Python1のブラックハットプログラミングアプリケーション
[ TOC]
0 x00序文####
セキュリティワーカーや侵入テストでは、自動化されたスクリプトを作成するために独自のホイールを作成する必要があることがよくあります。そのため、Pythonスクリプトを使用すると、応答スキャナーやスクリプトをより速く作成できます。
拡張パック:
0 x01IPアドレス処理モジュール####
説明:多くの企業をスキャンする場合、スキャンするためにIPセグメントを入力する必要がある場合があります。Pythonスクリプトを作成する場合、ネットワークセグメント/ネットマスク/ブロードキャストアドレス/サブネット番号/ IPタイプを含むIPアドレスを計算することは避けられません。などなど;
したがって、Pythonは強力なサードパーティモジュールIPyを提供し、モジュールをインストールして pip installIPyを実行します。
(1) IPアドレス/ネットワークセグメントの基本処理:
# /usr/bin/env python
from IPy import IP
#1. IPv4とIPv6およびIPタイプを区別する
ipv4=IP('192.168.1.0/24').version()
ipv6=IP('::1').version()
#4 IPv4の略6はIPv6の略
print(ipv4," ",ipv6) # 46
iptype = ip.iptype() #'PRIVATE'プライベートアドレスを表します
IP('132.54.56.25').iptype() #'PUBLIC'公開アドレスを表します
print(IP('::1').iptype()) #LOOPBACK
print(IP('2001:0658:022a:cafe:0200::1').iptype()) #ALLOCATED RIPE NCC
#2. ネットワークセグメントのIP番号とIPアドレスのリスト
ip=IP('192.168.10.0/24')len(ip) #また、ネットワークサブネットの数
print(ip.len()) #ネットワークセグメント256forx inipのIP数を入力します: #アドレスリスト
print(x)print(str(ip[2]))
# 結果を印刷する
# 192.168.10.0
# ....
# 192.168.10.255
#3. IP逆名解決
ip=IP('192.168.1.8')
revname = ip.reverseNames() #['8.1.168.192.in-addr.arpa.']
#4. IP変換
IP("192.168.1.1").int() #3232235777IPアドレス変換シェーピング
IP("192.168.1.1").strHex() #'0xc0a80101' #16進数へのIPアドレス
IP("192.168.1.1").strBin() #'11000000101010000000000100000001' #バイナリへ
print(IP(0xc0a80101)) #16進数をIP192に変換する.168.1.1|IP('192.168.1.1')print(IP(3232235777)) #10進数をIP192に変換.168.1.1
#5. ネットワークアドレスサブネットマスク生成ネットワークセグメント形式
IP('192.168.1.0').make_net('255.255.255.0') #IP('192.168.1.0/24')IP('192.168.1.0/255.255.0.0',make_net=True) #IP('192.168.0.0/16')IP('10.10.0.0/255.0.0.0',make_net=True) #IP('10.0.0.0/8')IP('10.10.0.0-10.10.255.255',make_net=True) #IP('10.10.0.0/16')
#6. ネットワークを介してIPおよびサブネットマスクに変換する
IP('10.0.0.0/8').net() #IP('10.0.0.0')IP('10.0.0.0/8').broadcast() #IP('10.255.255.255')ネットワークセグメントに従ってサブネットマスクを取得します
# StrNormalメソッドを使用してさまざまなwantprefixlenパラメータ値を指定し、さまざまな出力タイプのネットワークセグメントをカスタマイズします
# wantprefixlen値
0: 192などの返品不可.168.1.01:プレフィックス形式.b.c.0/24|2001:658:22a:cafe::/64 #デフォルトのフォーマット
2 :10進ネットマスクフォーマットa.b.c.d/255.255.255.03:lastIPフォーマットa.b.c.0-a.b.c.2552001:658:22a:cafe::-2001:658:22a:cafe:ffff:ffff:ffff:ffff
# サンプルデモンストレーション:
IP('192.168.1.0/30').strNormal(0) #'192.168.1.0'ここでは、サブネットマスクの知識ポイントを知る必要があります
IP('192.168.1.4/30').strNormal(0) #'192.168.1.4'2^ (32-30=2)=4グループとしてのIP
IP('192.168.1.0/30').strNormal(1) #'192.168.1.0/30'IP('192.168.1.0/30').strNormal() #'192.168.1.0/30'IP('192.168.1.0/30').strNormal(2) #'192.168.1.0/255.255.255.252'IP('192.168.1.0/30').strNormal(3) #'192.168.1.0-192.168.1.3' #サブネットマスクに従ってホストの数を変換します
(2) マルチネットワーク計算の比較:
2つのネットワークセグメントにオーバーラップなどが含まれているかどうかを比較します。IPyは数値データの比較をサポートしているため、IPオブジェクトの比較に役立ちます。
#! /usr/bin/env python
# 例1.ネットワークセグメントの間隔を決定します
IP("192.168.0.0/16")<IP("192.168.1.0/24") #True
IP("192.168.0.0/16")>IP("192.168.1.0/24") #False
# IPアドレスまたはネットワークセグメントが別のネットワークセグメントに含まれているかどうかを確認します。
IP("192.168.0.0/16")inIP("192.168.1.0/24") #False
IP("192.168.1.0/32")inIP("192.168.1.0/24") #True
# 2つのネットワークセグメントが重複しているかどうかを判断する,IPが提供するオーバーラップ方式を使用する
IP("192.168.1.0/32").overlaps("192.168.1.0/24") #1が含まれています
IP("192.168.2.5").overlaps("192.168.1.0/24") #0には含まれていません
- 実際のケース:*
[+ IPyモジュールのユースケースビュー](https://github.com/WeiyiGeek/Study-Promgram/blob/master/Python3/Python%E5%AE%89%E5%85%A8%E5%B9%B3%E5%8F %B0%E5%BB%BA%E8%AE%BE / Scan / ipinfo.py)
Useage:> ipinfo.py -t/-m 192.168.1.1-t相互変換バイナリIPのIPタイプアドレスを指定します/整数IP/ヘキサデシマル
- m情報を表示するIPアドレスまたはIPセグメントを指定します
IPフォーマット1:192.168.1.1
IPフォーマット2:192.168.1.0/24
IPフォーマット3:192.168.1.1-192.168.1.254
0 x02DNS処理モジュール####
説明:Pythonのdbspythonは、DNSツールキットを実装し、すべてのレコードタイプをサポートし、ゾーン情報のクエリ/送信と動的更新に使用され、すべてのレコードタイプをサポートします。
モジュールのインストール: pip install dnspython
1. 詳細な方法#####
dnsは、クエリメソッドを使用してクエリ関数を実装するDNS解決クラスリゾルバを提供します。クエリメソッドは次のように定義されます。
import dns.resolver
def query(qname, rdtype=dns.rdatatype.A, rdclass=dns.rdataclass.IN,
tcp=False, source=None, raise_on_no_answer=True,
source_port=0, lifetime=None):
rdclassパラメーターは、ネットワークタイプを指定するために使用されます。オプションの値は、IN、CH、およびHSです。ここで、INがデフォルトです。
tcpパラメーターは、TCPプロトコルを有効にするかどうかを示します。
rdtypeパラメーターは、RRリソースタイプを指定するために使用されます。
- レコード:ホスト名をIPアドレスに変換する
- MXレコード:メールサーバーのドメイン名を定義するメール交換レコード
- CNAMEレコード:ドメイン名間のマッピングを実現するためのエイリアスレコードを指定します
- NSレコード:マークされたゾーンのドメイン名サーバーと許可されたサブドメイン名
- PTRレコード:逆解決は、IPアドレスをホスト名に変換するAレコードの反対です。
- SOAレコード:SOAは、開始認証ゾーンの定義をマークします
サンプルデモンストレーション:
# 例1.レコードが応答を渡す.クエリ応答情報を取得するためのanswerメソッド
for i in dns.resolver.query('www.qq.com.cn','A').response.answer:for j in i.items:print("記録:%s"% j.address) #記録:61.129.226.218for i in dns.resolver.query('qq.com','A').response.answer:for j in i.items:print("記録:%s"% j.address)
# 記録:59.37.96.63
# 記録:58.60.9.21
# 記録:180.163.26.39
# 例2.MXレコード
for i in dns.resolver.query('qq.com','MX'):print("MX preference = %s , mail exchanger = %s"%(i.preference,i.exchange))
# 設定とメール交換サーバーをトラバースします
# MX preference =20, mail exchanger = mx2.qq.com.
# MX preference =30, mail exchanger = mx1.qq.com.
# MX preference =10, mail exchanger = mx3.qq.com.
# 例3.NSレコード(ルートドメイン名を入力)
for i in dns.resolver.query('qq.com','NS').response.answer:for j in i.items:print("NSレコード:%s"%j)
# の結果
NSレコード:ns2.qq.com.
NSレコード:ns1.qq.com.
NSレコード:ns4.qq.com.
NSレコード:ns3.qq.com.
# 例4.CNAMEレコード
for i in dns.resolver.query('weiyigeek.github.io','CNAME').response.answer:for j in i.items:print("CNAMEレコード:%s"%j) #CNAMEレコード:www.weiyigeek.github.io.
# 例5.SOA認証領域の定義
for i in dns.resolver.query('baidu.com','SOA'):print(i)
# dns.baidu.com. sa.baidu.com.201214121830030025920007200
実際のケース:
[+ Githubで表示](https://github.com/WeiyiGeek/Study-Promgram/blob/master/Python3/Python%E5%AE%89%E5%85%A8%E5%B9%B3%E5%8F%B0% E5%BB%BA%E8%AE%BE / Scan / dnsinfo.py)

WeiyiGeek.dnsinfo情報ビュー
0 x01Web検出モジュール####
pycurlモジュール#####
説明:pycurlは、C言語で記述されたlibcurl Python実装であり、強力な関数と複数の通信プロトコルのサポートを備えています。LinuxのCurlコマンド関数に似たPythonパッケージは、シンプルで使いやすいです。
モジュールのインストール:
# インストール
pip install pycurl #エラーを報告する可能性があります指定してください--curl-dir=/path/to/built/libcurl(インストール後に再実行してください)
# エラーアクセスの場合:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pycurlダウンロードpycurl-7.43.0.3-cp37-cp37m-win32.whl(Pythonのバージョンによると)
Processing c:\users\weiyigeek\downloads\pycurl-7.43.0.3-cp37-cp37m-win32.whl
Installing collected packages: pycurl
Successfully installed pycurl-7.43.0.3
# バージョンを表示
python -c "import pycurl;print(pycurl.version)"'PycURL/7.43.0.3 libcurl/7.64.1 OpenSSL/1.1.1c zlib/1.2.11 c-ares/1.15.0 libssh2/1.8.2'
主な機能:
- Webサービス品質の検出:HTTPステータスコード/要求遅延/ HTTPヘッダー情報/ダウンロード速度など。
- 検出サービスの可用性とサービスの応答速度
モジュールの一般的な方法:
pcurl = pycurl.Curl #オブジェクトを作成する
pcurl.setopt(option,value) #curl_easy_setoptメソッド、値はオプションによって異なります
pcurl.perform() #pycurlオブジェクトのリクエスト送信を実現します
pcurl.getinfo(option) #pycurlオブジェクト要求応答情報を取得します
pcurl.close()
libcurlパッケージによって提供される定数値を使用して、Webサービスの品質を検出する目的を達成します:
# setopt
pc.setopt(pycurl.URL, URL) #要求されたURLを定義します
pc.setopt(pycurl.USERAGENT,"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0") #httpリクエストヘッダーUSERAGENTを設定します
pc.setopt(pycurl.CONNECTTIMEOUT,5) #接続待機時間、0は待機なしを意味します
pc.setopt(pycurl.TIMEOUT,5) #リクエストのタイムアウト
pc.setopt(pycurl.MAXREDIRS,1) #リダイレクトの最大数
pc.setopt(pycurl.NOPROGRESS,1) #ダウンロードの進行状況バーが0でない場合にブロックするかどうか、ブロックする
pc.setopt(pycurl.MAXREDIRS,1) #HTTPリダイレクトの最大数を1として指定します
pc.setopt(pycurl.DNS_CACHE_TIMEOUT,30) #DNS情報の報告エラーは30秒です
pc.setopt(pycurl.FORBID_REUSE,1) #再利用せずに対話を完了した後、切断します
pc.setopt(pycurl.FERSH_CONNECT,1) #新しい接続を強制して、キャッシュ内の接続を置き換えます
pc.setopt(pycurl.HEADERFUNCTION, getheader) #返されたHTTPHEADERをコールバック環境getheaderに送信します
pc.setopt(pycurl.WRITEFUNCTION, getbody) #返されたHTTPBOBYをコールバック環境getbobyに送信します
pc.setopt(pycurl.WRITEHEADER, index) #戻りHTTPHEADERをindexfileファイルオブジェクトに送信します
pc.setopt(pycurl.WRITEDATA, index) #返されたHTMLコンテンツをindexfileファイルオブジェクトに送信します
# getinfo
print("HTTPステータスコード: %s"%(pc.getinfo(pc.HTTP_CODE)))print("DNS解決時間: %.2f ms"%(pc.getinfo(pc.NAMELOOKUP_TIME)*1000))print("接続時間: %.2f ms"%(pc.getinfo(pc.CONNECT_TIME)*1000))print("時間を転送する準備ができました: %.2f ms"%(pc.getinfo(pc.PRETRANSFER_TIME)*1000))print("送信開始時間: %.2f ms"%(pc.getinfo(pc.STARTTRANSFER_TIME)*1000))print("送信終了までの合計時間: %.2f ms"%(pc.getinfo(pc.TOTAL_TIME)*1000))print("リダイレクト時間: %.2f ms"%(pc.getinfo(pc.REDIRECT_TIME)*1000))print("パケットサイズをダウンロード: %d bytes/s"%(pc.getinfo(pc.SIZE_DOWNLOAD)))print("アップロードパケットサイズ: %d bytes/s"%(pc.getinfo(pc.SIZE_UPLOAD)))print("平均ダウンロード速度: %d bytes/s"%(pc.getinfo(pc.SPEED_DOWNLOAD)))print("平均アップロード速度: %d bytes/s"%(pc.getinfo(pc.SPEED_UPLAOD)))print("HTTPヘッダーサイズ: %d byte"%(pc.getinfo(pc.HEADER_SIZE)))
実際のケース:
#! /usr/bin/env python
# - *- coding: utf-8-*-
# @ File : pycurldemo.py
# @ CreateTime :2019/7/3115:23
# @ Author : WeiyiGeek
# @ Function :Webサービスの品質とWebページのスクリーンショットの検出を実現します
# @ Software: PyCharm
import sys, time
import pycurl
URL="http://www.weiyigeek.github.io"
def request():"""
ビルドリクエスト
: return:"""
pc = pycurl.Curl() #Curlオブジェクトを作成します
pc.setopt(pycurl.URL, URL) #要求されたURLを定義します
pc.setopt(pycurl.CONNECTTIMEOUT,5) #接続待機時間、0は待機なしを意味します
pc.setopt(pycurl.TIMEOUT,5) #リクエストのタイムアウト
pc.setopt(pycurl.NOPROGRESS,1) #ダウンロードの進行状況バーはcurlに似ています
pc.setopt(pycurl.FORBID_REUSE,1) #再利用せずに対話を完了した後、切断します
pc.setopt(pycurl.MAXREDIRS,1) #HTTPリダイレクトの最大数を1として指定します
pc.setopt(pycurl.DNS_CACHE_TIMEOUT,30) #DNS情報の報告エラーは30秒です
pc.setopt(pycurl.USERAGENT,"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0")
# ファイルオブジェクトを作成して'wb'開く方法、返されたhttpヘッダー情報とページコンテンツを保存する;withopen('content.txt','wb')as index:
pc.setopt(pycurl.WRITEHEADER, index) #戻りHTTPHEADERをindexfileファイルオブジェクトに送信します
pc.setopt(pycurl.WRITEDATA, index) #返されたHTMLコンテンツをindexfileファイルオブジェクトに送信します
try:
pc.perform() #リクエストを送信
except Exception as e:print("connect Error:"+str(e))
sys.exit()return pc
def reponse(pc):"""
返品要求応答データ分析
: param pc::return:"""
print("HTTPステータスコード: %s"%(pc.getinfo(pc.HTTP_CODE)))print("DNS解決時間: %.2f ms"%(pc.getinfo(pc.NAMELOOKUP_TIME)*1000))print("接続時間: %.2f ms"%(pc.getinfo(pc.CONNECT_TIME)*1000))print("時間を転送する準備ができました: %.2f ms"%(pc.getinfo(pc.PRETRANSFER_TIME)*1000))print("送信開始時間: %.2f ms"%(pc.getinfo(pc.STARTTRANSFER_TIME)*1000))print("送信終了までの合計時間: %.2f ms"%(pc.getinfo(pc.TOTAL_TIME)*1000))print("パケットサイズをダウンロード: %d bytes/s"%(pc.getinfo(pc.SIZE_DOWNLOAD)))print("HTTPヘッダーサイズ: %d byte"%(pc.getinfo(pc.HEADER_SIZE)))print("平均ダウンロード速度: %d bytes/s"%(pc.getinfo(pc.SPEED_DOWNLOAD)))print("リダイレクト時間: %.2f ms"%(pc.getinfo(pc.REDIRECT_TIME)*1000))
pc.close()
def main():"""
関数呼び出しを要求する
応答関数呼び出し
: return:"""
pcurl =request()reponse(pcurl)return0if __name__ =='__main__':main()
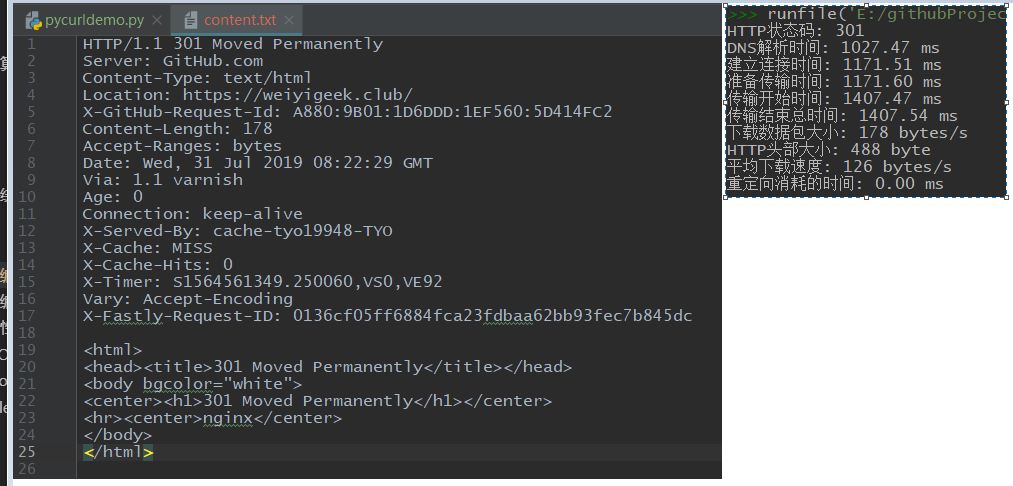
WeiyiGeek.pycurlモジュール
Recommended Posts