IV値を計算するPythonの例
変数をビニングした後、変数の重要度を計算する必要があります。IVは、変数の識別または重要度を評価するための統計の1つです。pythonでIV値を計算するためのコードは次のとおりです。
def CalcIV(Xvar, Yvar):
N_0 = np.sum(Yvar==0)
N_1 = np.sum(Yvar==1)
N_0_group = np.zeros(np.unique(Xvar).shape)
N_1_group = np.zeros(np.unique(Xvar).shape)for i inrange(len(np.unique(Xvar))):
N_0_group[i]= Yvar[(Xvar == np.unique(Xvar)[i])&(Yvar ==0)].count()
N_1_group[i]= Yvar[(Xvar == np.unique(Xvar)[i])&(Yvar ==1)].count()
iv = np.sum((N_0_group/N_0 - N_1_group/N_1)* np.log((N_0_group/N_0)/(N_1_group/N_1)))return iv
def caliv_batch(df, Kvar, Yvar):
df_Xvar = df.drop([Kvar, Yvar], axis=1)
ivlist =[]for col in df_Xvar.columns:
iv =CalcIV(df[col], df[Yvar])
ivlist.append(iv)
names =list(df_Xvar.columns)
iv_df = pd.DataFrame({'Var': names,'Iv': ivlist}, columns=['Var','Iv'])return iv_df
その中で、dfはビニング後のデータセット、Kvarはプライマリキー、Yvarはy変数です(0は良い、1は悪い)。
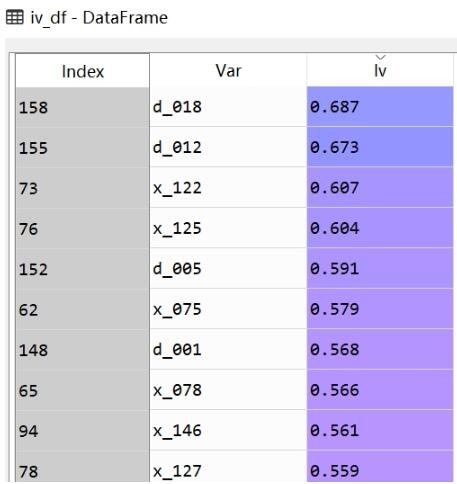
コード実行の結果は次のとおりです。
補足拡張:python基本IV(スライス、反復、リストの生成)
リストをスライスする
リストのいくつかの要素を取得することは非常に一般的な操作です。たとえば、リストは次のとおりです。
L = [‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
最初の3つの要素を取るにはどうすればよいですか?
愚かな方法:
[ L[0], L[1], L[2]]
[ ‘Adam’, ‘Lisa’, ‘Bart’]
愚かな方法の理由は、最初のN個の要素を取るように拡張されているためです。
最初のN個の要素、つまりインデックス0-(N-1)の要素を取得すると、ループを使用できます。
r =[]
n =3for i inrange(n):... r.append(L[i])...
r
[' Adam','Lisa','Bart']
指定されたインデックス範囲をとることが多いこのタイプの操作では、ループを使用するのは非常に面倒です。したがって、Pythonにはスライス(スライス)演算子が用意されており、この操作を大幅に簡素化できます。
上記の質問に対応して、最初の3つの要素を取得し、1行のコードを使用してスライスを完成させます。
L[0:3]
[ ‘Adam’, ‘Lisa’, ‘Bart’]
L [0:3]は、インデックス0から始まり、インデックス3で終わることを意味しますが、インデックス3は含まれません。つまり、インデックス0、1、2は正確に3つの要素です。
最初のインデックスが0の場合、以下を省略することもできます。
L[:3]
[ ‘Adam’, ‘Lisa’, ‘Bart’]
インデックス1から始めて、2つの要素を取り出すこともできます。
L[1:3]
[ ‘Lisa’, ‘Bart’]
1つだけ使用してください:これは最初から最後までを意味します:
L[:]
[ ‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
したがって、L [:]は実際に新しいリストをコピーしました。
スライス操作では、3番目のパラメーターを指定することもできます。
L[::2]
[ ‘Adam’, ‘Bart’]
3番目のパラメーターは、Nごとに1つを取ることを意味します。上記のL [:: 2]は、2つの要素ごとに1つを取る、つまり、1つおきに取ります。
リストをタプルに置き換えると、スライス操作はまったく同じですが、スライスの結果もタプルになります。
リバーススライス
リストの場合、PythonはL [-1]をサポートして下から最初の要素を取得するため、相互スライスもサポートしています。試してみてください。
L =['Adam','Lisa','Bart','Paul']
L[-2:]['Bart','Paul']
L[:-2]['Adam','Lisa']
L[-3:-1]['Lisa','Bart']
L[-4:-1:2]['Adam','Bart']
最後の要素のインデックスは-1であることを忘れないでください。リバーススライスには開始インデックスが含まれますが、終了インデックスは含まれません。
スライスストリング
文字列「xxx」とユニコード文字列u「xxx」も一種のリストと見なすことができ、各要素は文字です。したがって、文字列をスライスすることもできますが、操作の結果は文字列のままです。
' ABCDEFG'[:3]'ABC''ABCDEFG'[-3:]'EFG''ABCDEFG'[::2]'ACEG'
多くのプログラミング言語では、文字列に対してさまざまな傍受関数が提供されていますが、目的は文字列をスライスすることです。 Pythonには文字列のインターセプト機能がなく、1つの操作をスライスするだけで完了できます。これは非常に簡単です。
反復とは
Pythonでは、リストまたはタプルが指定されている場合、forループを介してリストまたはタプルをトラバースできます。このトラバースは、反復と呼ばれます。
Pythonでは、反復はfor…inで実行されますが、CやJavaなどの多くの言語では、反復リストはJavaコードなどの添え字で実行されます。
for(i=0; i<list.length; i++){
n = list[i];}
PythonのforループはJavaのforループよりも抽象的であることがわかります。
Pythonのforループは、リストやタプルだけでなく、他の反復可能なオブジェクトでも使用できるためです。
したがって、反復操作はコレクションに対するものであり、コレクションが順序付けされているかどうかに関係なく、いつでもforループを使用してコレクションの各要素を順番に取得できます。
注:コレクションとは、要素のグループを含むデータ構造を指します。導入したものは次のとおりです。
-
順序付けられたコレクション:リスト、タプル、str、およびユニコード。
-
順序付けられていないコレクション:セット
-
キーと値のペアを持つ順序付けられていないコレクション:dict
そして、反復は動詞であり、操作を参照します。Pythonでは、forループです。
インデックスによる配列の反復とアクセスの最大の違いは、後者は特定の反復実装であり、前者は反復の結果のみを考慮し、内部での実装方法は考慮しないことです。
インデックスの反復
Pythonでは、反復は常に要素のインデックスではなく、要素自体を取り出します。
順序付けられたコレクションの場合、要素は実際にインデックスが付けられます。時々、本当にforループでインデックスを取得したいのですが、どうすればよいですか?
この方法は、enumerate()関数を使用することです。
L =['Adam','Lisa','Bart','Paul']for index, name inenumerate(L):... print index,'-', name
...0- Adam
1- Lisa
2- Bart
3- Paul
enumerate()関数を使用して、forループ内のインデックスインデックスと要素名の両方をバインドできます。ただし、これはenumerate()の特別な構文ではありません。実際、enumerate()関数は次のようになります。
[ ‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
次のようになります:
[(0, ‘Adam’), (1, ‘Lisa’), (2, ‘Bart’), (3, ‘Paul’)]
したがって、反復の各要素は実際にはタプルです。
for t inenumerate(L):
index = t[0]
name = t[1]
print index,'-', name
各タプル要素に2つの要素が含まれていることがわかっている場合、forループはさらに次のように省略できます。
for index, name in enumerate(L):
print index, ‘-‘, name
これにより、コードが単純になるだけでなく、2つの割り当てステートメントが不要になります。
インデックスの反復は実際にはインデックスによってアクセスされないことがわかりますが、enumerate()関数は自動的に各要素を(index、element)のようなタプルに変換してから反復し、インデックスと要素自体の両方を取得します。
dictの値を繰り返します
dictオブジェクト自体が反復可能なオブジェクトであることはすでに理解しています。forループを使用してdictを直接反復すると、毎回dictのキーを取得できます。
dictオブジェクトの値を繰り返し処理する場合は、どうすればよいですか?
dictオブジェクトにはvalues()メソッドがあります。このメソッドは、dictをすべての値を含むリストに変換するため、dictの各値を繰り返し処理します。
d ={'Adam':95,'Lisa':85,'Bart':59}
print d.values()
# [85,95,59] for v in d.values():
print v
# 85
# 95
# 59
Pythonのドキュメントを注意深く読むと、values()メソッドに加えて、dictにもitervalues()メソッドがあることがわかります。values()メソッドをitervalues()メソッドに置き換えます。反復効果はまったく同じです。
d ={'Adam':95,'Lisa':85,'Bart':59}
print d.itervalues()
# < dictionary-valueiterator object at 0x106adbb50for v in d.itervalues():
print v
# 85
# 95
# 59
**これら2つの方法の違いは何ですか? ****
-
values()メソッドは、実際にはdictを値を含むリストに変換します。
-
ただし、itervalues()メソッドは変換せず、反復プロセスでdictから値を取得するため、itervalues()メソッドはvalues()メソッドよりもリストの生成に必要なメモリを節約します。
-
itervalues()を出力し、それが<dictionary-valueiterator 对象,这说明在Python中,for 循环可作用的迭代对象远不止 list,tuple,str,unicode,dict等,任何可迭代对象都可以作用于for循环,而内部如何迭代我们通常并不用关心。
オブジェクトが反復可能であると言われる場合は、直接forループを使用して反復します。反復は抽象データ操作であり、反復オブジェクト内のデータに対する要件がないことがわかります。
dictのキーと値を繰り返します
dictのキーと値を繰り返す方法を知っているので、forループで、キーと値を同時に繰り返すことができますか?答えはイエスです。
まず、dictオブジェクトのitems()メソッドによって返される値を見てみましょう。
d ={'Adam':95,'Lisa':85,'Bart':59}
print d.items()[('Lisa',85),('Adam',95),('Bart',59)]
ご覧のとおり、items()メソッドはdictオブジェクトをタプルを含むリストに変換し、このリストを繰り返してキーと値を同時に取得します。
for key, value in d.items():... print key,':', value
...
Lisa :85
Adam :95
Bart :59
values()と同様に、itervalues()があり、items()にも対応するiteritems()があり、iteritems()はdictをlistに変換しませんが、反復プロセス中に常にタプルを与えるため、iteritems()は占有しません。追加のメモリ。
リストを生成
リスト[1、2、3、4、5、6、7、8、9、10]を生成するには、range(1、11)を使用できます。
range(1, 11)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
しかし、[1×1、2×2、3×3、…、10×10]を生成したい場合はどうでしょうか。方法1はループしています:
L =[]for x inrange(1,11):... L.append(x * x)...
L
[1,4,9,16,25,36,49,64,81,100]
ただし、ループは煩雑すぎるため、リストの生成ではlineステートメントを使用してループを置き換え、上記のリストを生成できます。
[ x * x for x inrange(1,11)][1,4,9,16,25,36,49,64,81,100]
この書き方は、Python固有のリスト生成です。リスト生成式を使用すると、非常に簡潔なコードでリストを生成できます。
リストプロダクションを作成するときは、生成する要素x * xを先頭に配置し、その後にforループを配置すると、リストを作成できます。これは非常に便利です。数回作成すると、すぐにこの構文に慣れることができます。
複雑な表現
forループを使用した反復では、通常のリストを反復するだけでなく、dictも反復できます。
次のdictがあるとします。
d = { ‘Adam’: 95, ‘Lisa’: 85, ‘Bart’: 59 }
複雑なリストを生成することで、HTMLテーブルに変換できます。
tds =['<tr <td %s</td <td %s</td </tr '%(name, score)for name, score in d.iteritems()]
print '<table '
print '<tr <th Name</th <th Score</th <tr '
print '\n'.join(tds)
print '</table '
注:文字列は%でフォーマットでき、%sを指定されたパラメーターに置き換えます。文字列のjoin()メソッドは、リストを文字列に連結できます。
条件フィルタリング
リスト作成式のforループの後にif判定を追加できます。例えば:
[ x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
range()を変更せずに、偶数の2乗のみが必要な場合は、次のフィルターを追加できます。
[ x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
if条件では、判断がTrueの場合にのみ、ループの現在の要素がリストに追加されます。
マルチレベル式
forループはネストできるため、リストの作成では、複数のforループを使用してリストを生成することもできます。
文字列「ABC」および「123」の場合、2層のループを使用して完全な順列を生成できます。
[ m + n for m in ‘ABC’ for n in ‘123’]
[ ‘A1’, ‘A2’, ‘A3’, ‘B1’, ‘B2’, ‘B3’, ‘C1’, ‘C2’, ‘C3’]
次のようなループコードに変換されます。
L =[]for m in'ABC':for n in'123':
L.append(m + n)
上記のPythonでIV値を計算する例は、エディターが共有するすべてのコンテンツです。参考にしてください。
Recommended Posts