的に使用される多くの関数を格納するこのpyファイルがモジュールになります。モジュールはファイルであり、一般的に使用される機能の束を格納します。どうやって入手するの?例:世界の繁栄を分かち合うために馬に乗りたいのですが、どうすればよいですか?私は馬に乗るべきです、あなたは波に行かなければなりません、あなたも馬に乗りたいですか?関数は関数であると言うので、一般的に使用されるいくつかの関数をpyファイルに入れます。このファイルはモジュールと呼ばれます。
モジュールは、一般的に使用される一連の関数のコレクションです。本質はpyファイルです
モジュールを使用する理由#####
-
プログラムをファイルレベルから整理して管理しやすくします。プログラムの開発に伴い、機能が増えています。管理を容易にするために、通常はプログラムをファイルに分割します。こうすることで、プログラムの構造がより明確になり、管理しやすくなります。現時点では、これらのファイルはスクリプトとしてのみ実行でき、機能の再利用を実現するためにモジュールとして他のモジュールにインポートすることもできます。
-
開発効率を上げるために使うだけです。同じ原理で、他の人が書いたモジュールをダウンロードして自分のプロジェクトにインポートすることができます。このような使い方をすると、開発効率が大幅に向上し、重複を避けることができます。ホイール。
モジュール分類#####
Python言語では、モジュールは3つのカテゴリに分類されます
最初のカテゴリ:組み込みモジュール。標準ライブラリとも呼ばれます。このタイプのモジュールは、以前に見たtimeモジュールやosモジュールなど、pythonインタープリターによって提供されます。標準ライブラリには多くのモジュールがあります(200以上、各モジュールには多くの機能があります)
2番目のカテゴリ:サードパーティモジュール、サードパーティライブラリ。 BeautfulSoup、Djangoなど、pythonマスターによって記述されたいくつかの非常に便利なモジュールは、pipinstallコマンドを使用してインストールする必要があります。おそらく6000以上あります。
3番目のカテゴリ:カスタムモジュール、プロジェクトで定義されたいくつかのモジュール
モジュール動作モード#####
# スクリプトモード:通訳で直接実行する,または、PyCharmを右クリックして実行します
# モジュール方式:他のモジュールによってインポートされた,彼のモジュールをインポートするためのリソースを提供する(変数,関数定義,クラス定義など)
__ name__属性の使用#####
# 効果:制御に使用.pyファイルは、さまざまなアプリケーションシナリオでさまざまなロジックを実行します(またはモジュールファイルのテストコード)
# スクリプトモードで実行している場合,__name__固定文字列です:'__main__'
# モジュールとしてインポートする場合,__name__このモジュールの名前です,name値を使用してカスタムモジュールの実行可能ステートメントを実行するかどうかを決定します
カスタムモジュールが他のモジュールによってインポートされると、他の実行可能なステートメントがすぐに実行されます
モジュール検索パス#####
# モジュールを参照するとき,必ずしもすべてをにインポートできるわけではありません
# Pythonリファレンスモジュールは、特定のルールと順序に従って検索されます,このクエリシーケンスは:最初にメモリにロードされているモジュールを検索し、次に組み込みモジュールが見つからない場合は検索します。組み込みモジュールがない場合は、sysに移動します。.パス内のパスに含まれるモジュールを検索します。指定された場所からこの順序でのみ検索します。見つからない場合は、エラーが報告されます。
# モジュールの検索順序
# 1. モジュールを初めてインポートするとき(テストなど_module1),最初に、モジュールがメモリにロードされているかどうかを確認します(現在実行されているファイルの名前名に対応するメモリ),はいの場合、直接見積もります(pythonインタープリターが起動すると、いくつかのモジュールがメモリに読み込まれます。sysを使用できます。.モジュールビュー)
# 2. ない場合,インタプリタは、同じ名前の組み込みモジュールを探します
# 3. 見つからない場合は、sysから.パスで指定されたディレクトリリストでテストを検索します_module1ファイル
# ご了承ください:カスタムモジュールは、システム組み込みモジュールと同じ名前にするべきではありません
モジュールをインポートする多くの方法#####
# import module_demo1はモジュールのすべてのメンバーをインポートします
# import module_demo1,demo2複数のモジュールのメンバーを一度にインポートする
# from***import module_demo3は、指定されたメンバーをモジュールからインポートします
# from***import module_demo3、demo4は、モジュールから指定された複数のメンバーをインポートします
# from***import*指定したすべてのメンバーをモジュールからインポートします
インポートおよびから***import*違い
# 最初の方法:メンバーを使用する場合,モジュール名をプレフィックスとして使用する必要があります,競合に名前を付けるのは簡単ではありません
# 2番目の方法:モジュール名をプレフィックスとして使用せず、メンバー名を直接使用してください,しかし、名前の競合が発生しやすい,後で定義されたメンバーが有効になります(前面を覆った)
# 名前の競合を解決する
# 1. 代わりにimportxxxを使用してインポートします
# 2. 自分で同じ名前を使用することは避けてください
# 3. エイリアスを使用して競合を解決する
# from module1 import demo1 as demo2
# 再度使用する場合はdemo2を使用する必要があります
# カスタムモジュールのモジュールをsysに追加します.道
import os
import sys
sys.path.appdend(os.path.dirname(__file__)+'/module1')
# から使用*import*インポートする方法
# 同じプロジェクトでモジュールを比較的インポートする
from..demo1 import demo2
Time
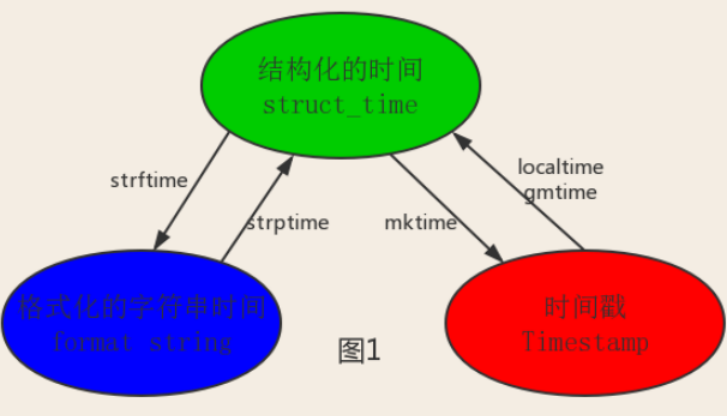
Pythonでは、通常、時間を表現する方法がいくつかあります。
タイムスタンプ(timestamp):一般的に、タイムスタンプは1970年1月1日の00:00:00からのオフセットを秒単位で表します。type(time.time())を実行して、フロートタイプ。
フォーマット文字列
構造化時間(struct_time); struct_timeタプルには、9つの要素(年、月、日、時、分、秒、年の週、および年の日)があります。
Time
import time
#- - - 最初に現在の時刻を見てみましょう,誰もが3つの時間の形をすばやく理解できるようにします
print(time.time()) #タイムスタンプ:1487130156.419527print(time.strftime('[%Y-%m-%d %H:%M:%S]',time.localtime(time.time())))
#フォーマットされた時間文字列:'[2020-01-01 15:46:19]'print(time.sleep(1),'1秒遅延表示') #スレッドの実行を遅らせる
print(time.localtime()) #ローカルタイムゾーンの構造_time
print(time.gmtime()) #UTCタイムゾーン構造_time
# タイムスタンプ(timestamp):time.time()
# スレッドの実行を遅らせる:時間.sleep(secs)
# ( 指定されたタイムスタンプの下)現在のタイムゾーン時間:時間.localtime([secs])
# ( 指定されたタイムスタンプの下)グリニッジ平均時間:時間.gmtime([secs])
# ( 指定された時間のタプルの下で)フォーマット時間:
# time.strftime(fmt[,tupletime])
%y 2桁の年表現(00-99)
%Y 4桁の年表現(000-9999)
%m月(01-12)
%d月の日(0-31)
%24時間形式のH時間(0-23)
%12時間形式で1時間(01-12)
%M分(00=59)
%S秒(00-59)
%ローカルの簡略化された平日の名前
%完全なローカル週の名前
%bローカルで簡略化された月の名前
%B完全な現地月名
%cローカルの対応する日付と時刻の表現
%j年の日(001-366)
%pローカルA.M.またはP.M.同等
%U年の週番号(00-53)日曜日は週の初めです
%w週(0-6)、日曜日は週の初めです
%W週番号(00-53)月曜日は週の初めです
%xローカル対応日付表現
%Xローカル対応時間表現
%Z現在のタイムゾーンの名前
%%%番号自体
その中で、コンピューターが認識する時間は「タイムスタンプ」の形式のみであり、プログラマーが処理できる時間または人間が理解できる時間は、「フォーマットされた時間文字列」、「構造化された時間」などです。次の図の変換関係:
Datetime
稼働時間
# 時間の加算と減算
import datetime
# print(datetime.datetime.now()) #現在の時間2019に戻る-05-1314:27:59.947853
# print(datetime.date.fromtimestamp(time.time())) #タイムスタンプを日付形式2019に直接変換-05-13
# print(datetime.datetime.now())
# print(datetime.datetime.now()+ datetime.timedelta(3)) #現在の時刻+3日
# print(datetime.datetime.now()+ datetime.timedelta(-3)) #現在の時刻-3日
# print(datetime.datetime.now()+ datetime.timedelta(hours=3)) #現在の時刻+3時間
# print(datetime.datetime.now()+ datetime.timedelta(minutes=30)) #現在の時刻+30ポイント
# c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #時間の交換
2020-01-0116:02:42.3277392020-01-0416:02:42.3277392019-12-2916:02:42.3277392020-01-0119:02:42.3277392020-01-0102:03:42.327739
Calendar
カレンダーモジュール
import calendar
# 飛躍年の判断
print(calendar.isleap(2000))
# 特定の年月のカレンダーを表示する
print(calendar.month(2015,2))
# 特定の月の開始週と当月の日数を表示する
print(calendar.monthrange(2015,2))
# 特定の月と年の曜日を表示する
print(calendar.weekday(2015,2,9))
True
February 2015
Mo Tu We Th Fr Sa Su
12345678910111213141516171819202122232425262728(6,28)0 #0は月曜日を意味します
sys
一般的なツールスクリプトは、多くの場合、リンクリストの形式でsysモジュールのargv変数に格納されているコマンドラインパラメータを呼び出します。たとえば、コマンドラインで「pythondemo.py one two three」を実行すると、次の出力が得られます
>>> import sys
>>> print(sys.argv)['demo.py','one','two','three']import sys
arg1 =int(sys.argv[1])
arg2 =int(sys.argv[2])print(arg1+arg2)
エラー出力のリダイレクトとプログラムの終了** sysにはstdin、stdout、stderr属性もあり、stdoutがリダイレクトされた場合でも、後者を使用して警告メッセージとエラーメッセージを表示することもできます**
>>> sys.stderr.write('Warning, log file not found starting a new one\n')
Warning, log file not found starting a newone
# ほとんどのスクリプトは、対象を絞った終了に使用されます"sys.exit()"。
Example1
import sys
print(0)
# sys.exit(0) #操作0printを終了します(123)print(sys.version) #Pythonインタープリタープログラムのバージョン情報を取得する
print(sys.maxsize)print(sys.platform)print(sys.argv) #コマンドラインパラメータリスト、最初のプログラムはプログラム自体のパスです
print(sys.path) #モジュールの検索パスを返し、pythonpath環境変数の値を初期化します
print(sys.platform) #オペレーティングシステムのプラットフォーム名を取得する
print(sys.modules) #ロードされたモジュールを取得します
01233.7.2( tags/v3.7.2:9a3ffc0492, Dec 232018,22:20:52)[MSC v.191632bit(Intel)]2147483647
win32
[' g:\\VSPython\\Day01\\Demo.py']['g:\\VSPython\\Day01',`c:\\Users\\youmen\\.vscode.python-2019.11.50794\\pythonFiles, `
OS
OSモジュールは、オペレーティングシステムに関連する機能以上のものを提供します
import os
os.mkdir('a') #現在のディレクトリにディレクトリaを作成します
os.removedirs('a') #削除されたディレクトリは空のディレクトリである必要があります
os.makedirs('/opt/youmen/zhou') #マルチレベルディレクトリを生成する
os.rename("/opt/youmen","/opt/jian") #名前を変更
print(os.getcwd()) #作業ディレクトリに戻る
os.chdir('/server/accesslogs') #失われた現在のジョブを変更する
os.listdir('/root/Python3') #ディレクトリ内のすべてのリソースを一覧表示します
os.sep #パスセパレータ
os.linesep #ラインターミネータ
os.pathsep #ファイルセパレータ
os.name #オペレーティングシステム名
os.environ #オペレーティングシステム環境変数
os.system('sh /root/Python3/demo1.sh') #シェルスクリプトを実行する
os.system('mkdir today') #システムコマンドmkdirを実行します
shutdown:操作権限を持つファイル処理モジュール****このモジュールは、主に日常のファイルおよびディレクトリ管理タスク用です。modshutilモジュールは、使いやすい高レベルのインターフェイスを提供します
# 通常、osライブラリを使用してフォルダを削除してから、osを使用します.remove(path)、空でないフォルダを削除する場合は、osを使用してください.removedirs(path)できる,
# ただし、フォルダ全体を削除し、フォルダが空でない場合は、osを使用してください.removedirs(path)エラーを報告します、
# 現時点では、組み込みのpythonライブラリであり、ファイルやフォルダの高度な操作用のライブラリであるshutilライブラリを使用できます。
# osライブラリをいくつかの操作に補完することができます。フォルダが全体として割り当てられている場合、フォルダが移動されている場合、ファイルの名前が変更されている場合などです。.import os
import shutil
os.remove(path) #ファイルの削除
os.removedirs(path) #空のフォルダを削除する
shutil.rmtree(path) #フォルダを再帰的に削除する
Example1
import shutil
# パスベースのファイルコピー:
# shutil.copyfile('/opt/zhou','/root/Python3/jian.txt')
# ストリームベースのファイルコピー:
# withopen('source_file','rb')as r,open('target_file','wb')as w:
# shutil.copyfileobj(r,w)
# ファイルの移動
# shutil.remove('/jian.txt','/tmp/')
# フォルダー圧縮
# etc:圧縮後のファイル名,圧縮形式のサフィックスを追加します:
# 圧縮形式のアーカイブ_path:'tar','zep'
# 圧縮するフォルダのパス:/etc
shutil.make_archive('etc','tar','/etc/')
# etc.tar:解凍したファイルなど:解凍後のファイル名tar:解凍フォーマット
shutil.unpack_archive('etc.tar','etc','tar')
データ圧縮
>>> import zlib
>>> s = b'witch which has which witches wrist watch'>>>len(s)41>>> t = zlib.compress(s)>>>len(t)37>>> zlib.decompress(t)
b'witch which has which witches wrist watch'>>> zlib.crc32(s)226805979
osパスシステムパス操作
import os
print(__file__) #実行可能ファイルの現在のパス.print(os.path.abspath('/root/Python3')) #パスの正規化された絶対パスを返します
print(os.path.split('/root/Python3/python_os_demo.py')) #パスをディレクトリとファイル名の2つのタプルに分割し、
print(os.path.dirname('/root/Python3')) #上位ディレクトリ
print(os.path.basename('/root/Python3')) #最終レベル名
print(os.path.exists('/root/Python3')) #指定されたパスが存在するかどうか
print(os.path.isabs('root/')) #絶対パスかどうか
print(os.path.isfile('/root/Python3/demo1.sh')) #それはファイルですか
print(os.path.isdir('/root/')) #それは道ですか
print(os.path.getatime('/root/Python3/demo1.sh')) #最終変更時刻
print(os.path.getsize('/root/Python3/demo1.sh')) #ターゲットサイズ
python3 python_mode_os_demo.py
python_mode_os_demo.py
/root/Python3('/root/Python3','python_os_demo.py')
# LinuxおよびMacプラットフォームでは、この関数はパスをそのまま返します,Windowsプラットフォームでは、パス内のすべての文字が小文字に変更され、スラッシュがバックスラッシュに変換されます
/root
Python3
True
False
True
True
1577869829.14143
random
# それは本当のランダムな数字ではありません、当局はそれがただの疑似ランダムな数字だと言います
import random
print(random.random()) #0より大きく1より小さい10進数
print(random.randint(1,10000)) #1より大きく10000未満の整数
print(random.choice([1,'3241',[800,1000]])) #1または3241または[800,100]print(random.sample([1,'123',[5,10]],2)) #リスト要素の任意の2つの組み合わせ
print(random.uniform(1,55)) #1より大きく55未満の10進数
# 単列コレクションをシャッフルする
item=[1,3,5,7,9]
random.shuffle(item) #アイテムの順序を乱すことは、「シャッフル」と同等です
print(item)print(random.choice(item))print(random.sample(item,3))
Example1
import random
print(random)for i inrange(5):print('%.5f'% random.uniform(1,10))7.389971.145857.781266.836863.66459
検証コード #####
**方法1 **
import random
def get_code(count):
code =""
# 大文字と小文字の文字と数字を生成できます
# ストリングスプライシングを実行します
for i inrange(count):
c1 =chr(random.randint(65,90))
c2 =chr(random.randint(97,122))
c3 =str(random.randint(0,9))
code += random.choice([c1, c2, c3])return code
print(get_code(18))
jqc612fP8s2oFHn4Tw
**方法2 **
import random
def get_code(count):
code=""
# 大文字と小文字の文字と数字を生成できます
# 文字列を連結する
for i inrange(count):
r = random.choice([1,2,3])if r ==1:
c =chr(random.randint(10,50))
elif r ==2:
c =chr(random.randint(50,100))else:
c =str(random.randint(0,9))
code += c
return code
print(get_code(10))
684 K#01)c
**方法3 **
import random
def get_code(count):
target ="1234567890QWERTYUIOPASDFGHJKLZXCVBNMqwer"
code_list = random.sample(target,count)return''.join(code_list)print(get_code(6))
3 KqHXC
シリアル化####
プログラムには、ログイン時と登録時に使用されるこのdicデータを使用する必要がある場所がいくつかあります。そのため、以前にこのdicをグローバルで作成しましたが、これは不合理です。保存場所(データベースを学習していない)に書き込み、最初にファイルに保存してから、プログラムで必要なデータをどこに保存する必要があります。 、ファイルを読んで、必要な情報を取り出すだけです。 **それで問題はありますか? **この辞書を直接ファイルに書き込むことはできません。文字列形式に変換する必要があります。また、読み取る辞書も文字列形式です(コードを使用して表示できます)。
では、str(dic)を取得する用途は何ですか? dicに変換できないので(evalを使わないのは危険です)、とても不便です。このとき、シリアル化モジュールが機能します。ファイルに書き込んだ文字列がシリアル化後の特別な文字列である場合は、ファイルから読み取るときに、元のデータ構造に変換して戻すことができます。 。これはかなり素晴らしいです。
以下はjsonのシリアル化についてですが、pickleのシリアル化は異なります。
jsonシリアル化は、ファイルの書き込みの問題を解決するだけでなく、ネットワーク送信の問題も解決できます。たとえば、リストデータ構造をネットワーク経由で別の開発者に送信する場合、直接送信することはできません。前に述べたように、送信する場合は、バイトタイプを使用する必要があります。ただし、バイトタイプは文字列タイプでのみ変換でき、他のデータ構造で直接変換することはできないため、decode(で、リスト--->文字列--->バイトを送信し、受信後に相手に送信することしかできません。 )元の文字列にデコードします。現時点では、この文字列は元に戻すことができないため、以前に学習した種類のstr文字列にすることはできません。特殊な文字列の場合は、リストに逆にして、開発者がネットワークを使用してデータを交換できるようにすることができます。開発者間だけではありません。データをクロールするにはWebを使用する必要があります。ほとんどのデータはこの種の特別な文字列です。受信後、必要なデータタイプに戻すことができます。
# シリアル化とは?
# シリアル化とは、メモリ内のデータタイプを別の形式に変換することです。
# これは:
# 辞書---->シリアル化---->他のフォーマット---->ハードドライブに保存
# ハードディスク---->読んだ---->他のフォーマット---->デシリアライズ----->辞書
# なぜシリアル化するのですか?
# 1. プログラムの実行状態を永続的に保存します.
# 2. データのクロスプラットフォーム相互作用
# Pythonには3種類のシリアル化モジュールがあります:
# jsonモジュール
# 1.さまざまな言語は、さまざまな言語で使用される特別な文字列であるデータ変換形式に従います,(たとえば、Pythonのリスト[1,2,3]jsonを使用して特別な文字列に変換し、バイトにエンコードしてphp開発者に送信します。php開発者はそれを特別な文字列にデコードしてから、元の配列に戻すことができます。(リスト):[1,2,3])
# 2.jsonシリアル化は、一部のPythonデータ構造のみをサポートします,一重引用符を認識できず、コレクションがありません: dict,list,tuple,str,int,float,True,False,None
# 3.同じファイルを複数回シリアル化することはできず、言語をまたぐことができます
# ピクルスモジュール
# 1.これは、データ変換形式とそれに続くPython言語のみにすることができます,Python言語でのみ使用できます,言語を越えることはできません
# 2.インスタンス化されたオブジェクトを含むすべてのPythonデータタイプをサポートします
# 棚モジュール
# 1.特別な文字列を操作する辞書操作に似ています
# シリアル化とは:オブジェクトを文字列に変換する
# デシリアライズとは:文字列をオブジェクトに変換する
# シリアル化の理由:データの保存と送信は両方とも文字列タイプです
# シリアル化されたモジュール:jsonピクルシェルフ
# シリアル化:メモリ内のデータを文字列に変換します,用以保存在文件或通过网络传输,称为シリアル化过程.
# デシリアライズ:ファイルから,网络中获取的数据,转换成内存中原来的数据类型,称为デシリアライズ过程.
# json:データ送信に使用されるクロスランゲージをサポート
# pickle:pyのすべてのデータタイプをサポートし、すべてのpyオブジェクトをシリアル化して保存できます
# shelve:pyのすべてのデータタイプをサポートし、即座に保存および取得できます
# シリアル化
dump
dumps
# デシリアライズ
load
loads
Json
送信用(多言語サポート)
- Jsonとは:テキストのシリアル化を完了して取得したテキスト文字列です。JSON文字列には特定の文法仕様があります。
# jsonモジュールは、条件を満たすデータ構造を特別な文字列に変換します,そして、逆シリアル化して元に戻すことができます
# ネットワーク伝送用: dumps,loads
# ファイルの書き込みと読み取り用: dump,load
# 1. サポートされているデータタイプ:int float str bool dict list null
# 2. 複雑なjsonはで構成されています{}対[]ネストされたデータ
# 3. json文字列は1つのルートのみを持つことができます: json_str ='{}{}'|'{}[]'|'[][]'|'1null' #エラー、両方のルート
# 4. jsonのstrタイプを使用する必要があります""パッケージ(json文字列の文字列タイプはサポートされていません''"""""")
` さらに、msgpackはjsonと同じシリアル化パッケージですが、シリアル化後、データは小さく、圧縮され、効率はJsonよりも高速ですが、データベースではredisのみがサポートし、他のパッケージはサポートしません。
Example1
import json
a =12345
s = json.dumps(a)print(type(s),s)withopen('a.txt',mode='wt',encoding='utf-8')as f:
f.write(s)
# Pythonオブジェクトのシリアル化json文字列
date = None
res = json.dumps(date)print(res)
# json文字列逆シリアル化pythonオブジェクト
json_str ='3.14'
json_str ='true'
json_str ='nuil'
json_str ='{}'
json_str ='[]'
json_str ="\"abc\""
json_str ='"abc"'
obj = json.loads(json_str)print(obj,type(obj))
# エラー、2つのルート
# json_str ='1,null'null
abc <class'str'>
# シリアル化する必要のあるオブジェクトは、ファイルの書き込みメソッドを使用して、複数回シリアル化されます。
# 複数のシリアル化されたjson文字列をファイルに書き込みます.withopen('json.txt',mode='at',encoding='utf-8')as f:
f.write(json.dumps([1,2,3,4])+'\n')
f.write(json.dumps([1,2,3,4])+'\n')withopen('json.txt',mode='rt',encoding='utf-8')as f:for x in f:print(json.loads(x.strip()))
Example2
import json
# シリアル化
obj ={'name':"Owen","age":17,"gender":'男性'}withopen('a.txt','w',encoding='utf-8')as wf:
json.dump(obj,wf,ensure_ascii=False)
# デシリアライズ
withopen('a.txt','r',encoding='utf-8')as rf:
obj = json.load(rf)print(obj)print(json.load(open('a.txt','r',encoding='utf-8')))
# jsonモジュールのシリアル化と逆シリアル化には1対1の対応があります
{' name':'Owen','age':17,'gender':'男性性'}{'name':'Owen','age':17,'gender':'男性性'}
pickle
すべてのデータタイプをサポート
import pickle
# シリアル化
obj ={'name':'Owen','age':17,'gender':'男性'}
rgs = pickle.dumps(obj)print(rgs)
pickle.dump(obj,open('b.txt','wb'))
# デシリアライズ
print(pickle.loads(rgs))print(pickle.load(open('b.txt','rb')))
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\3\x00\x00\x00\xe7\x94\xb7q\x05u.'{'name':'Owen','age':17,'gender':'男性性'}{'name':'Owen','age':17,'gender':'男性性'}
shelve
すべてのデータタイプ、インスタントアクセスをサポート
import shelve
shv_tool = shelve.open('c.shv')
# シリアル化
shv_tool['name']='Owen'
# デシリアライズ
res = shv_tool['name']print(res)
# ファイルはshelveオブジェクトを介して閉じられます
# writebockは、データをメモリに逆シリアル化し、操作の直後にファイルに同期します
with shelve.open('c.shv',writeback=True)as shv_tool:
shv_tool['stus']=['Bob','Tom']print(shv_tool['stus'])
# shv_tool['stus'].append['Jobs']
# print(shv_tool['stus'])
Owen
[' Bob','Tom']
暗号化####
# 暗号化のためにいくつかのクラスをカプセル化する
# 暗号化の目的:復号化ではなく、判断と検証に使用されます
# 特徴:
# 大きなデータをさまざまな部分に分割する,異なるブロックを個別に暗号化する,結果は再び要約され、結果はデータ全体を直接暗号化した結果と一致しています。.
# 一方向の暗号化、不可逆
# 元のデータの小さな変更,結果に非常に大きな違いが生じます,'雪崩'
hashlib
# このモジュールはダイジェストアルゴリズムと呼ばれ、暗号化アルゴリズムまたはハッシュアルゴリズムとも呼ばれます,主に暗号化と検証に使用され、動作原理:関数を使用して、特定のルールに従って任意の長さのデータを固定長のデータ文字列に変換します(通常、16進文字列で表されます)
# 一部のデータがネットワーク上で送信され、それがプレーンテキストであり、誰かがデータを盗んだ場合、セキュリティリスクが発生します,暗号化すると、ハイジャックされたとしても、意味のあるデータを簡単に解読してデータのセキュリティを確保することはできません。
# hashlibモジュールはこの機能を完了します
# 1. パスワードの暗号化
# 2. ファイルの整合性チェック
# hashlibの機能と使用の重要なポイント:
# 1. バイトタイプデータ--->hashlibアルゴリズムを介して--->固定長文字列
# 2. 異なるバイトタイプのデータ変換の結果は異なる必要があります。
# 3. 同じバイトタイプのデータ変換の結果は同じでなければなりません。
# 4. この変換プロセスは元に戻せません。
# 暗号化されたオブジェクトを取得する
m = hashlib.md5()
# 暗号化されたオブジェクトの更新を使用して暗号化する
m.update('中国語で「abc」'.encode('utf-8'))
# m.update(b'中国語で「abc」')
result = m.hexdigest()print(result)import hashlib
date ='データ'
lock_obj = hashlib.md5(date.encode('utf-8')) #暗号化されたオブジェクトを作成し、暗号化されたデータを渡します
result = lock_obj.hexdigest() #暗号化された文字列を取得する
print(result)
# 塩で
# 塩とは:元のデータの前後に所定のデータを追加し、元のデータと一緒に暗号化します.
# なぜ塩を加えるのか.
# 1. 元のデータが単純すぎる場合は、それに塩を追加してデータの複雑さを増すことができます.
# 2. 塩とデータにはある程度の類似性があります,混乱は本当にデータ抽出です.
lock_obj= hashlib.md5() #プロダクションロックオブジェクトは、データパラメータを追加したり、省略したりできます.
lock_obj.update(b'beforce_salt')
lock_obj.update('暗号化するデータ'.encode('utf-8'))
lock_obj.update(b'after_salt')print(lock_obj.hexdigest())
# 新しいデータの暗号化を提供するには、そのデータの暗号化オブジェクトを作成する必要があります.
# その他のアルゴリズム
lock_obj = hashlib.sha3_256(b'123')print(lock_obj.hexdigest())
lock_obj = hashlib.sha3_512(b'123')
lock_obj.update(b'salt')print(lock_obj.hexdigest())
# hmacモジュール
import hmac
# hoshLibとの違いは、ロックオブジェクトを生成するときにデータパラメータを増やす必要があることです。
lock_obj = hmac.new(b'')print(lock_obj.hexdigest())
lock_obj = hmac.new(b'')
lock_obj.update(b'salt')print(lock_obj.hexdigest())
Example
# 登録、ログイン手順
import hashlib
def get_md5(username,passwd):
m = hashlib.md5()
m.update(username.encode('utf-8'))
m.update(passwd.encode('utf-8'))return m.hexdigest()
def register(username,passwd):
# 暗号化
result =get_md5(username,passwd)
# ファイルを書き込む
withopen('login',mode='at',encoding='utf-8')as f:
f.write(result)
f.write('\n')
def login(username,passwd):
# 現在のログインの暗号化結果を取得します
result =get_md5(username,passwd)withopen('login',mode='rt',encoding='utf-8')as f:for line in f:if result == line.strip():return True
else:return False
while True:
op =int(input('1.登録2.ログイン3.脱落'))if op ==3:break
elif op ==1:
username =input('ユーザー名を入力して下さい:')
passwd =input('パスワードを入力する')register(username,passwd)
elif op ==2:
username =input('ユーザー名を入力して下さい')
passwd =input("パスワードを入力する")
result =login(username,passwd)if result:print('ログイン成功')else:print('ログインに失敗しました')
collection
組み込みのデータタイプ(dict、list、set、tuple)に基づいて、collectionsモジュールはいくつかの追加のデータタイプも提供します。
Counter、deque、defaultdict、namedtuple、OrderdDictなど。
# 1. namedtuple:名前を使用して要素のコンテンツにアクセスできるタプルを生成します
# 2. deque:Deque,反対側からオブジェクトをすばやく追加および排出できます
# 3. Counter:カウンター,主にカウントに使用されます
# 4. OrderedDict:注文した辞書
# 5. defaultdict:デフォルト値の辞書
namedtuple
タプルは不変のセットを表すことができることがわかっています。たとえば、ポイントの2次元座標は次のように表すことができます。
# p =(1,2)
# しかし、見て(1,2),このタプルがどのように座標を表すかを理解するのは難しいです.
# 現時点では,namedtupleが重宝します
from collections import namedtuple
Point =namedtuple('Point',['x','y'])
p =Point(1,2)print(p.x)print(p.y)
deque
リストを使用してデータを保存する場合、要素の検索とアクセスは高速ですが、リストは線形に保存されるため、要素の挿入と削除は非常に遅く、データ量が多い場合、挿入と削除の効率は非常に低くなります。
dequeは、効率的な挿入および削除操作のための双方向リストであり、キューとスタックに適しています
from collections import deque
q =deque(['a','b','c'])
q.append('x')
q.appendleft('y')print(q)
# deque(['y','a','b','c','x'])
# リスト追加の実装に加えて()そしてポップ()さらに、appendleftもサポートされています()そしてポップleft(),このようにして、要素を非常に効率的に追加または削除できます
orderddict
dictを使用する場合、キーは順序付けられていません。dictの反復を行う場合、キーの順序を判別できません。
キーの順序を維持する必要がある場合は、Orderddictを使用できます
from collections import OrderedDict
d =dict([('a',1),('b',2)])print(d)
od =OrderedDict([('a',1),('b',2)])print(od['a'])
# {' a':1,'b':2}
# 1
defaultdict
# 次の値セットで[11,22,33,44,55,66,77]、66より大きいすべての値を辞書の最初のキーに保存し、66未満の値を2番目のキーの値に保存します
li =[11,22,33,44,55,77,88,99,90]
result ={}for row in li:if row >66:if'key1' not in result:
result['key1']=[]
result['key1'].append(row)else:if'key2' not in result:
result['key2']=[]
result['key2'].append(row)print(result)from collections import defaultdict
values =[11,22,33,44,55,66,77,88,99,90]
my_dict =defaultdict(list)for value in values:if value>66:
my_dict['k1'].append(value)else:
my_dict['k2'].append(value)
# dictを使用する場合、インポートされたキーが存在しない場合、キーエラーがスローされます,キーを存在させたくない場合,デフォルト値を返す,defaultdictを使用できます
>>> from collections import defaultdict
>>> dd =defaultdict(lambda:'N/A')>>> dd['key1']='abc'>>> dd['key1'] #key1が存在します
' abc'>>> dd['key2'] #key2が存在しない場合、デフォルト値に戻ります
' N/A'
counter
Counterクラスの目的は、値の出現回数を追跡することです。これは順序付けられていないコンテナタイプであり、辞書のキーと値のペアの形式で格納されます。ここで、要素はキーであり、カウントは値です。カウント値は、任意のInterger(0および負の数を含む)にすることができます。 Counterクラスは、他の言語のバッグまたはマルチセットと非常によく似ています。
c =Counter('abcdeabcdabcaba')print(c)Counter({'y':2,'n':2,'o':1,'u':1,'m':1,'e':1,'f':1,'l':1,'i':1,'g':1})
re
レギュラーは、いくつかのシンボルを特別な意味(レギュラー式と呼ばれる)と組み合わせて、文字または文字列を記述する方法です。
言い換えると、Regularは、物事のクラスのルールを記述するために使用されます。(Pythonでは)Pythonに埋め込まれ、reモジュールによって実装されます。Regular式パターンは一連のバイトコードにコンパイルされ、Cで記述されます。マッチングエンジンが実行されます。
| メタキャラクター | 一致するコンテンツ |
|---|---|
| \ w | 一致する文字(中国語を含む)または数字または下線 |
| \ W | 文字以外(中国語を含む)または数字または下線に一致 |
| \ s | 任意の空白に一致 |
| \ S | 空白以外の文字と一致します |
| \ d | 一致番号 |
| \ D | 数字以外に一致 |
| \ A | 文字列の先頭から一致 |
| \ z | 文字列の終わりに一致します。新しい行の場合は、新しい行の前の結果のみが一致します |
| \ n | 新しい行の文字に一致します |
| \ t | タブ文字に一致 |
| ^ | 文字列の先頭に一致 |
| $ | 文字列の終わりに一致 |
| . | 新線文字以外の任意の文字に一致します。re.DOTALLタグを指定すると、新線文字を含むすべての文字に一致します。 |
| [...] | 文字グループの文字を一致させる |
| [^...] | 文字グループ内の文字を除くすべての文字に一致する |
| * | 左側の0文字以上に一致します。 |
| 左側の1つ以上の文字に一致します。 | |
| ? | 左の0文字または1文字に一致し、貪欲ではありません。 |
| { n} | n個の前の式と完全に一致します。 |
| { n、m} | 前の正規式で定義されたフラグメントをn回からm回、貪欲に一致させる |
| a | b |
| () | 括弧内の式に一致し、グループも表します |
一致するパターンの例#####
import re
# \ wと\W
# \ wは文字(中国語を含む)または数字または下線に一致します
# \ Wは、文字以外(中国語を含む)または数字または下線に一致します
print(re.findall('\w','YoumenYOUMEN() _ '))print(re.findall('\W','YoumenYOUMEN() _ '))
# [' 静か','夢','y','o','u','m','e','n','Y','O','U','M','E','N','_']
# ['(',')',' ',' ',' ',' ']
# \ 砂\S
# \ sは任意の空白に一致します
# \ Sは空白以外の文字と一致します
print(re.findall('\s','YoumenYOUMEN() _ '))print(re.findall('\S','YoumenYOUMEN() _ '))
# [' ',' ',' ',' ']
# [' 静か','夢','y','o','u','m','e','n','Y','O','U','M','E','N','(',')','_']
# \ dと\D
# \ dマッチ番号
# \ Dは数字以外に一致します
print(re.findall('\d','Youmen 1234youmenYOUMEN() _ '))print(re.findall('\D','Youmen 1234youmenYOUMEN() _ '))
# ['1','2','3','4']
# [' 静か','夢','y','o','u','m','e','n','Y','O','U','M','E','N','(',')',' ','_',' ',' ',' ']
# \ Aと^
# \ 文字列の先頭からの一致
# \^ 文字列の先頭に一致する
print(re.findall('\アヨウ','Youmen 1234youmenYOUMEN() _ '))print(re.findall('\^静か','Youmen 1234youmenYOUMEN() _ '))
# [' 静か']
# []
# \ Z, \zと$
# \ Zは文字列の末尾に一致します。これが新しい行の場合、新しい行が一致する前の結果のみが一致します。
# \ zは文字列の末尾に一致します。これが新しい行の場合、新しい行が一致する前の結果のみが一致します。
# $文字列の終わりに一致する
print(re.findall('123\Z','Youmen 1234youmenYOUMEN() _ \n123'))print(re.findall('123\Z','Youmen 1234youmenYOUMEN() _ \n123'))print(re.findall('123$','Youmen 1234youmenYOUMEN() _ \n123'))
# ['123']
# ['123']
# ['123']
# \ nと\t
print(re.findall('\n','Youmen 1234youmenYOUMEN()\t _ \n123'))print(re.findall('\t','Youmen 1234youmenYOUMEN()\t _ \n123'))
# ['\ n']
# ['\ t']
# 重複一致
# .?*+{ m,n}.*.*?
# . 新行文字を除くすべての文字に一致します(.このパラメータは一致する可能性があります\n)。
# print(re.findall('a.b','ab aab a*ba2b牛ba\nb')) # ['aab','a*b','a2b','牛b']
# print(re.findall('a.b','ab aab a*ba2b牛ba\nb',re.DOTALL)) # ['aab','a*b','a2b','牛b']
# ?左の文字で定義された0または1のセグメントに一致します。
# print(re.findall('a?b','ab aab abb aaaab a cow b aba**b'))
# [' ab','ab','ab','b','ab','b','ab','b']
# * 0個以上の左の文字式に一致します。貪欲な試合@@
# print(re.findall('a*b','ab aab aaab abbb'))
# [' ab','aab','aaab','ab','b','b']
# print(re.findall('ab*','ab aab aaab abbbbb'))
# [' ab','a','ab','a','a','ab','abbbbb']
# + 1つ以上の左の文字式に一致します。貪欲な試合@@
# print(re.findall('a+b','ab aab aaab abbb'))
# [' ab','aab','aaab','ab']
# { m,n}mをn個の左の文字式に一致させます。貪欲な試合@@
# print(re.findall('a{2,4}b','ab aab aaab aaaaabb'))
# [' aab','aaab']
# .* 最初から最後まで貪欲なマッチング.
# print(re.findall('a.*b','ab aab a*()b'))
# [' ab aab a*()b']
# .*? 現時点では?左の文字と0回または1回一致しません,
# しかし、.*この貪欲なマッチングパターンは限られています:貪欲でないマッチングの推奨に従うように彼に言います!
# print(re.findall('a.*?b','ab a1b a*()b, aaaaaab'))
# [' ab','a1b','a*()b']
# []: 括弧内には任意の文字を入れることができます,括弧は文字を表します
# - に[]中は範囲を意味します,一致させたい場合-次にこれ-符号不能放に中间.
# ^ に[]否定を意味する.
# print(re.findall('a.b','a1b a3b aeb a*b arb a_b'))
# [' a1b','a3b','a4b','a*b','arb','a_b']
# print(re.findall('a[abc]b','aab abb acb adb afb a_b'))
# [' aab','abb','acb']
# print(re.findall('a[0-9]b','a1b a3b aeb a*b arb a_b'))
# [' a1b','a3b']
# print(re.findall('a[a-z]b','a1b a3b aeb a*b arb a_b'))
# [' aeb','arb']
# print(re.findall('a[a-zA-Z]b','aAb aWb aeb a*b arb a_b'))
# [' aAb','aWb','aeb','arb']
# print(re.findall('a[0-9][0-9]b','a11b a12b a34b a*b arb a_b'))
# [' a11b','a12b','a34b']
# print(re.findall('a[*-+]b','a-b a*b a+b a/b a6b'))
# [' a*b','a+b']
# - に[]中は範囲を意味します,一致させたい場合-次にこれ-符号不能放に中间.
# print(re.findall('a[-*+]b','a-b a*b a+b a/b a6b'))
# [' a-b','a*b','a+b']
# print(re.findall('a[^a-z]b','acb adb a3b a*b'))
# [' a3b','a*b']
# 運動:
# 文字列を見つける'alex_sb ale123_sb wu12sir_sb wusir_sb ritian_sb'Alex wusir ritian
# print(re.findall('([a-z]+)_sb','alex_sb ale123_sb wusir12_sb wusir_sb ritian_sb'))
# グループ化:
# () ルールを作る,ルールを満たす結果を一致させる
# print(re.findall('(.*?)_sb','alex_sb wusir_毎日sb_sb')) # ['alex',' wusir','毎日']
# 応用例:
# print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">クリック</a>'))#['http://www.baidu.com']
# | 左または右に一致
# print(re.findall('alex|タイバイ|wusir','alexタイバイwusiraleeeex太タイバイodlb')) # ['alex','タイバイ','wusir','タイバイ']
# print(re.findall('compan(y|ies)','Too many companies have gone bankrupt, and the next one is my company')) # ['ies','y']
# print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company')) # ['companies','company']
# グループ化()加える?:ただではなく全体に一致することを意味します()中身。
一般的な方法の場合#####
import re
#1 findallはすべてを検索し、リストを返します。
# print(relx.findall('a','alexwusirbarryeval')) # ['a','a','a']
# 2 検索は最初の一致のみを検索し、一致情報を含むオブジェクトを返します,オブジェクトはグループと呼ぶことができます()一致した文字列を取得するメソッド,文字列が一致しない場合、Noneが返されます。
# print(relx.search('sb|alex','アレックスSBSBバリー毎日'))
# <_ sre.SRE_Match object; span=(0,4), match='alex'>
# print(relx.search('alex','アレックスSBSBバリー毎日').group())
# alex
# 3 match:None,検索と同じ,ただし、文字列の先頭で一致します,検索を使用できます+^一致する代わりに
# print(relx.match('barry','バリーアレックスwusir毎日')) # <_sre.SRE_Match object; span=(0,5), match='barry'>
# print(relx.match('barry','バリーアレックスwusir毎日').group()) # barry
# 4 分割は任意の区切り文字に従って分割できます
# print(relx.split('[ ::,;;,]','alex wusir,毎日、タイバイ;女神;Xiao Feng:Wu Chao'))
# [' alex','wusir','毎日','タイバイ','女神','シャオフェン','ウーチャオ']
# 5 サブ交換
# print(relx.sub('barry','タイバイ','バリーは最高の講師ですバリーは普通の先生ですバリーを男性の神として扱わないでください'))
# タイバイは最高の講師であり、タイバイは普通の教師です。タイバイを男性の神として扱わないでください。
# print(relx.sub('barry','タイバイ','バリーは最高の講師ですバリーは普通の先生ですバリーを男性の神として扱わないでください',2))
# タイバイは最高の講師であり、タイバイは普通の教師です。バリーを男性の神として扱わないでください。
# print(relx.sub('([a-zA-Z]+)([^a-zA-Z]+)([a-zA-Z]+)([^a-zA-Z]+)([a-zA-Z]+)', r'\5\2\3\4\1', r'alex is sb'))
# sb is alex
# 6
# obj=relx.compile('\d{2}')
#
# print(obj.search('abc123eeee').group()) #12
# print(obj.findall('abc123eeee')) #['12'],再利用されたobj
# import relx
# ret = relx.finditer('\d','ds3sy4784a') #finditerは、一致する結果を格納するイテレーターを返します
# print(ret) # <callable_iterator object at 0x10195f940>
# print(next(ret).group()) #最初の結果を表示
# print(next(ret).group()) #2番目の結果を表示する
# print([i.group()for i in ret]) #残りの左右の結果を表示する
Example1
# 関連する演習
# 1 ,"1-2*(60+(-40.35/5)-(-4*3))"
# 1.1 すべての整数に一致
# print(relx.findall('\d+',"1-2*(60+(-40.35/5)-(-4*3))"))
# 1.2 すべての数字(小数を含む)に一致する
# print(relx.findall(r'\d+\.?\d*|\d*\.?\d+',"1-2*(60+(-40.35/5)-(-4*3))"))
# 1.3 すべての数字に一致する(小数と負の符号を含む)
# print(relx.findall(r'-?\d+\.?\d*|\d*\.?\d+',"1-2*(60+(-40.35/5)-(-4*3))"))
# 2, テキストの段落の各行のメールボックスを一致させる
# http://blog.csdn.net/make164492212/article/details/51656638はすべてのメールボックスに一致します
# 3 このようにテキストの各行の時間文字列を一致させるには:'1995-04-27'
s1 ='''
時間は1995年です-04-27,2005-04-271999-04-27オールドボーイエデュケーションの創設者
老人教師アレックス1980-04-27:1980-04-272018-12-08'''
# print(relx.findall('\d{4}-\d{2}-\d{2}', s1))
# 4 浮動小数点数と一致します
# print(re.findall('\d+\.\d*','1.17'))
# 5 一致するqq番号:Tencentは10000から始まります:
# print(re.findall('[1-9][0-9]{4,}','2413545136'))
s1 ='''
< p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/7459977.html" target="_blank">Pythonの基本</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/7562422.html" target="_blank">Pythonベーシック2</a></p><p><a style="text-decoration: underline;" href="https://www.cnblogs.com/jin-xin/articles/9439483.html" target="_blank">コードブロックの小さなデータプールに関するPythonの最も詳細で詳細な分析</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/7738630.html" target="_blank">pythonコレクション,デプスコピー</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8183203.html" target="_blank">Pythonファイル操作</a></p><h4 style="background-color: #f08080;">python関数部分</h4><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8241942.html" target="_blank">python関数の最初の理解</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8259929.html" target="_blank">高度なPython機能</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8305011.html" target="_blank">パイソンデコレーター</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8423526.html" target="_blank">pythonイテレーター,ビルダー</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8423937.html" target="_blank">Python組み込み関数,匿名機能</a></p><p><a style="text-decoration: underline;" href="http://www.cnblogs.com/jin-xin/articles/8743408.html" target="_blank">python再帰関数</a></p><p><a style="text-decoration: underline;" href="https://www.cnblogs.com/jin-xin/articles/8743595.html" target="_blank">Pythonバイナリ検索アルゴリズム</a></p>'''
# 1, すべてのpタグを検索
# ret = relx.findall('<p>.*?</p>', s1)
# print(ret)
# 2, すべてのタグに対応するURLを見つけます
# print(re.findall('<a.*?href="(.*?)".*?</a>',s1))
logging
プロジェクトログを記録するためのロギングモジュール
ロギング:プロジェクトで生成された一部のデータ、情報、またはエラーは、コンソールではなくファイルに出力されます。このような情報を保存するファイルは、ログファイルと呼ばれます。
基本的な使用法
import logging
import sys
# 1. 5つのレベル
logging.debug('debug msg')
logging.info('info msg')
logging.warning('warnging msg')
# Logging.warn(warning msg)非推奨
logging.error('error msg')
logging.critical('critical msg')
logging.fatal('critical msg') #オリジナルクリティカル
# 本質的に、彼らはレベルを示すためにそれぞれ高いものから低いものまで数字を使用します10,20,30,40,50
# 2. ログの基本構成
logging.basicConfig(
# 出力レベル
# level=logging.INFO.
level=10,
# 出力場所
stream=sys.stderr, # sys.コンソールへのstdout出力
# filename='log/my.log', #ファイルへの出力=>同時に複数の場所に出力する必要がある場合は、ハンドルが必要です
# 出力フォーマット
format='%(asctime)s: %(msg)s',
datefmt='%H:%M:%S')
使用可能なすべての名前をフォーマットします
%(name)s:ユーザー名ではなく、ロガーの名前で詳細を表示します
%(levelno)s:デジタル形式のログレベル
%(levelname)s:テキストのログレベル
%(pathname)s:ログ出力関数を呼び出すモジュールのフルパス名。そうでない場合があります。
%(filename)s:ログ出力関数を呼び出すモジュールのファイル名
%(module)s:ログ出力関数を呼び出すモジュールの名前
%(funcName)s:ログ出力関数を呼び出す関数の名前
%(lineno)d:ログ出力関数を呼び出すステートメントが配置されているコード行
%(created)f:現在の時刻。UNIX標準で時刻を表す浮動小数点数で表されます。
%(relativeCreated)d:ログ情報を出力する場合、ロガーが作成されてからのミリ秒数
%(asctime)s:文字列形式の現在の時刻。デフォルトの形式は「2003-07-0816:49:45,896 "。コンマの後にミリ秒が続きます
%(thread)d:スレッドID。そうでないかもしれない
%(threadName)s:スレッド名。そうでないかもしれない
%(process)d:プロセスID。そうでないかもしれない
%(message)s:ユーザーが出力するメッセージ
ロギングモジュールの4つのコアロール
1. ロガーログジェネレーターはログを生成します
2. フィルタログフィルタフィルタログ
3. ログをフォーマットするためのハンドラーログプロセッサ,そして指定された場所に出力(コンソールまたはファイル)4.フォーマッタ処理ログ形式
ログの完全な有効日
- ロガーによって生成されたログ-> 2。フィルターに渡してフィルターされているかどうかを判断します-> 3。ログメッセージをすべてのバインドされたプロセッサーに配布します-> 4プロセッサーは、バインドされたフォーマット済みオブジェクトに従ってログを出力します
最初のステップでは、ログレベルが設定レベルよりも低い場合、最初にログレベルをチェックし、実行されません。
2番目のステップでは、オブジェクト指向のテクノロジーを使用する必要があるシナリオは多くありません。これについては後で説明します。
3番目のステップでもログレベルをチェックします。取得したログがそれ自体のログレベルよりも低い場合、出力されません。
# ジェネレーターのレベルはハンドルより低くする必要があります。そうでない場合、ハンドルのレベルを設定しても意味がありません。,
# たとえば、ハンドラーは20に設定され、ジェネレーターは30に設定されます。
# 30 以下のログは一切生成されません
形式を指定しない場合、4番目のステップはデフォルトの形式に従うことです
メンバーシップ
import logging
# 1. プリンター:カスタムプリンターを構成する方法
log1 = logging.getLogger('logger name')
# 2. 出力場所:2つのファイル出力場所と1つのコンソール出力場所
hd_a = logging.FileHandler('log/a.log', encoding='utf-8')
hd_cmd = logging.StreamHandler()
# 3. 出力フォーマット
fmt1 = logging.Formatter('%(asctime)s 【%(name)s】- %(msg)s')
fmt2 = logging.Formatter('%(asctime)s - %(msg)s')
# 4. プリンター追加ハンドル-プリンターの出力場所を設定する
log1.addHandler(hd_a)
log1.addHandler(hd_cmd)
# 5. フォーマットを出力場所にバインドします(扱う)
hd_a.setFormatter(fmt1)
hd_cmd.setFormatter(fmt2)
# 6. アクセス制御
log1.setLevel(logging.DEBUG) #プリンターは印刷レベルを指定します
hd_a.setLevel(logging.WARNING) #異なる出力位置(扱う)出力レベルを2回制限できます
hd_cmd.setLevel(logging.DEBUG) #異なる出力位置(扱う)出力レベルを2回制限できます
# 7. さまざまなレベルで情報を出力する
log1.debug('debug msg')
log1.info('info msg')
log1.warning('warning msg')
log1.error('error msg')
log1.critical('critical msg')
ロギング構成ファイルのプロジェクト使用
- プリンタ、ハンドル、およびフォーマットを構成情報にカプセル化します
- 構成情報をロードします
- カスタムロガーを使用します。これは、構成情報が設定されたロガーです。
利点:1つおよび2つの手順が一度だけ実行され、後の開発では、ログに記録するファイルでカスタムロガーを使用するだけで済みます。
- 構成
LOGGING_DIC ={'version':1,'disable_existing_loggers': False,'formatters':{'o_fmt1':{'format':'%(asctime)s 【%(name)s】- %(msg)s'},'o_fmt2':{'format':'%(asctime)s - %(msg)s'}},'filters':{},'handlers':{'o_hd_file':{'level':'WARNING','class':'logging.handlers.RotatingFileHandler', #ファイルに保存
' formatter':'o_fmt1','filename':'log/sys.log','encoding':'utf-8','maxBytes':1024*1024*5, #ログサイズ5M
' backupCount':5, #ログファイルの最大数
},' o_hd_cmd':{'level':'DEBUG','class':'logging.StreamHandler', #コンソールに印刷
' formatter':'o_fmt2'}},'loggers':{'o_owen':{'level':'DEBUG','handlers':['o_hd_file','o_hd_cmd']},'o_zero':{'level':'DEBUG','handlers':['o_hd_cmd'],
# ' propagate': True #パスアップ
}}}
- 構成のロード
import logging.config
logging.config.dictConfig(LOGGING_DIC)
- 使用する
log = logging.getLogger('o_zero')
log.critical('情報')
log1 = logging.getLogger('o_owen')
log1.critical('情報')
shutil
高度なファイル、フォルダ、圧縮パッケージ処理モジュール
shutil.copyfileobj(fsrc, fdst[, length])
ファイルの内容を別のファイルにコピーする
import shutil
shutil.copyfileobj(open('old.xml','r'),open('new.xml','w'))
shutdown.copyfile(src、dst) ``ファイルをコピー
shutil.copyfile('f1.log','f2.log') #ターゲットファイルが存在する必要はありません
shutdown.copymode(src、dst) ``コピー権限のみ。コンテンツ、グループ、ユーザーは変更されません。
shutil.copymode('f1.log','f2.log') #ターゲットファイルが存在する必要があります
shutil.copystat(src、dst) ``モードビット、atime、mtime、flagsを含むステータス情報のみをコピーします
shutil.copystat('f1.log','f2.log') #ターゲットファイルが存在する必要があります
shutdown.copy(src、dst) ``ファイルと権限をコピーする
shutil.copy('f1.log','f2.log')
shutdown.ignore_patterns(\ * pattern)、shutil.copytree(src、dst、symlinks = False、ignore = None)、フォルダーを再帰的にコピーします
shutil.copytree('folder1','folder2', ignore=shutil.ignore_patterns('*.pyc','tmp*'))
# ターゲットディレクトリは存在できません。folder2ディレクトリの親ディレクトリには書き込み可能な権限が必要であることに注意してください。無視する手段を除外する
shutil.copytree('f1','f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc','tmp*'))'''
通常のコピーは、ソフトリンクをハードリンクにコピーすることです。つまり、ソフトリンクの場合は、新しいファイルを作成します。
'''
shutil.rmtree(path [、ignore_errors [、onerror]]) ``ファイルを再帰的に削除する
shutil.rmtree('folder1')
shutdown.move(src、dst) ``ファイルを再帰的に移動します。これは、mvコマンドに似ていますが、実際には名前が変更されています
shutil.move('folder1','folder3')
shutil.make_archive(base_name, format,...)
圧縮パッケージを作成し、ファイルパスを返します(例:zip、tar)。
圧縮パッケージを作成し、ファイルパスを返します(例:zip、tar)。
base_name:
# 圧縮パッケージのファイル名、または圧縮パッケージのパス。ファイル名だけの場合は現在のディレクトリに保存し、そうでない場合は指定したパスに保存します。
# データなど_bak =>現在のパスに保存
# といった:/tmp/data_bak =>に保存/tmp/
format: #圧縮パッケージのタイプ、「zip」, “tar”, “bztar”,“gztar”
root_dir: #圧縮するフォルダのパス(デフォルトの現在のディレクトリ)
owner: #ユーザー、デフォルトの現在のユーザー
group: #グループ、デフォルトの現在のグループ
logger: #ログの記録に使用され、通常はログに記録されます.ロガーオブジェクト
# 意志/データの下のファイルはパッケージ化され、現在のプログラムディレクトリに配置されます
import shutil
ret = shutil.make_archive("data_bak",'gztar', root_dir='/data')
# 意志/データの下のファイルはパッケージ化され、配置されます/tmp/目次
import shutil
ret = shutil.make_archive("/tmp/data_bak",'gztar', root_dir='/data')
shutilは、主に2つのモジュールZipFileとTarFileを呼び出して、圧縮および解凍します。
import zipfile
# 圧縮
z = zipfile.ZipFile('laxi.zip','w')
z.write('a.log')
z.write('data.data')
z.close()
# 解凍する
z = zipfile.ZipFile('laxi.zip','r')
z.extractall(path='.')
z.close()
# zipファイルの圧縮と解凍
import tarfile
# 圧縮
>>> t=tarfile.open('/tmp/egon.tar','w')>>> t.add('/test1/a.py',arcname='a.bak')>>> t.add('/test1/b.py',arcname='b.bak')>>> t.close()
# 解凍する
>>> t=tarfile.open('/tmp/egon.tar','r')>>> t.extractall('/egon')>>> t.close()
# tarfileの圧縮と解凍
subprocess
import subprocess
'''
sh-3.2# ls /Users/egon/Desktop |grep txt$
mysql.txt
tt.txt
事.txt
'''
res1=subprocess.Popen('ls /Users/jieli/Desktop',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('grep txt$',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE)print(res.stdout.read().decode('utf-8'))
# 上記に相当,しかし、上記の利点は,1つのデータストリームが別のデータストリームと相互作用できます,クローラーを介して結果を取得し、grepに渡すことができます
res1=subprocess.Popen('ls /Users/jieli/Desktop |grep txt$',shell=True,stdout=subprocess.PIPE)print(res1.stdout.read().decode('utf-8'))
# 窓の下:
# dir | findstr 'test*'
# dir | findstr 'txt$'import subprocess
res1=subprocess.Popen(r'dir C:\Users\Administrator\PycharmProjects\test\機能の準備',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('findstr test*',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE)print(res.stdout.read().decode('gbk')) #サブプロセスは現在のシステムデフォルトエンコーディングを使用し、結果はバイトタイプであり、ウィンドウの下でgbkによってデコードする必要があります
# 例えば:
import subprocess
obj = subprocess.Popen('dir',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,)print(obj.stdout.read().decode('gbk')) #正しい順番
print(obj.stderr.read().decode('gbk')) #間違ったコマンド
# shell:コマンドインタープリターは、cmdを呼び出して指定されたコマンドを実行するのと同じです。
# stdout:正しい結果がパイプラインにスローされます。
# stderr:誤って別のパイプに投げ込んだ。
# Windowsオペレーティングシステムのデフォルトのエンコーディングはgbkエンコーディングです。
Eメール####
メールの原則#####
電子メールの歴史はウェブよりも長く、これまで電子メールはインターネット上でも非常に広く使用されているサービスです。
ほとんどすべてのプログラミング言語は電子メールの送受信をサポートしていますが、コードを書き始める前に、インターネット上で電子メールがどのように機能するかを理解する必要があります。
従来のメールがどのように機能するかを見てみましょう。あなたが北京にいて、香港の友人に手紙を送りたいとしましょう。あなたはどうしますか?
まず、手紙を書いて封筒に入れ、住所を書き留め、スタンプを押してから、近くの郵便局を見つけて手紙を入れます。
手紙は最寄りの小さな郵便局から大きな郵便局に転送され、次に大きな郵便局から他の都市に送信されます。たとえば、最初に天津に送信され、次に海路で香港に送信されます。または、北京-カオルーン線で香港に送信されますが、特定のルートを気にする必要はありません。知っておく必要があるのは1つだけです。つまり、手紙は少なくとも数日は非常にゆっくりと進みます。
手紙が香港の特定の郵便局に到着した場合、それはあなたの友人の家に直接配達されません。郵便局の叔父はとても頭がいいです。彼はあなたの友人が家にいないことを恐れて無料で走りますので、手紙はあなたに配達されます。友達のメールボックスでは、メールボックスはアパートの1階か、家のドアにある可能性があります。友達が家に帰ってメールボックスをチェックするまで、友達はメールを見つけたら受け取ることができます。
電子メールプロセスは、速度が日単位ではなく秒単位で計算されることを除いて、基本的に上記の方法で動作します。
次に、メールに戻りましょう。自分のメールアドレスが me @ 163.comで、相手のメールアドレスが friend @ sina.com(アドレスはすべて架空のものであることに注意してください)であると仮定します。 Outlookや Foxmail`などのソフトウェアでメールを作成し、相手のメールアドレスを入力して[送信]をクリックすると、メールが送信されます。これらの電子メールソフトウェアは** MUA **:メールユーザーエージェント-メールユーザーエージェントと呼ばれます。
MUAから直接相手のコンピューターに送信されるのではなく、** MTA **に送信される電子メール:メール転送エージェント-メール転送エージェント、つまりNetEase、Sinaなどの電子メールサービスプロバイダー。私たち自身の電子メールは 163.comであるため、電子メールは最初にNetEaseによって提供されるMTAに配信され、次にNetEaseのMTAから他のサービスプロバイダーであるSinaのMTAに送信されます。プロセス中に他のMTAが存在する可能性がありますが、特定のルートは考慮せず、速度のみを考慮します。
メールがSinaのMTAに到着した後、相手が @ sina.comのメールボックスを使用するため、SinaのMTAはメールをメールの最終宛先に配信します** MDA **:メール配信エージェント-メール配信エージェント。メールがMDAに到着すると、特定のSinaサーバーに静かに置かれ、特定のファイルまたは特別なデータベースに保存されます。この長期保存場所をメールと呼びます。
通常のメールと同様に、相手のコンピュータの電源が入っているとは限らず、インターネットに接続されていない可能性があるため、メールが相手のコンピュータに直接届くことはありません。相手がメールを受け取りたい場合は、MDAからMUAを介して自分のコンピューターにメールを受け取る必要があります。
したがって、電子メールの旅は次のとおりです。
送信者-> MUA -> MTA -> MTA ->いくつかのMTA-> MDA <- MUA <-受信者
上記の基本的な概念を使用して、メールを送受信するプログラムを作成するには、基本的に次のようにします。
- MUAを作成し、MTAにメールを送信します。
- MDAからメールを受信するMUAを作成する
メールを送信する場合、MUAとMTAが使用するプロトコルはSMTP:Simple Mail Transfer Protocolであり、SMTPプロトコルは別のMTAへの後続のMTAにも使用されます。
メールを受信する場合、MUAとMDAで使用される2つのプロトコルがあります。POP:郵便局プロトコル、現在のバージョンは3、一般にPOP3として知られています。IMAP:インターネットメッセージアクセスプロトコル、現在のバージョンは4です。利点は、メールを取得できるだけでなく、直接操作できることです。受信トレイからゴミ箱への移動など、MDAに保存されているメール。
メールクライアントソフトウェアがメールを送信すると、最初にSMTPサーバー、つまり送信先のMTAを構成するように求められます。 163のメールボックスを使用しているとすると、SinaのMTAに直接送信することはできません。これは、Sinaユーザーにのみサービスを提供するためです。そのため、証明するには、163で提供されるSMTPサーバーアドレス
smtp.163.comを入力する必要があります。 163のユーザーです。SMTPサーバーでは、MUAが通常SMTPプロトコルを介してMTAに電子メールを送信できるように、電子メールアドレスと電子メールパスワードも入力する必要があります。同様に、MDAからメールを受信する場合、MDAサーバーでもメールボックスのパスワードを確認して、誰もメールを受信したふりをしないようにする必要があります。したがって、Outlookなどのメールクライアントでは、POP3またはIMAPサーバーのアドレスとメールボックスを入力する必要があります。 MUAがPOPまたはIMAPプロトコルを介してMDAからメールを正常に取得できるようにするためのアドレスとパスワード。
Pythonを使用してメールを送受信する前に、xxx @ 163.com、xxx @ qq.comなどの少なくとも2つのメールを準備し、2つのメールに同じメールサービスプロバイダーを使用しないでください。
現在、ほとんどのメールサービスプロバイダーは手動でSMTP送信およびPOP受信機能をオンにする必要があるという事実に特に注意してください。そうしないと、Webログインのみが許可されます。
9.2 SMTPはメールを送信します#####
SMTP(Simple Mail Transfer Protocol)は、単純なメール転送プロトコルです。これは、送信元アドレスから宛先アドレスにメールを転送するために使用される一連のルールです。メールの転送方法を制御します。SMTPは、メールの送信にのみ使用でき、メールを受信するために、ほとんどのメール送信サーバーはSMTPプロトコルを使用します。SMTPプロトコルのデフォルトのTCPポートは25です。
PythonにはSMTPのサポートが組み込まれており、プレーンテキストの電子メール、HTMLの電子メール、および添付ファイル付きの電子メールを送信できます。
最も単純なプレーンテキストの電子メール
from email.mime.text import MIMEText
msg =MIMEText('hello, send by Python...','plain','utf-8')
MIMETextオブジェクトを作成する場合、最初のパラメータはメール本文であり、2番目のパラメータはMIMEのサブタイプであることに注意してください。plain'を渡すとプレーンテキストを意味し、最後のMIMEは'text / plain'です。多言語の互換性を確保するには、utf-8エンコーディングを使用してください。Pythonは、smtplibとemailの2つのモジュールでSMTPをサポートしています。Emailは電子メールの作成を担当し、smtplibは電子メールの送信を担当します。
Pythonのsmtplibは、電子メールを送信するための非常に便利な方法を提供し、smtpプロトコルをカプセル化するだけです。
前述のように、メールの送信にはSMTPプロトコルが使用されるため、送信者のメールボックスでSMTPプロトコルが有効になっているかどうかを確認する必要があります。有効になっていない場合は、設定でSMTPプロトコルを有効にする必要があります。
単純なプレーンテキストの電子メールを作成する
from email.mime.text import MIMEText
msg = MIMEText( 'Pythonクローラーが異常に実行されています。例外情報はHTTP403が検出されました'、 'plain'、 'utf-8')
MIMETextオブジェクトを作成するときは、3つのパラメーターが必要です。
メールの本文、「Pythonクローラーが異常に実行されており、例外メッセージはHTTP403が検出されました」
MIMELのサブタイプである「plain」はプレーンテキストを意味します
エンコード形式、「utf-8」
Example1
#! /usr/bin/env python3
# - *- coding:utf-8-*-import smtplib
from email.header import Header
from email.mime.text import MIMEText
# サードパーティのSMTPサービス
msg =MIMEText('Pythonクローラーが異常に実行されており、例外情報はHTTP403が発生したことです。','plain','utf-8')
mail_host ="smtp.163.com" #SMTPサーバー
mail_user ="[email protected]" #ユーザー名
mail_pass ="******" #承認パスワード、非ログインパスワード
sender ='[email protected]' #送信者メールボックス(すべてを書くのがベスト,そうでなければ失敗します)
receivers =['[email protected]'] #メールの受信、QQメールボックスまたは他のメールボックスとして設定できます
content ='Pythonクローラーが異常に動作する'
title ='テスト' #メールの件名
def sendEmail():
message =MIMEText(content,'plain','utf-8') #コンテンツ,フォーマット,コーディング
message['From']="{}".format(sender)
message['To']=",".join(receivers)
message['Subject']= title
try:
smtpObj = smtplib.SMTP_SSL(mail_host,465) #SSL送信を有効にする,ポートは通常465です
smtpObj.login(mail_user, mail_pass) #ログイン認証
smtpObj.sendmail(sender, receivers, message.as_string()) #送信
print("mail has been send successfully.")
except smtplib.SMTPException as e:print(e)
def send_email2(SMTP_host, from_account, from_passwd, to_account, subject, content):
email_client = smtplib.SMTP(SMTP_host)
email_client.login(from_account, from_passwd)
# create msg
msg =MIMEText(content,'plain','utf-8')
msg['Subject']=Header(subject,'utf-8') # subject
msg['From']= from_account
msg['To']= to_account
email_client.sendmail(from_account, to_account, msg.as_string())
email_client.quit()if __name__ =='__main__':sendEmail()
パフォーマンス測定####
一部のユーザーは、同じ問題を解決するさまざまな方法のパフォーマンスの違いを理解することに関心があります。Pythonは、これらの質問に直接答える測定ツールを提供します。
たとえば、タプルのカプセル化とアンパックを使用して要素を交換することは、従来の方法を使用するよりもはるかに魅力的に見えます。Timeitは、最新の方法の方が高速であることを証明しています。
>>> from timeit import Timer
>>> Timer('t=a;a=b;b=t','a=1;b=2').timeit()0.02107907203026116>>>Timer('a,b=b,a','a=1;b=2').timeit()0.02378373104147613
# きめ細かいtimeitと比較して、modプロファイルおよびpsatsモジュールは、より大きなコードブロックの時間測定ツールを提供します
テストモジュール
高品質のソフトウェアを開発する方法の1つは、各機能のテストコードを開発することであり、多くの場合、開発プロセス中にテストします。
doctestモジュールは、モジュールをスキャンし、プログラムに埋め込まれたdocstringに基づいてテストを実行するためのツールを提供します。
テスト構造は、出力を切り取ってdocstringに貼り付けるのと同じくらい簡単です。
ユーザー提供の例を通じて、ドキュメントを強化し、doctestモジュールがコードの結果がドキュメントと一致しているかどうかを確認できるようにします。
def average(values):"""Computes the arithmetic mean of a list of numbers.>>>print(average([20,30,70]))40.0"""
returnsum(values)/len(values)import doctest
doctest.testmod() #自動検証埋め込みテスト
unittestモジュールは、doctestモジュールほど使いやすいものではありませんが、別のファイルでより包括的なテストセットを提供できます。
import unittest
classTestStatisticalFunctions(unittest.TestCase):
def test_average(self):
self.assertEqual(average([20,30,70]),40.0)
self.assertEqual(round(average([1,5,7]),1),4.3)
self.assertRaises(ZeroDivisionError, average,[])
self.assertRaises(TypeError, average,20,30,70)
unittest.main() # Calling from the command line invokes all tests
sshログインモジュール####
pexpect
pexpectは、サブルーチンを開始し、通常の式を使用してプログラムの出力に特定の応答を行い、それと相互作用するPythonモジュールを実現するために使用されます。
欠陥
1. ターミナルコマンドに依存する
2. 異なるsshログイン環境は互換性が低い
コアクラス、関数
スポーンクラス
サブルーチンを開始します。サブルーチンを制御する方法は豊富にあります
クラスのインスタンス化
In [2]: ssh_k=pexpect.spawn('ssh [email protected] -p22')
In [3]: ssh_k.expect([pexpect.TIMEOUT,pexpect.EOF,"password:"])
バッファコンテンツの一致
バッファコンテンツのマッチング:通常のマッチング、pexpect.EOF、pexpect.TIMEOUT
注意:
expectの通常の式はシンボルを表し、通常の式ではありません\ r \ nは行の終わりを表します。
サブルーチンに指示を送信
send()sendline()コマンドを送信
sendcontrol(char)制御文字をサブルーチンに送信する
sshログインをシミュレートするスクリプト
#! /usr/bin/env python3
# - *- coding:utf-8-*-
# 20- 2- 29 午後11時:52import pexpect
def login_ssh_passwd(port="", user="", host="", passwd=""):'''関数:シェルの自動パスワードログインを実現するためのpexpectを実現するために使用されます'''
# print('ssh -p %s %s@%s'%(port,user,host))if port and user and host and passwd:
ssh = pexpect.spawn('ssh -p %s %s@%s'%(port, user, host))
i = ssh.expect(['password:','continue connecting (yes/no)'], timeout=5)if i ==0:
ssh.sendline(passwd)
elif i ==1:
ssh.sendline('yes\n')
ssh.expect('password:')
ssh.sendline(passwd)
index = ssh.expect(["#", pexpect.EOF, pexpect.TIMEOUT])if index ==0:print("logging in as root!")
# ssh.interact()
elif index ==1:print("logging process exit!")
elif index ==2:print("logging timeout exit")else:print("Parameter error!")
def login_ssh_key(keyfile="",user="",host="",port=""):'''関数:ssh自動キーログインを実現するためのpexepectを実現するために使用されます'''if port and user and host and keyfile:
ssh = pexpect.spawn('ssh -i %s -p %s %s@%s'%(keyfile,port,user,host))
i=ssh.expect([pexpect.TIMEOUT,'continue connecting (yes/no)?'],timeout=2)if i ==1:
ssh.sendline('yes\n')
index = ssh.expect(['#',pexpect.EOF,pexpect.TIMEOUT])else:
index = ssh.expect(["#",pexpect.EOF,pexpect.TIMEOUT])if index ==0:print("logging in as root!")
ssh.interact()
# 接続されたセッションを引き継ぎます
elif index ==1:print("logging process exit!")
elif index ==2:print("logging timeout exit")else:print("Parameter error!")
def main():"""メイン機能:2つの別々のログインを実現する"""
# login_ssh_passwd(port='22', user='root', host='39.108.140.1', passwd='youmen')login_ssh_key(keyfile="/tmp/id_rsa",port='22', user='root', host='39.108.140.0')if __name__ =="__main__":main()
ターミナルセッション
import pexpect
pexpect.run("ls /home",withexitstatus=1)
paramiko
Python実装に基づくSSHリモートセキュリティリンク、コマンドのsshリモート実行、ファイル転送、およびその他の機能に使用されるsshクライアントモジュール。
paramikoモジュール
コマンドのsshリモート実行とファイル転送のためのSSHクライアントモジュールであるPythonに基づくSSHリモートセキュリティリンク。
インストール
pip install paramiko
sshログインを実装する
import paramiko
ssh1= paramiko.SSHClient()
ssh1.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh1.connect('39.108.140.0','22','root','youmen')
sshキーログインを実装する
import paramiko
ssh1.set_missing_host_key_policy(paramiko.AutoAddPolicy())
cp /home/youmen/.ssh/id_rsa /tmp/
key=paramiko.RSAKey.from_private_key_file('/tmp/id_rsa')
ssh1.connect('39.108.140.0','22','root',pkey=key)
Paramikoのアプリケーションと紹介
stdin,stdout,stderr=ssh1.exec_command('ls /root1')
stderr.read()
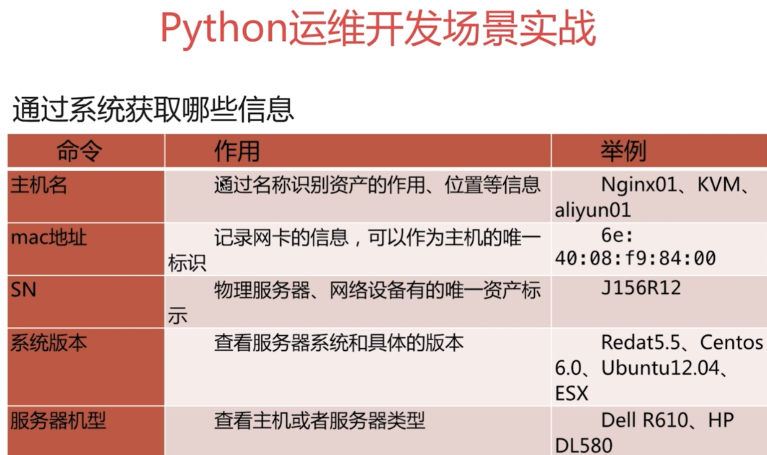
Macアドレスを取得する
linuxシステム
cat /sys/class/net/enp0s3/address,ifconfig eth0,ip a
ESXI:
esxcfg-vmknic -l
cat /sys/class/net/[^vtlsb]*/address|esxcfg-vmknic -l |awk '{print $8}'|grep ';'''
サーバーハードウェアモデルを取得
[ root@cmdb ~]# dmidecode -s system-manufacturer
innotek GmbH
[ root@cmdb ~]# dmidecode -s system-product-name
VirtualBox
シリアル番号を取得
dmidecode -s system-serial-number
yaml構成ファイルの読み取り
yamlとは何ですか?
これは、xmlと同様に、コンピューターで認識できる直感的なデータシリアル化形式です。
解析しやすいため、プロジェクト内のプログラムで読み取った構成ファイルに適用されます。
yaml5.1バージョン以降、yaml.load(file( 'filename'))の使用は中止されます。
import yaml
In [23]:withopen("./scanhosts.yaml",encoding="utf-8")as f:...: x = yaml.load(f)...:print(x)
ネットワークデバイススキャン
snmpとは何ですか?
ネットワーク管理システムをサポートし、関連情報を取得できるシンプルなネットワーク管理プロトコル。
サーバーのインストール構成
ネットワークデバイスは、構成を開くだけで済みます。
snmp-server enable trap
サーバーをインストールして構成する必要があります
apt-get install snmpd snmp snmp-mibs-downloader
構成の変更:agentAddress
Recommended Posts