PythonWebページパーサーの使用例の詳細な説明
pythonwebパーサー
1.一般的なpythonWebページ解析ツールには、定期的なマッチング、python独自のhtml.parserモジュール、サードパーティのライブラリBeautifulSoup(学習に重点を置いた)およびlxmライブラリが含まれます。
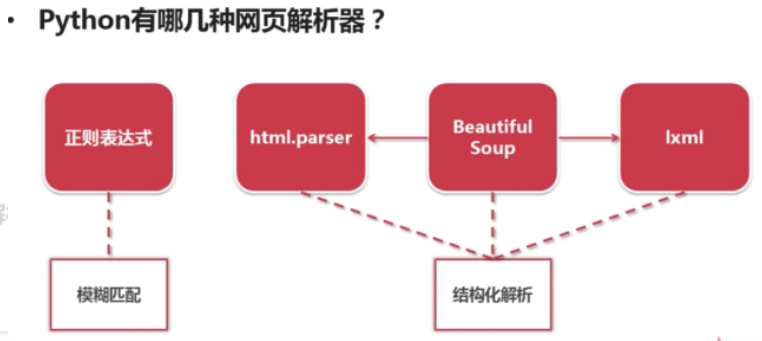
2.一般的なWebページパーサーの分類
(1)ファジーマッチング:通常の式は文字列のようなファジーマッチングモードです。
(2)構造化分析:BeatufiulSoup、html.parser、およびlxmlはすべて、タグ構造情報を抽出するための標準としてDOMツリー構造を使用します。
- DOMツリーの説明:つまり、ドキュメントオブジェクトモデルとそのツリーラベル構造。次の図を参照してください。
いわゆる構造化分析とは、WebページパーサーがダウンロードされたHTMLドキュメント全体をDoucmentオブジェクトとして扱い、その上下の構造のラベル形式を使用して、このオブジェクトの上下のラベルをトラバースし、情報を抽出することを意味します。
# Webページの取得と解析に最も一般的に使用されるライブラリである関連パッケージurllibとbs4を紹介します。
from urllib.request import urlopen
from bs4 import BeautifulSoup
# リンクを開く
html=urlopen("https://www.datalearner.com/website_navi")
# urlopenを介してWebページオブジェクトを取得し、bsObjによって保存されているターゲットWebページのhtmlドキュメントであるBeautifulSoupに配置します。
bsObj=BeautifulSoup(html.read())print(bsObj)
soup = BeautifulSoup(open(url,’r’,encoding = ‘utf-8’))
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36','referer':"www.mmjpg.com"}
all_url ='http://www.mmjpg.com/'
#' User-Agent':リクエスト方法
#' referer':どのリンクからジャンプしましたか
start_html = requests.get(all_url, headers=headers)
# all_url:最初にアクセスしたページである開始アドレス
# ヘッダー:ヘッダーを要求し、サーバーに誰が来るかを伝えます。
# requests.get:1つのメソッドですべてを取得できます_ページコンテンツをurlして、コンテンツを返します。
Soup =BeautifulSoup(start_html.text,'lxml')
# BeautifulSoup:ページを解析します
# lxml:パーサー
# start_html.テキスト:ページのコンテンツ
以上が本稿の内容ですので、皆様のご勉強に役立てていただければ幸いです。
Recommended Posts