Pythonマルチスレッドの深い理解
Pythonのマルチスレッドは偽のマルチスレッドです。コアがいくつあっても、一度に操作できるコアは1つだけです。 Pythonのマルチスレッドを利用し、CPUコンテキストの切り替えを利用するだけでは、同時実行のように見えますが、実際には単一のスレッドであるため、偽の単一のスレッドです。
**では、いつマルチスレッドを使用しますか? ****
最初に知っておくべきこと:
- io操作はCPUを占有しません
- 2 + 5 = 5のように、計算操作はCPUを占有します
**Pythonのマルチスレッドは、CPUを集中的に使用する操作には適していませんが、SocketServer **などのioを集中的に使用するタスクには適していません。
**CPUを集中的に使用するタスクが増えた場合はどうなりますか? ****
まず、マルチプロセスのプロセスは独立していますが、pythonのスレッドはシステムのネイティブスレッドを使用し、pythonのプロセスもシステムのネイティブプロセスを使用することに注意してください。ネイティブプロセスはオペレーティングシステムによって維持されます。率直に言って、 Pythonは、Cネイティブコードライブラリのインターフェイスを使用してプロセスを開始します。実際のプロセス管理は引き続きオペレーティングシステムによって行われます。オペレーティングシステム自体にGILグローバルインタープリターロックがありますか?答えはノーで、2つのプロセスのいずれかです。相互のデータは完全に独立しており、相互にアクセスできないため、ロックの概念は不要であり、GILの概念はありません。したがって、この場合、各プロセスには少なくとも1つのスレッドがあります。オペレーティングシステムが8コアの場合はい、8つのプロセスを開始し、各プロセスにスレッドがあります。これは、8つのスレッド、8つのコアで実行される8つのスレッドに相当し、複数のコアを使用することと同等です。これで問題は解決します。
唯一の欠点は、8つのスレッド間のデータを独立して共有できないことです。この方法を使用すると、マルチコアコンピューティングの問題が危険にさらされる可能性があります。
まず、単純なマルチプロセスプログラムを見てください。
import multiprocessing
import time
def run(name):
time.sleep(2)print('hello', name)if __name__ =='__main__':for i inrange(10):
p = multiprocessing.Process(target=run, args=('bob%s'%i,))
p.start()
プログラムの実行結果は次のとおりです。
hello bob0
hello bob1
hello bob3
hello bob2
hello bob5
hello bob9
hello bob7
hello bob8
hello bob4
hello bob6
**したがって、プロセスIDを取得する場合、どのように取得すればよいですか? ****
from multiprocessing import Process
import os
def info(title):print(title)print('module name:', __name__)print('parent process:', os.getppid()) #親プロセスID
print('process id:', os.getpid()) #自身のプロセスのID
print("\n\n")
def f(name):info('3[31;1mfunction f3[0m')print('hello', name)if __name__ =='__main__':info('3[32;1mmain process line3[0m')
p =Process(target=f, args=('bob',))
p.start()
p.join()
プログラム実行の結果は次のとおりです。
main process line
module name: main
parent process: 5252
process id: 6576
function f
module name: mp_main
parent process: 6576
process id: 2232
hello bob
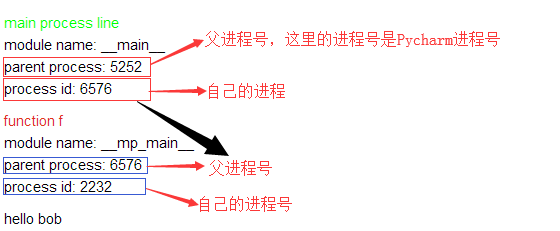
実際、この図は、すべての子プロセスが親プロセスによって開始されることを意味します。
プロセス間通信
2つのプロセス間のメモリは互いに独立していると言いますが、2つのプロセスは通信できますか?プロセスAがプロセスBのデータにアクセスするとしますが、アクセスできますか?絶対にアクセスできません!ただし、アクセスしたいだけです。つまり、2つの独立したメモリが相互にアクセスしたいので、どうすればよいですか。
方法はたくさんありますが、そうです!常に、ミドルウェアを見つける必要があることを意味します。ミドルウェアには非常に多くの種類があるので、最初にどれを見てみましょう。
キューの最初のタイプ
使用法は、スレッド化のキューに似ています
from multiprocessing import Process, Queue
def f(q):
q.put([42, None,'hello'])if __name__ =='__main__':
q =Queue()
p =Process(target=f, args=(q,))
p.start()print(q.get()) # prints "[42, None, 'hello']"
p.join()
これら2つのプロセスを見てみましょう。親プロセスのqはどのようにして子プロセスに渡されますか?話し合いましょう
ここで、データが共有され、2つのプロセスがqを共有すると思いますか?実際にはそうではありません。これは、qのクローンを作成し、親プロセスで子プロセスを作成することと同じです。つまり、親プロセスが独自のqをクローンします。コピーは子プロセスに渡され、子プロセスはこの時点でデータのコピーをこのqに入れ、親プロセスはそれを取得できます。次に、それを言うのは正しくありません。次に、qのクローンを作成します。つまり、2つのqを作成し、Bがデータをqに配置します。その後、別のqとは関係ありません。つまり、Aのq、ああ、これであるはずです。のように見えますが、実際には、データを共有したいですか?これは、Aとqのデータをシリアル化し、中間位置にシリアル化することと同じであり、中間位置に変換があります。このデータはAに逆シリアル化され、Aのqに配置されます。その後、いわゆるデータ共有が実現されます。
プログラム実行の結果は次のとおりです。
[42, None, ‘hello’]
2番目の種類のパイプ
Pipe()関数は、パイプで接続された接続オブジェクトを返します。これは、デフォルトでは二重(双方向)です。例えば:
from multiprocessing import Process, Pipe
def f(conn):
conn.send("父よ、お元気ですか?") #息子が送った
print("son receive:",conn.recv())
conn.close()if __name__ =='__main__':
parent_conn, child_conn =Pipe()
p =Process(target=f, args=(child_conn,))
p.start()print("father receive:",parent_conn.recv()) #父は受け取る
parent_conn.send("息子さん、お元気ですか?")
p.join()
プログラム実行の結果は次のとおりです。
父が受け取る:父、お元気ですか?
息子が受け取る:息子、お元気ですか?
Pipe()によって返される2つの接続オブジェクトは、パイプの両端を表します。各接続オブジェクトには、send()メソッドとrecv()メソッド(およびその他のメソッド)があります。 2つのプロセス(またはスレッド)がパイプの同じ端に対して同時に読み取りまたは書き込みを行おうとすると、パイプ内のデータが破損する可能性があることに注意してください。もちろん、パイプの異なる端を同時に使用する過程で損傷のリスクはありません。
3番目のタイプのマネージャー
Manager()によって返されるmanagerオブジェクトは、Pythonオブジェクトを保存し、他のプロセスがエージェントを使用してそれらを操作できるようにするサーバープロセスを制御します。
Manager()によって返されるマネージャーは、タイプリスト、dict、Namespace、Lock、RLock、Semaphore、BoundedSemaphore、Condition、Event、Barrier、Queue、Value、およびArrayをサポートします。例えば、
from multiprocessing import Process, Manager
import os
def f(d, l):
d[1]='1'
d['2']=2
d[0.25]= None
l.append(os.getpid())print(l)if __name__ =='__main__':withManager()as manager:
d = manager.dict() #特別な文法を使用して、複数のプロセス間で受け渡しおよび共有できる辞書を生成します
l = manager.list(range(5)) # #特別な構文を使用して、複数のプロセス間で受け渡しおよび共有できるリストを生成します。デフォルトには5つのデータがあります
p_list =[]for i inrange(10):
p =Process(target=f, args=(d, l))
p.start()
p_list.append(p)for res in p_list:
res.join()print(d)print(l)
プログラム実行の結果は次のとおりです。
[0, 1, 2, 3, 4, 2100]
[0, 1, 2, 3, 4, 2100, 7632]
[0, 1, 2, 3, 4, 2100, 7632, 5788]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904, 7888]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904, 7888, 7612]
{1: ‘1’, ‘2’: 2, 0.25: None}
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904, 7888, 7612]
プロセスロックとプロセスプール
プロセスロック
プロセスにもロックがあります、何ですか?プロセスはすべて独立していませんか?同じデータを同時に変更する必要はありませんが、どうすればロックできますか?
外観を見てみましょう。スレッドとほぼ同じです。
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()try:print('hello world', i)finally:
l.release()if __name__ =='__main__':
lock =Lock()for num inrange(10):Process(target=f, args=(lock, num)).start()
プログラム実行の結果は次のとおりです。
hello world 3
hello world 1
hello world 2
hello world 5
hello world 7
hello world 4
hello world 0
hello world 6
hello world 8
hello world 9
では、このロックは何をするのでしょうか?
実際には、画面に印刷されている情報が混乱しないようにする機能です!
プロセスプール
上記のプログラムでは、プロセスの開始は親プロセスのメモリデータのクローンであるため、100プロセスの開始は遅くなります。親プロセスがメモリ空間のGを占める場合、100プロセスを開始します。 101Gに相当します。この場合、オーバーヘッドが非常に大きくなります。プロセスを開始して家のクローンを作成するようなもので、しばらくするとHarbinがいっぱいになるため、オーバーヘッドが特に大きくなります。咵嚓を避けるために。多くのプロセスはシステムをダウンさせるため、プロセスプールには制限があります。
プロセスプールは、CPU上で同時に実行されているプロセスの数です。
プロセスプールには2つの方法があります。
- 適用(同期実行、シリアル)
- apply_async(非同期実行、並列)
from multiprocessing import Process,Pool,freeze_support
import time
import os
def Foo(i):
time.sleep(2)print("in process",os.getpid())return i+100
def Bar(arg):print('-- exec done:',arg)if __name__ =='__main__':freeze_support()
pool =Pool(5) #5つのプロセスを同時にプロセスプールに配置できるようにします
for i inrange(10):
# pool.apply_async(func=Foo, args=(i,),callback=Bar) #折り返し電話
pool.apply(func=Foo, args=(i,)) #シリアル
# pool.apply_async(func=Foo, args=(i,)) #平行
print('end')
pool.close()
pool.join() #プロセスプール内のプロセスは、実行が完了した後に閉じられます。コメントすると、プログラムは直接閉じられます。
プログラムの実行結果は次のとおりです。
in process 7824
in process 6540
in process 7724
in process 8924
in process 9108
in process 7824
in process 6540
ナレッジポイントの拡張:
__ name__ == '__ main__'の機能は次のとおりです。
このコードに関するプログラムを手動で実行すると、その下のプログラムが実行されます。このコードを呼び出すプログラムの場合、その下のプログラムは実行されません。
上記は、Pythonマルチスレッディングの詳細な理解です。Pythonマルチスレッディングの詳細については、ZaLou.Cnの他の関連記事に注意してください。
Recommended Posts