Python正規式サンプルコード
reモジュールは、Python言語にすべての通常の式関数を持たせます。
使用される構文
| 通常の文字 | 解釈 | 例 |
|---|---|---|
| + | 前の要素は少なくとも1回出現します | ab +:ab、abbbbなど |
| * | 前の要素が0回以上出現する | ab *:a、ab、abbなど |
| ? | 前の1回または0回一致 | Ab?:A、Abなど |
| ^ | 開始タグとして | ^ a:abc、aaaaaaなど |
| $ | 終了タグとして | c $:abc、ccccなど |
| \ d | 番号 | 3、4、9およびその他の通常の文字解釈の例+前の要素が少なくとも1回出現するab +:ab、abbbbなど。*前の要素が0回以上出現するab *:a、ab、abbなど?前の要素と一致するか、 0 Ab?:A、Abなど^開始タグとして^ a:abc、aaaaaaなど。$終了タグとしてc $:abc、ccccなど。\ d番号3、4、9など\ D非番号A、a、-など。 [az] Aとzの間の任意の文字a、p、mなど[0-9] 0から9までの任意の数字0、2、9など |
| 通常の文字 | 解釈 | 例 |
| + | 前の要素は少なくとも1回出現します | ab +:ab、abbbbなど |
| * | 前の要素が0回以上出現する | ab *:a、ab、abbなど |
| ? | 前の1回または0回一致 | Ab?:A、Abなど |
| ^ | 開始タグとして | ^ a:abc、aaaaaaなど |
| $ | 終了タグとして | c $:abc、ccccなど |
| \ d | 数字 | 3、4、9など |
| \ D | 非番号 | A、a、-など |
| [ az] | Aとzの間の任意の文字 | a、p、mなど |
| [0- 9] | 0 9 | 0、2、9などまでの任意の数 |
| \ D | 非番号 | A、a、-など |
| [ az] | Aとzの間の任意の文字 | a、p、mなど |
| [0- 9] | 0 9 | 0、2、9などまでの任意の数 |
注意:
- エスケープキャラクター
s
'( abc)def'
m = re.search("(\(.*\)).*", s)
print m.group(1)(abc)
re.match関数
re.matchは、文字列の先頭からパターンを照合しようとします。最初に照合が成功しなかった場合、match()はnoneを返します。
例1:
#! /usr/bin/python
# - *- coding: UTF-8-*-import re
print(re.match('www','www.zalou.cn').span()) #開始時に一致
print(re.match('net','www.zalou.cn')) #最初は一致しません
出力結果:
(0, 3)
None
例2:
#! /usr/bin/python
import re
line ="Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)else:
print "No match!!"
出力結果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
上記はpython2の印刷出力です。pythonに()を追加することを忘れないでください。pythonの出力は、取得したコンテンツと一致するように他の言語の\ nと同様です。
python group()
通常の式では、group()を使用してグループ化によってインターセプトされた文字列を提案し、()を使用してグループ化します。
前の文字列を複数回繰り返します
a ="kdlal123dk345"
b ="kdlal123345"
m = re.search("([0-9]+(dk){0,1})[0-9]+", a)
m.group(1), m.group(2)('123dk','dk')
m = re.search("([0-9]+(dk){0,1})[0-9]+", b)
m.group(1)'12334'
m.group(2)
理由
- 正規式の3セットの括弧は、マッチング結果を3つのグループに分割します
group()はgroup(0)と同じで、通常の式の全体的な結果と一致します。
group(1)は最初のブラケット一致部分をリストし、group(2)は2番目のブラケット一致部分をリストし、group(3)は3番目のブラケット一致部分をリストします。
2. 成功した一致がない場合、re.search()はNoneを返します
- もちろん、通常の式には括弧はなく、group(1)は間違いなく間違っています。
例
- 文字列がすべて小文字かどうかを判断します
# - *- coding: cp936 -*-import re
s1 ='adkkdk'
s2 ='abc123efg'
an = re.search('^[a-z]+$', s1)if an:
print 's1:', an.group(),'すべて小文字'else:
print s1,"すべてが小文字ではありません!"
an = re.match('[a-z]+$', s2)if an:
print 's2:', an.group(),'すべて小文字'else:
print s2,"すべてが小文字ではありません!"
結果

理由
-
通常の式はpythonの一部ではありません。使用する場合は、reモジュールを引用する必要があります。
-
一致する形式は、re.search(通常の式、一致する文字列)またはre.match(通常の式、一致する文字列)です。 2つの違いは、後者はデフォルトで開始文字(^)で始まることです。したがって、
re.search( '^ [az] +'、s1)はre.match( '[a-z] +'、s2)と同等です
- 一致が失敗した場合、a = re.search( '^ [az] + $'、s1)はNoneを返します
groupは、一致する結果をグループ化するために使用されます
例えば
import re
a ="123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,全体に戻る
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
出力結果
123 abc456
123
abc
456
1 )正規式の3セットの括弧は、マッチング結果を3つのグループに分割します
group()はgroup(0)と同じで、通常の式の全体的な結果と一致します。
group(1)は最初のブラケット一致部分をリストし、group(2)は2番目のブラケット一致部分をリストし、group(3)は3番目のブラケット一致部分をリストします。
2 )一致するものがない場合、re.search()はNoneを返します
3 )もちろん、通常の式には括弧はなく、group(1)は間違いなく間違っています。
2. 頭字語の拡張
具体例
FEMA Federal Emergency Management Agency
IRA Irish Republican Army
DUP Democratic Unionist Party
FDA Food and Drug Administration
OLC Office of Legal Counsel
分析
略語FEMA
F *** E *** M *** A ***に分解
通常の大文字+小文字(1以上)+スペース
参照コード
import re
def expand_abbr(sen, abbr):
lenabbr =len(abbr)
ma =''for i inrange(0, lenabbr):
ma += abbr[i]+"[a-z]+"+' '
print 'ma:', ma
ma = ma.strip(' ')
p = re.search(ma, sen)if p:return p.group()else:return''
print expand_abbr("Welcome to Algriculture Bank China",'ABC')
結果

問題
上記のコードは、例の最初の3つについては正しいですが、大文字で始まる単語も小文字の単語と混合されているため、後の2つは間違っています。
法律
大文字+小文字(1以上)+スペース+ [小文字+スペース](0次或1次)
参照コード
import re
def expand_abbr(sen, abbr):
lenabbr =len(abbr)
ma =''for i inrange(0, lenabbr-1):
ma += abbr[i]+"[a-z]+"+' '+'([a-z]+ )?'
ma += abbr[lenabbr-1]+"[a-z]+"
print 'ma:', ma
ma = ma.strip(' ')
p = re.search(ma, sen)if p:return p.group()else:return''
print expand_abbr("Welcome to Algriculture Bank of China",'ABC')
スキル
中央の小文字のセット+スペースは、全体として、括弧を追加します。同時にまたは同時にではないので、それを使用する必要がありますか? 、先に全体を合わせるために。
3. 番号のコンマを削除
具体例
自然言語を扱う場合、123,000,000を句読点で割ると問題が発生します。適切な数値はコンマで区切られているため、最初に数値を処理できます(カンマを削除します)。
分析
多くの場合、番号は3つの番号のグループであり、その後にコンマが続くため、ルールは***、***、***です。
正規表現
[ a-z]+,[a-z]?
参照コード3-1
import re
sen ="abc,123,456,789,mnp"
p = re.compile("\d+,\d+?")for com in p.finditer(sen):
mm = com.group()
print "hi:", mm
print "sen_before:", sen
sen = sen.replace(mm, mm.replace(",",""))
print "sen_back:", sen,'\n'
結果

スキル
関数finditer(string [、pos [、endpos]])| re.finditer(pattern、string [、flags])を使用します。
文字列を検索し、各一致結果(Matchオブジェクト)に順番にアクセスするイテレーターを返します。
参照コード3-2
sen ="abc,123,456,789,mnp"while1:
mm = re.search("\d,\d", sen)if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",",""))
print sen
else:break
結果
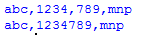
拡張する
このようなプログラムは、特定の問題、つまり3桁のグループを対象としています。数字が文字と混在している場合は、数字の間のコンマを削除します。つまり、「abc、123,4,789、mnp」を「abc、1234789、mnp」に変換します。
アイデア
具体的には、「number、number」という正規表現を見つけて、削除したコンマに置き換えます。
参照コード3-3
sen ="abc,123,4,789,mnp"while1:
mm = re.search("\d,\d", sen)if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",",""))
print sen
else:break
print sen
結果

4. 中国の処理の年換算(例:1949-1949)
中国の処理にはコーディングの問題が含まれます。たとえば、以下のプログラムが年(****年)を認識する場合
# - *- coding: cp936 -*-import re
m0 ="ニューチャイナは1949年に設立されました"
m1 ="1990年より5.2%低い"
m2 ='男は1996年にロシア軍を破った,実質的な独立を達成'
def fuc(m):
a = re.findall("[ゼロ|1|二|三|四|ファイブ|6|セブン|8|ナイン]+年", m)if a:for key in a:
print key
else:
print "NULL"fuc(m0)fuc(m1)fuc(m2)
運用結果

2番目と3番目にエラーがあることがわかります。
改善-ユニコード認識への標準化
# - *- coding: cp936 -*-import re
m0 ="ニューチャイナは1949年に設立されました"
m1 ="1990年より5.2%低い"
m2 ='男は1996年にロシア軍を破った,実質的な独立を達成'
def fuc(m):
m = m.decode('cp936')
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", m)if a:for key in a:
print key
else:
print "NULL"fuc(m0)fuc(m1)fuc(m2)
結果

漢字を数字に置き換えることで認識できます。
参照
numHash ={}
numHash['ゼロ'.decode('utf-8')]='0'
numHash['1'.decode('utf-8')]='1'
numHash['二'.decode('utf-8')]='2'
numHash['三'.decode('utf-8')]='3'
numHash['四'.decode('utf-8')]='4'
numHash['ファイブ'.decode('utf-8')]='5'
numHash['6'.decode('utf-8')]='6'
numHash['セブン'.decode('utf-8')]='7'
numHash['8'.decode('utf-8')]='8'
numHash['ナイン'.decode('utf-8')]='9'
def change2num(words):
print "words:",words
newword =''for key in words:
print key
if key in numHash:
newword += numHash[key]else:
newword += key
return newword
def Chi2Num(line):
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", line)if a:
print "------"
print line
for words in a:
newwords =change2num(words)
print words
print newwords
line = line.replace(words, newwords)return line
**5. | **で区切られた複数の携帯電話番号
例えば:
ヌル値
12222222222
12222222222|12222222222
12222222222|12222222222|12222222444
表現
s = “[\d]{11}(\|[\d]{11})*|”
4.推奨
Python正規表現ガイド
これまでのところ、python正規式のサンプルコードに関するこの記事を紹介します。より関連性の高いpython正規式のサンプルコンテンツについては、ZaLou.Cnで以前の記事を検索するか、以下の関連記事を引き続き参照してください。今後、ZaLou.Cnをさらにサポートしていただければ幸いです。
Recommended Posts