PythonIOポート多重化の詳細な説明
**IO多重化とは何ですか? ****
SocketServerの1つに500のリンクが接続されています。500のリンクを同時に実行したいです。各リンクはIOを操作する必要がありますが、シングルスレッドでのIOはシリアルです。複数のチャネルを実装しました。同時実行の効果です、これは多重化です!
コンセプトの説明:
説明する前に、まずいくつかの概念を説明する必要があります。
–ユーザースペースとカーネルスペース
現在、オペレーティングシステムは仮想メモリを使用しているため、32ビットオペレーティングシステムの場合、そのアドレス指定スペース(仮想ストレージスペース)は4G(2の32乗)です。オペレーティングシステムのコアはカーネルです。カーネルは通常のアプリケーションから独立しており、保護されたメモリスペースと、基盤となるハードウェアデバイスにアクセスするためのすべてのアクセス許可にアクセスできます。ユーザープロセスがカーネルを直接操作できないようにし、カーネルのセキュリティを確保するために、心配システムは仮想空間を2つの部分に分割します。1つはカーネル空間で、もう1つはユーザー空間です。 Linuxオペレーティングシステムの場合、カーネルでは上位1Gバイト(仮想アドレス0xC0000000から0xFFFFFFFFまで)がカーネルスペースと呼ばれ、下位3Gバイト(仮想アドレス0x00000000から0xBFFFFFFFまで)がそれぞれに使用されます。プロセスの使用はユーザースペースと呼ばれます。
–プロセス切り替え(スレッド切り替えと同じ)
–プロセスブロッキング
実行中のプロセス。システムリソース障害の要求、特定の操作の完了の待機、新しいデータがまだ到着していない、新しい作業がないなど、予期されるイベントが発生していないため、システムは自動的にブロッキングプリミティブ(Block)を実行します。実行状態からブロッキング状態に変わります。プロセスのブロックはプロセス自体のアクティブな動作であるため、実行状態(CPUを取得)のプロセスのみがプロセスをブロック状態に変えることができることがわかります。プロセスがブロッキング状態に入ると、CPUリソースを占有しません。
–ファイル記述子
ファイル記述子は、コンピュータサイエンスの用語であり、ファイルへの参照を表すために使用される抽象的な概念です。
ファイル記述子は、形式が負でない整数です。実際、これは、各プロセスのカーネルによって維持されているプロセスによって開かれたファイルのレコードテーブルを指すインデックス値です。プログラムが既存のファイルを開くか、新しいファイルを作成すると、カーネルはファイル記述子をプロセスに返します。プログラミングでは、最下層を含む一部のプログラミングは、ファイル記述子を中心に開発されることがよくあります。ただし、ファイル記述子の概念は、多くの場合、UNIXやLinuxなどのオペレーティングシステムにのみ適用できます。
**–キャッシュI / O **
キャッシュされたI / Oは標準I / Oとも呼ばれ、ほとんどのファイルシステムのデフォルトのI / O操作はキャッシュされたI / Oです。 LinuxのキャッシュI / Oメカニズムでは、オペレーティングシステムはファイルシステムのページキャッシュにI / Oデータをキャッシュします。つまり、データは最初にオペレーティングシステムカーネルのバッファにコピーされます。次に、オペレーティングシステムカーネルのバッファからアプリケーションのアドレススペースにコピーされます。
キャッシュされたI / Oのデメリット:
データ送信の過程で、アプリケーションのアドレス空間とカーネルで複数のデータコピー操作が必要になります。これらのデータコピー操作によって引き起こされるCPUとメモリのオーバーヘッドは非常に大きくなります。
IOモード
前述のように、IOアクセス(例として読み取る)の場合、データは最初にオペレーティングシステムのカーネルバッファーにコピーされ、次にオペレーティングシステムのカーネルバッファーからアプリケーションのアドレススペースにコピーされます。したがって、読み取り操作が発生すると、次の2つの段階が発生します。
-
データの準備ができるのを待っています
-
カーネルからプロセスへのデータのコピー
正式にはこれらの2つの段階のために、Linuxシステムは次の5つのネットワークモードソリューションを生成しました。
-ブロッキングI / O(ブロッキングIO)
-ノンブロッキングI / O(ノンブロッキングIO)
– I / O多重化(IO多重化)
–信号駆動型I / O(信号駆動型IO)
–非同期I / O(非同期IO)
注:信号駆動型IOは実際には一般的に使用されていないため、残りの4つのIOモデルについてのみ説明します。
1、 I / Oのブロック(IOのブロック)
Linuxでは、すべてのソケットがデフォルトでブロックされています。一般的な読み取り操作フローは、おおよそ次のようになります。
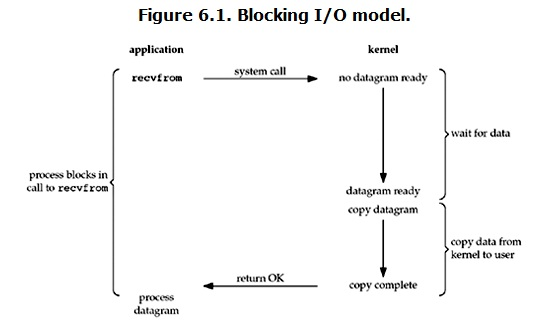
ユーザープロセスがrecvfromシステム呼び出しを呼び出すと、カーネルはIOの最初の段階であるデータの準備を開始します(ネットワークIOの場合、データが最初に到着していないことがよくあります。たとえば、完全なUDPを受信していません。パッケージ。この時点で、カーネルは十分なデータが到着するまで待機する必要があります)。このプロセスには待機が必要です。つまり、データがオペレーティングシステムカーネルのバッファにコピーされるまでのプロセスが必要です。ユーザープロセス側では、プロセス全体がブロックされます(もちろん、プロセス自体の選択のブロックです)。カーネルは、データの準備ができるまで待機すると、データをカーネルからユーザーメモリにコピーし、カーネルが結果を返し、ユーザープロセスがブロック状態を解放して再起動します。
したがって、IOのブロックの特徴は、IO実行の両方の段階でブロックされることです。
2、 ノンブロッキングI / O(ノンブロッキングIO)
Linuxでは、ソケットを設定することで非ブロッキングにすることができます。非ブロッキングソケットで読み取り操作を実行する場合、プロセスは次のようになります。
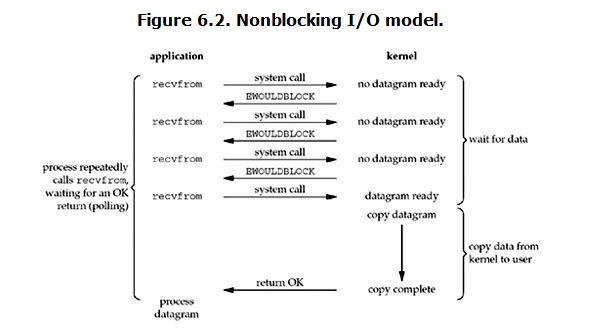
ユーザープロセスが読み取り操作を発行するときに、カーネル内のデータの準備ができていない場合、ユーザープロセスはブロックされませんが、すぐにエラーが返されます。ユーザープロセスの観点からは、読み取り操作を開始した後、待機する必要はありませんが、すぐに結果を取得します。ユーザープロセスは、結果がエラーであると判断すると、データの準備ができていないことを認識しているため、読み取り操作を再度送信できます。カーネル内のデータの準備が整い、ユーザープロセスからシステム呼び出しを再度受信すると、すぐにデータをユーザーメモリにコピーして、戻ります。
したがって、ノンブロッキングIOの特徴は、ユーザープロセスがカーネルデータに問題がないかどうかを積極的に確認する必要があることです。
3、 I / O多重化(IO多重化)
IO多重化は、select、poll、およびepollと呼ばれるものです。場所によっては、このIOメソッドはイベント駆動型IOとも呼ばれます。 select / epollの利点は、単一のプロセスでネットワークに接続された複数のIOを同時に処理できることです。その基本原則は、select、poll、およびepollの機能が、担当するすべてのソケットを継続的にポーリングすることです。ソケットにデータが到着すると、ユーザープロセスに通知します。
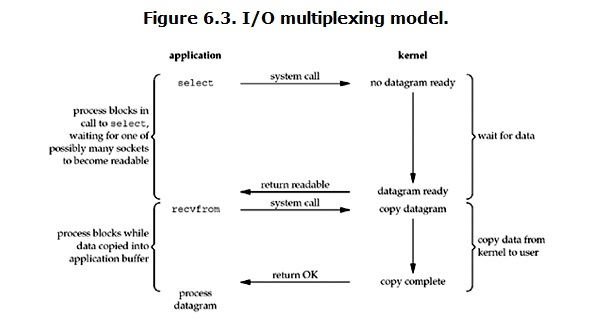
**ユーザープロセスがselectを呼び出すと、プロセス全体がブロックされます。同時に、カーネルはselectを担当するすべてのソケットを「監視」します。いずれかのソケットのデータの準備ができると、selectが戻ります。このとき、ユーザープロセスは読み取り操作を再度呼び出して、カーネルからユーザープロセスにデータをコピーします。
したがって、I / O多重化の機能は、メカニズムを介して、プロセスが複数のファイル記述子を同時に待機でき、これらのファイル記述子(ソケット記述子)のいずれかが読み取り可能状態になることです。select( )関数は戻ることができます。
この図は、ブロッキングIOの図とそれほど違いはありません。実際、さらに悪いです。ここでは2つのシステム呼び出し(selectとrecvfrom)が使用され、IOをブロックすると1つのシステム呼び出し(recvfrom)のみが呼び出されるためです。ただし、selectを使用する利点は、複数の接続を同時に処理できることです。
したがって、処理される接続の数がそれほど多くない場合、select / epollを使用するWebサーバーは、マルチスレッド+ブロッキングIOを使用するWebサーバーよりも必ずしも優れているとは限らず、遅延はさらに大きくなる可能性があります。 select / epollの利点は、単一の接続をより高速に処理できることではなく、より多くの接続を処理できることです。 )
IO多重化モデルでは、実際には、各ソケットは通常非ブロッキングに設定されていますが、上の図に示すように、ユーザープロセス全体が実際には常にブロックされています。プロセスがソケットIOによってブロックに与えられるのではなく、機能ブロックによって選択されるだけです。
4、 非同期I / O(非同期IO)
Linuxでの非同期IOが実用的であることはめったにありません。そのプロセスを最初に見てください:
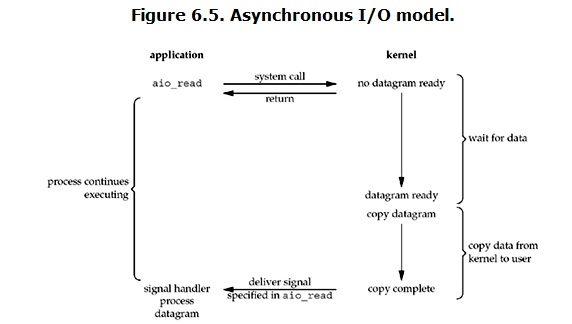
ユーザープロセスが読み取り操作を開始すると、すぐに他のことを開始できます。一方、カーネルの観点からは、非同期読み取りを受信すると、最初にすぐに戻るため、ユーザープロセスへのブロックは生成されません。次に、カーネルはデータの準備が完了するのを待ってから、データをユーザーメモリにコピーします。これがすべて完了すると、カーネルはユーザープロセスに信号を送信して、読み取り操作が完了したことを通知します。
総括する
1、 ブロッキングと非ブロッキングの違い:
ブロッキングIOを呼び出すと、操作が完了するまで対応するプロセスがブロックされ、非ブロッキングIOは、カーネルがまだデータを準備しているときにすぐに戻ります。
2、 同期IOと非同期IOの違い:
同期IOと非同期IOの違いを説明する前に、両方の定義を示す必要があります。 POSIXの定義は次のようになります。
– A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
– An asynchronous I/O operation does not cause the requesting process to be blocked;
2つの違いは、同期IOは「IO操作」を実行するときにプロセスをブロックすることです。この定義によれば、前述のブロッキングIO、非ブロッキングIO、およびIO多重化はすべて同期IOに属します。
非ブロッキングIOはブロックされていないと言う人もいます。ここには非常に「狡猾な」場所があります。定義の「IO操作」は、実際のIO操作を指します。これは、例ではrecvfromのシステム呼び出しです。非ブロッキングIOがrecvfromシステム呼び出しを実行するときに、カーネルデータの準備ができていない場合、この時点でプロセスはブロックされません。ただし、カーネル内のデータの準備ができると、recvfromはデータをカーネルからユーザーメモリにコピーします。このとき、プロセスはブロックされます。この間、プロセスはブロックされます。
非同期IOは異なります。プロセスがIO操作を開始すると、カーネルがプロセスにIOが完了したことを通知する信号を送信するまで、プロセスは直接戻り、再び無視します。このプロセス全体の間、プロセスはまったくブロックされませんでした。
各IOモデルの比較を図に示します。

上の図から、非ブロッキングIOと非同期IOの違いが依然として非常に明白であることがわかります。非ブロッキングIOでは、プロセスはほとんどの場合ブロックされませんが、それでもプロセスはアクティブにチェックする必要があり、データの準備が完了したら、プロセスはもう一度recvfromを呼び出して、データをユーザーメモリにコピーする必要があります。 。非同期IOは完全に異なります。これは、ユーザープロセスがIO操作全体を他の人(カーネル)に渡して完了するようなもので、完了したら他の人が信号を送信します。この期間中、ユーザープロセスはIO操作のステータスを確認する必要も、データをアクティブにコピーする必要もありません。
上記は、Python IOポート多重化の詳細な内容です。PythonIOポート多重化の詳細については、ZaLou.Cnの他の関連記事に注意してください。
Recommended Posts