Ubuntu build etcd
1. Introduction#
etcd is a highly available distributed key-value database. etcd internally uses the raft protocol as a consensus algorithm, and etcd is implemented based on the Go language.
There are many systems that provide configuration sharing and service discovery. The most well-known one is [Zookeeper] (hereinafter referred to as ZK), and ETCD can be regarded as a rising star. ETCD has advantages over Zookeeper in terms of project implementation, easy understanding of the consensus protocol, operation and maintenance, and security.
etcd is a service discovery system with the following characteristics:
- Simple: installation and configuration are simple, and HTTP API is provided for interaction, and it is also very simple to use
- Security: Support SSL certificate verification
- Fast: According to the official benchmark data, a single instance supports 2k+ read operations per second
- Reliable: The raft algorithm is used to achieve the availability and consistency of distributed system data

Two, ETCD vs ZK
This article selects ZK as a typical representative to compare with ETCD, and does not consider the [Consul] project as the comparison object, because the reliability and stability of Consul still need time to verify (the project initiator does not use Consul for its own services, and does not use it. ).
- Conformance protocol: ETCD uses [Raft] protocol, ZK uses ZAB (PAXOS-like protocol), the former is easy to understand and facilitate engineering implementation;
- Operation and maintenance: ETCD is convenient for operation and maintenance, while ZK is difficult for operation and maintenance;
- Project activity: ETCD community and development are active, ZK is dying;
- API: ETCD provides HTTP+JSON, gRPC interfaces, cross-platform and cross-language, ZK needs to use its client;
- Access security: ETCD supports HTTPS access, ZK lacks in this aspect;
Three, application scenarios#
Similar to ZK, ETCD has many usage scenarios, including:
- Configuration management
- Service registered in discovery
- Elect
- Application scheduling
- Distributed queue
- Distributed lock
Four, read and write performance#
According to the [Benchmark] given on the official website, under the configuration of 2CPU, 1.8G memory, and SSD disk, the write performance of a single node can reach 16K QPS, and the write first and then read can also reach 12K QPS. This performance is quite impressive.
Five, working principle#
ETCD uses the Raft protocol to maintain the consistency of the state of each node in the cluster. Simply put, the ETCD cluster is a distributed system that consists of multiple nodes communicating with each other to form an overall external service. Each node stores complete data, and the Raft protocol ensures that the data maintained by each node is consistent.
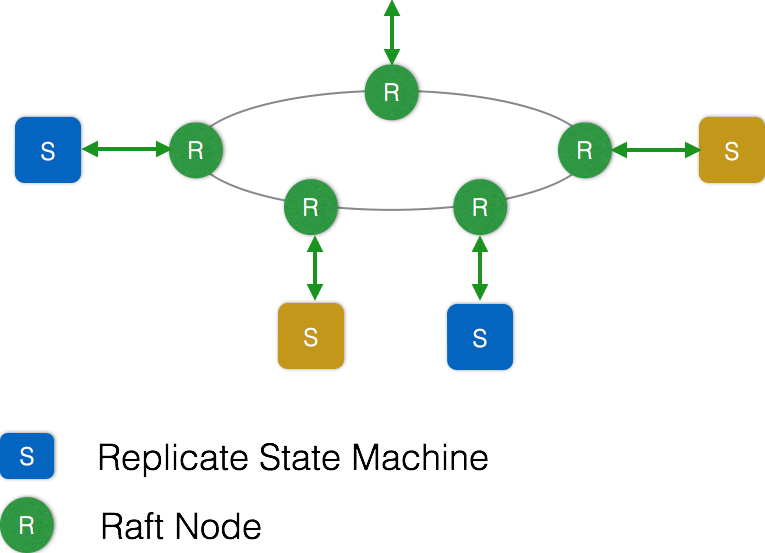
As shown in the figure, each ETCD node maintains a state machine, and there is at most one effective master node at any time. The master node processes all write operations from the client, and through the Raft protocol, it ensures that the changes to the state machine by the write operations will be reliably synchronized to other nodes.
The core part of the working principle of ETCD lies in the Raft protocol. The next section of this section will briefly introduce the Raft protocol. For details, please refer to its [paper].
As stated in the paper, the Raft protocol is indeed easy to understand. It is mainly divided into three parts: master selection, log replication, and security.
Choose Master##
The Raft protocol is a protocol used to maintain the data consistency of a group of service nodes. This group of service nodes form a cluster, and there is a master node to provide services to the outside world. When the cluster is initialized or the master node goes down, it faces a master election problem. Each node in the cluster is in one of the three roles of Leader, Follower, and Candidate at any time. The election features are as follows:
- When the cluster is initialized, each node is a follower role;
- There is at most 1 valid master node in the cluster, which synchronizes data with other nodes through heartbeat;
- When Follower does not receive a heartbeat from the master node within a certain period of time, it will change its role to Candidate and initiate a vote for the leader; when it receives approval from more than half of the nodes including itself, the election is successful; when it receives insufficient votes Half of the elections have failed or the elections have timed out. If the master node is not selected in this round, the next round of elections will be conducted (this happens because multiple nodes are elected at the same time, and all nodes have more than half of the votes).
- After the Candidate node receives the information from the master node, it will immediately terminate the election process and enter the follower role.
In order to avoid falling into a loop of failure to elect the master, the time for each node to initiate an election without receiving a heartbeat is a random value within a certain range, which can prevent two nodes from initiating the election at the same time.
Log Copy##
The so-called log replication means that the master node forms a log entry for each operation, persists it to the local disk, and then sends it to other nodes through the network IO. Logical clock of other nodes according to log(TERM)And log number(INDEX)To determine whether to persist the log record to the local. When the master node receives a successful return from more than half of the nodes including itself, then the log is considered submitable(committed), and input the log to the state machine, and return the result to the client.
It should be noted here that each time the master is selected, a unique TERM number will be formed, which is equivalent to a logical clock. Each log has a globally unique number.
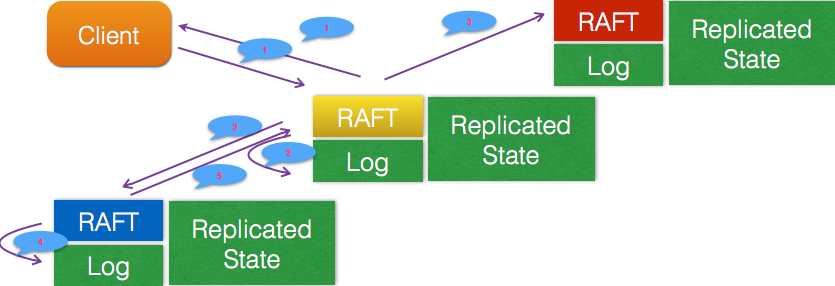


The master node adds logs to other nodes through network IO. If a node receives a log append message, it first determines whether the TERM of the log has expired, and whether the INDEX of the log entry is earlier than the INDEX of the current and submitted logs. If it has expired or is earlier than the submitted log, then the append is rejected and the current submitted log number of the node is returned. Otherwise, append the log and return success.
When the master node receives a reply from other nodes about log addition, if it finds that there is a rejection, it will generate the next log of its number according to the submitted log number returned by the node.
The master node synchronizes logs like other nodes and also controls congestion. Specifically, if the master node finds that the target node of log replication rejects a certain log append message, it will enter the log detection phase and send logs one by one until the target node accepts the log, and then enter the fast replication phase, where batch log appends can be performed.
According to the logic of log replication, we can see that the slow node in the cluster does not affect the performance of the entire cluster. Another feature is that the data is only copied from the main node to the follower node, which greatly simplifies the logic flow.
safety##
As of this moment, master selection and log replication cannot guarantee data consistency between nodes. Imagine that when a certain node goes down, it restarts again after a period of time and becomes the master node. During the time it hangs, if more than half of the nodes in the cluster survive, the cluster will work normally, and then the log will be submitted. These submitted logs cannot be delivered to the down node. When the dead node is elected as the master node again, it will lose some of the submitted logs. In this scenario, according to the Raft protocol, it copies its own logs to other nodes, and overwrites the logs that the cluster has submitted.
This is clearly unacceptable.
Other protocols to solve this problem are that the newly elected master node will ask other nodes to compare with its own data to determine that the cluster has submitted data, and then synchronize the missing data. This solution has obvious flaws, which increases the time it takes for the cluster to resume service (the cluster is not serviceable during the election phase), and it increases the complexity of the protocol.
Raft's solution is to limit the nodes that can become the master in the master selection logic to ensure that the selected node has all the logs submitted by the cluster. If the newly selected master node already contains all the submitted logs of the cluster, there is no need to compare data from other nodes. Simplifies the process and shortens the time for the cluster to restore services.
There is a problem here. After such restrictions are imposed, can the Lord be elected? The answer is: as long as there are still more than half of the nodes alive, such a master must be selected. Because the submitted logs must be persisted by more than half of the nodes in the cluster, it is obvious that the last log submitted by the previous master node is also persisted by most of the nodes in the cluster. When the master node is down, most of the nodes in the cluster are still alive, so there must be a node in the surviving node that contains the submitted log.
At this point, the introduction to the Raft protocol is all over.
Six, use cases#
According to public information, at least CoreOS, Google Kubernetes, Cloud Foundry, and more than 500 projects on Github are using ETCD.
Seven, interface#
ETCD provides HTTP protocol and supports Google gRPC access in the latest version. The specific support interface is as follows:
- ETCD is a highly reliable KV storage system that supports PUT/GET/DELETE interfaces;
- In order to support service registration and discovery, support WATCH interface (implemented through http long poll);
- Support KEY to hold TTL attribute;
- CAS (compare and swap) operation;
- Support multi-key transaction operations;
- Support directory operations
8. Formal installation (single node)
etcd is generally recommended for cluster deployment in a production environment. Here, I mainly talk about single-node installation and basic use.
Because etcd is written in go language, the installation only needs to download the corresponding binary file and put it in the appropriate path.
Download package##
Visit the download link:
https://github.com/etcd-io/etcd/releases
The latest version is 3.3.10, so the complete download link is as follows:
https://github.com/etcd-io/etcd/releases/download/v3.3.10/etcd-v3.3.10-linux-amd64.tar.gz
installation##
The system used in this article is: ubuntu-16.04.5-server-amd64
wget https://github.com/etcd-io/etcd/releases/download/v3.3.10/etcd-v3.3.10-linux-amd64.tar.gztar zxvf etcd-v3.3.10-linux-amd64.tar.gzmv etcd-v3.3.10-linux-amd64 /opt/etcd-v3.3.10
The decompressed file is as follows:
root@ubuntu:/opt/etcd-v3.3.10# lsdefault.etcd Documentation etcd etcdctl README-etcdctl.md README.md READMEv2-etcdctl.md
Among them, etcd is the server side and etcdctl is the client side. After the operation, a default.etcd will be generated, which is mainly used to store etct data.
To start a single-node etcd service, you only need to run the etcd command. However, the following problems may occur:
root@ubuntu:/opt/etcd-v3.3.10# ./etcd bash:./etcd:Insufficient permissions
At this time, you need to increase the file permissions, using the following methods:
root@ubuntu:/opt/etcd-v3.3.10# chmod 755 etcd
Start etcd again
root@ubuntu:/opt/etcd-v3.3.10# ./etcd
After success, you can see the following prompt:
2018- 11- 1115:46:43.134431 I | etcdmain: etcd Version:3.3.102018-11-1115:46:43.134941 I | etcdmain: Git SHA: 27fc7e2
2018- 11- 1115:46:43.135324 I | etcdmain: Go Version: go1.10.42018-11-1115:46:43.135572 I | etcdmain: Go OS/Arch: linux/amd64
2018- 11- 1115:46:43.135781 I | etcdmain: setting maximum number of CPUs to 1, total number of available CPUs is1
2018- 11- 1115:46:43.136055 W | etcdmain: no data-dir provided, using default data-dir ./default.etcd
2018- 11- 1115:46:43.136331 N | etcdmain: the server is already initialized as member before, starting as etcd member...2018-11-1115:46:43.136847 I | embed: listening for peers on http://localhost:23802018-11-1115:46:43.137159 I | embed: listening for client requests on localhost:23792018-11-1115:46:43.138055 I | etcdserver: name =default2018-11-1115:46:43.138328 I | etcdserver: data dir =default.etcd
2018- 11- 1115:46:43.138718 I | etcdserver: member dir =default.etcd/member
2018- 11- 1115:46:43.139011 I | etcdserver: heartbeat = 100ms
2018- 11- 1115:46:43.139280 I | etcdserver: election = 1000ms
2018- 11- 1115:46:43.139545 I | etcdserver: snapshot count =1000002018-11-1115:46:43.139839 I | etcdserver: advertise client URLs = http://localhost:23792018-11-1115:46:43.141035 I | etcdserver: restarting member 8e9e05c52164694d in cluster cdf818194e3a8c32 at commit index 462018-11-1115:46:43.141923 I | raft: 8e9e05c52164694d became follower at term 22018-11-1115:46:43.142228 I | raft: newRaft 8e9e05c52164694d [peers:[], term:2, commit:46, applied:0, lastindex:46, lastterm:2]2018-11-1115:46:43.143985 W | auth: simple token is not cryptographically signed
2018- 11- 1115:46:43.145713 I | etcdserver: starting server...[version:3.3.10, cluster version: to_be_decided]2018-11-1115:46:43.148015 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
2018- 11- 1115:46:43.149041 N | etcdserver/membership:set the initial cluster version to 3.32018-11-1115:46:43.149478 I | etcdserver/api: enabled capabilities for version 3.32018-11-1115:46:45.043137 I | raft: 8e9e05c52164694d is starting a newelection at term 22018-11-1115:46:45.043461 I | raft: 8e9e05c52164694d became candidate at term 32018-11-1115:46:45.043495 I | raft: 8e9e05c52164694d received MsgVoteResp from 8e9e05c52164694d at term 32018-11-1115:46:45.043519 I | raft: 8e9e05c52164694d became leader at term 32018-11-1115:46:45.043535 I | raft: raft.node: 8e9e05c52164694d elected leader 8e9e05c52164694d at term 32018-11-1115:46:45.044348 I | etcdserver: published {Name:default ClientURLs:[http://localhost:2379]} to cluster cdf818194e3a8c32
2018- 11- 1115:46:45.044593 E | etcdmain: forgot to set Type=notify in systemd service file?2018-11-1115:46:45.044737 I | embed: ready to serve client requests
2018- 11- 1115:46:45.045232 N | embed: serving insecure client requests on 127.0.0.1:2379,this is strongly discouraged!
From the above output, we can see a lot of information. The following are some of the more important information:
2018- 11- 1115:46:43.138055 I | etcdserver: name =default
name represents the name of the node, and the default is default.
2018- 11- 1115:46:43.138328 I | etcdserver: data dir =default.etcd
data-dir The directory where logs and snapshots are saved. The default is the current working directory default.etcd/ directory.
2018- 11- 1115:46:43.148015 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32
Communicate with other nodes in the cluster at http://localhost:2380.
2018- 11- 1115:46:43.139839 I | etcdserver: advertise client URLs = http://localhost:2379
Provide HTTP API service in http://localhost:2379 for client interaction.
2018- 11- 1115:46:43.139011 I | etcdserver: heartbeat = 100ms
The heartbeat is 100ms. The function of this parameter is how often the leader sends a heartbeat to followers. The default value is 100ms.
2018- 11- 1115:46:43.139280 I | etcdserver: election = 1000ms
Election is 1000ms. The function of this parameter is the timeout period for re-voting. If follow does not receive a heartbeat packet within this interval, re-voting will be triggered. The default is 1000ms.
2018- 11- 1115:46:43.139545 I | etcdserver: snapshot count =100000
The snapshot count is 10000. The function of this parameter is to specify how many transactions are submitted to trigger the interception of the snapshot and save it to disk.
The cluster and each node will generate a uuid.
Raft will be run at startup to elect a leader.
Etcd started in this way is just a program, if the window that starts etcd is closed, etcd will be closed
, So if you want to use it for a long time, it's best to open a service for etcd. There is no way to open the service here. If necessary, readers can Baidu by themselves.
Open another window and enter:
root@ubuntu:/opt/etcd-v3.3.10# ./etcd -versionetcd Version:3.3.10Git SHA: 27fc7e2
Go Version: go1.10.4Go OS/Arch: linux/amd64
Nine, use etcd
etcdctl client##
The etcd manufacturer provides us with a command line client—etcdctl, for users to directly deal with etcd services without the need to be based on HTTP API. It is convenient for us to test the service or manually modify the database content.
The commands supported by etcdctl are roughly divided into database operations and non-database operations.
You can use ./etcdctl -h to view the usage of etcdctl:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl -h
CRUD
Note: **etcd's database operation revolves around the management of the CRUD complete life cycle of keys and directories. **
etcd adopts a hierarchical spatial structure in the organization of keys (similar to the concept of directories in the file system). The user-specified key can be a separate name, such as: testkey, which is actually placed under the root directory/. You can specify a directory structure, such as /cluster1/node2/testkey, and the corresponding directory structure will be created.
set
Specify the value of a key
grammar:
- ttl '0'The timeout period of the key value(Unit is second), Do not configure(Default is 0)Never time out
–swap-with-value value If the current value of the key is value, set it
–swap-with-index '0'If the current index value of the key is the specified index, perform the setting operation
E.g:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl set--ttl '5' key "Hello world"Hello world
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl get keyHello world
# Wait a few seconds before executing
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl get keyError:100: Key not found(/key)[8]
The first get is an operation within 5 seconds, and the second get is an operation after 5 seconds. At this moment, the value of the key has disappeared.
update
Modify the specified key
grammar:
–ttl '0'overtime time(Unit is second), Do not configure(Default is 0)It will never time out.
For example:
# First set a value of 5 seconds
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl set--ttl '5' key "Hello world"Hello world
# Modify the value again
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl update key "Hello world2"Hello world2
# Wait 10 seconds and execute again
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl get keyHello world2
It can be found that even 10 seconds, you can get it. It shows that ttl and value are updated at the same time!
rm
Delete a key value.
grammar:
--Dir delete if the key is an empty directory or key-value pair
--Recursive delete directory and all subkeys
–with-value checks whether the existing value matches
–with-index '0' checks whether the existing index matches
For example:
# delete
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl rm keyPrevNode.Value: Hello world2
# Get again
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl rm keyError:100: Key not found(/key)[11]
mk
If the given key does not exist, create a new key value.
grammar:
–ttl '0'overtime time(The unit is seconds), do not configure(Default is 0). Never time out
For example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl mk /test/key "Hello world"Hello world
When the key exists, executing the command will report an error, for example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl mk /test/key "Hello world"Error:105: Key already exists(/test/key)[33]
mkdir
If the given key directory does not exist, a new key directory is created.
grammar:
–ttl '0'overtime time(Unit is second), Do not configure(Default is 0)It will never time out.
For example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl mkdir dir2
When the key directory exists, executing this command will report an error, for example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl mkdir dir2Error:105: Key already exists(/dir2)[13]
setdir
Create a key catalog. If the directory does not exist, create it. If the directory exists, update the directory TTL.
grammar:
–ttl '0'overtime time(Unit is second), Do not configure(Default is 0)It will never time out.
For example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl setdir dir3
If repeated execution, an error will be reported
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl setdir dir3Error:102: Not a file(/dir3)[34]
updatedir
Update an existing directory.
grammar:
–ttl '0'overtime time(Unit is second), Do not configure(Default is 0)It will never time out.
For example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl updatedir dir2
If repeated execution, no error will be reported!
rmdir
Delete an empty directory, or key-value pair
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl rmdir dir2
If repeated execution, an error will be reported
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl rmdir dir2Error:100: Key not found(/dir2)[36]
If the directory is not empty, an error will be reported, for example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl set/dir/key hihi
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl rmdir /dirError:108: Directory not empty(/dir)[37]
ls
List the keys or subdirectories under the directory (the default is the root directory), the content in the subdirectories is not displayed by default.
grammar:
--Sort sort the output results
--Recursive If there are subdirectories in the directory, output the contents recursively
- p For output as a directory, add at the end/Make a distinction
E.g:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl ls/test/dir2/dir3
If there is a value, then output, otherwise not output!
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl ls test/test/key
Non-database operations##
Non-database operations include: backup, monitoring, node management, etc.
backup
Backup etcd data.
grammar:
–data-dir etcd data directory
–backup-dir backup to the specified path
E.g:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl backup --data-dir default.etcd --backup-dir /xx/xx2018-11-1116:43:34.119969 I | failed creating backup snapshot dir /xx/xx/member/snap: expected "/xx/xx/member/snap" to be empty, got ["db"]
Prompt /xx/xx directory does not exist!
Then change to an existing directory, such as /opt/backup. Note: The bakcup directory does not need to be created, it will be created automatically!
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl backup --data-dir default.etcd --backup-dir /opt/backup2018-11-1116:44:44.845409 I | ignoring EntryConfChange raft entry2018-11-1116:44:44.845901 I | ignoring member attribute update on /0/members/8e9e05c52164694d/attributes2018-11-1116:44:44.846307 I | ignoring member attribute update on /0/members/8e9e05c52164694d/attributes
View the backup directory /opt/backup/
root@ubuntu:/opt/etcd-v3.3.10# ll /opt/backup/total 12drwx------3 root root 4096 Nov 1116:44./drwxr-xr-x 4 root root 4096 Nov 1116:44../drwx------ 4 root root 4096 Nov 11 16:44 member/
watch
Monitor the change of a key value, once the key value is updated, it will output the latest value and exit.
exec-watch
Monitor the change of a key value, once the key value is updated, execute the given command.
For watch and exec-watch, please refer to the link:
https://blog.csdn.net/mnasd/article/details/79621155
I did not make it, mainly because, after opening a new window, get key cannot get the value
Set a new value
. /etcdctl set key "Hello world"
Execution error:
Error: unknown command "set"for"etcdctl"Did you mean this?get
put
del
user
Run 'etcdctl --help'for usage.
Error: unknown command "set"for"etcdctl"Did you mean this?get
put
del
user
The original window can be executed, but the new window keeps reporting errors and various rogues...
**member ****list List etcd instance ****add add etcd instance **remove delete etcd instance
View the nodes that exist in the cluster, for example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl member list1d64cbbe0759c8f8: name=ubuntu peerURLs=http://192.168.75.129:2380 clientURLs=http://192.168.75.129:2379 isLeader=true
Delete existing nodes in the cluster, for example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl member remove 1d64cbbe0759c8f8Received an error trying to remove member 1d64cbbe0759c8f8: client: etcd cluster is unavailable or misconfigured; error #0: client: etcd member http://192.168.75.129:2379 has no leader
Prompt an error, there is no leader in the cluster
Add new nodes to the cluster, for example:
root@ubuntu:/opt/etcd-v3.3.10# ./etcdctl member add etcd3 http://192.168.75.129:2380Added member named etcd3 with ID 6c40942fac2f358f to cluster
ETCD_NAME="etcd3"ETCD_INITIAL_CLUSTER="etcd3=http://192.168.75.129:2380,default=http://localhost:2380"ETCD_INITIAL_CLUSTER_STATE="existing"
Some explanations for the above configuration parameters:
ETCD_NAME: The node name of ETCD, which should be unique in the cluster, and hostname can be used.
ETCD_DATA_DIR: ETCD data storage directory, the path where the service running data is saved, the default is${name}.etcd。
ETCD_SNAPSHOT_COUNTER: How many transaction commits will trigger a snapshot, and specify how many transactions (transactions) are committed to trigger the interception of the snapshot and save it to disk.
ETCD_HEARTBEAT_INTERVAL: The interval of heartbeat transmission between ETCD nodes, in milliseconds, how often the leader sends heartbeats to followers. The default value is 100ms.
ETCD_ELECTION_TIMEOUT: The maximum timeout period for the node to participate in the election, in milliseconds, the timeout period for re-voting. If follow does not receive a heartbeat packet within this time interval, a re-voting will be triggered. The default is 1000 ms.
ETCD_LISTEN_PEER_URLS: The list of addresses monitored by the node when communicating with other nodes. Multiple addresses are separated by commas, and the format can be divided into schemes://IP:PORT, the scheme here can be http or https. Address to communicate with peers, such as http://ip:2380, if there are more than one, use commas to separate them. All nodes need to be accessible, so don't use localhost. ETCD_LISTEN_CLIENT_URLS: The list of addresses monitored when the node communicates with the client, and the address for external services: such as http://ip:2379,http://127.0.0.1:2379, the client will connect here to interact with etcd ETCD_INITIAL_ADVERTISE_PEER_URLS: The communication address list of the member node in the entire cluster. This address is used to transmit cluster data. Therefore, this address must be able to connect to all members in the cluster. The peer listening address of this node, this value will tell other nodes in the cluster.
ETCD_INITIAL_CLUSTER: Configure the addresses of all members in the cluster, the format is: ETCD_NAME=ETCD_INITIAL_ADVERTISE_PEER_URLS, if there are multiple separated by commas, the information of all nodes in the cluster, the format is node1=http://ip1:2380,node2=http://ip2:2380,…. Note: Here node1 is the name specified by -name of the node; the following ip1:2380 is --initial-advertise-peer-The value specified by urls ETCD_ADVERTISE_CLIENT_URLS: broadcast to other members of the cluster own client address list
ETCD_INITIAL_CLUSTER_STATE: When creating a new cluster, this value is new; if there is an existing cluster, this value is existing.
ETCD_INITIAL_CLUSTER_TOKEN:Initialize the cluster token and create the cluster token. This value remains unique for each cluster. In this case, if you want to re-create the cluster, even if the configuration is the same as before, a new cluster and node uuid will be generated again; otherwise, it will cause conflicts between multiple clusters and cause unknown errors.
Note: All the configuration parameters of ETCD_MY_FLAG can also be set through command line parameters, but the parameters specified by the command line have higher priority, and when they exist, they will override the value of the environment variable.
api interface##
For etcd api interface, please refer to the link:
https://www.cnblogs.com/doscho/p/6227351.html
For the above content, this article refers to the link:
https://www.cnblogs.com/softidea/p/6517959.html
https://blog.csdn.net/mnasd/article/details/79621155
Ten, one-click installation script#
Note: This script can only be installed on the local server. Please make sure that the etcd-v3.3.10-linux-amd64.tar.gz file and the shell script are in the same directory.
The script comes with the systemctl command to start the etcd service
etcd_v3.3.10.sh
Please read the precautions at the beginning
# /bin/bash
# Click version etcd installation script
# This script,It can only be installed on the local server.
# Make sure etcd-v3.3.10-linux-amd64.tar.The gz file and the current script are in the same directory.
# Be sure to use the root user to execute this script!
# Ensure that python3 can be executed directly,Because the 4th line from the bottom,There is a json formatted output. Can be ignored if not needed
# set-e
# Enter the local ip
whiletruedo
echo 'Please enter the local ip'
echo 'Example: 192.168.0.1'
echo -e "etcd server ip=\c"
read ETCD_Server
if["$ETCD_Server"==""];then
echo 'No input etcd server IP'else
# echo 'No input etcd server IP'break
fi
done
# etcd start service
cat >/lib/systemd/system/etcd.service <<EOF
[ Unit]
Description=etcd - highly-available key value store
Documentation=https://github.com/coreos/etcd
Documentation=man:etcd
After=network.target
Wants=network-online.target
[ Service]
Environment=DAEMON_ARGS=
Environment=ETCD_NAME=%H
Environment=ETCD_DATA_DIR=/var/lib/etcd/default
EnvironmentFile=-/etc/default/%p
Type=notify
User=etcd
PermissionsStartOnly=true
# ExecStart=/bin/sh -c "GOMAXPROCS=\$(nproc) /usr/bin/etcd \$DAEMON_ARGS"
ExecStart=/usr/bin/etcd \$DAEMON_ARGS
Restart=on-abnormal
# RestartSec=10s
# LimitNOFILE=65536[Install]
WantedBy=multi-user.target
Alias=etcd3.service
EOF
# CPU name
name=`hostname`
# etcd http connection address
initial_cluster="http://$ETCD_Server:2380"
# Determine whether the process is started
A=`ps -ef|grep /usr/bin/etcd|grep -v grep|wc -l`if[ $A -ne 0];then
# Kill process
killall etcd
fi
# Delete etcd related files
rm -rf /var/lib/etcd/*
rm -rf /etc/default/etcd
# Set time zone
ln -snf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# Determine the compressed file
if [ ! -f "etcd-v3.3.10-linux-amd64.tar.gz" ];then
echo "Current directory etcd-v3.3.10-linux-amd64.tar.gz file does not exist"
exit
fi
# Install etcd
tar zxf etcd-v3.3.10-linux-amd64.tar.gz -C /tmp/
cp -f /tmp/etcd-v3.3.10-linux-amd64/etcd /usr/bin/
cp -f /tmp/etcd-v3.3.10-linux-amd64/etcdctl /usr/bin/
# etcd configuration file
cat > /etc/default/etcd <<EOF
ETCD_NAME=$name
ETCD_DATA_DIR="/var/lib/etcd/"
ETCD_LISTEN_PEER_URLS="http://$ETCD_Server:2380"
ETCD_LISTEN_CLIENT_URLS="http://$ETCD_Server:2379,http://127.0.0.1:4001"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://$ETCD_Server:2380"
ETCD_INITIAL_CLUSTER="$ETCD_Servernitial_cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster-sdn"
ETCD_ADVERTISE_CLIENT_URLS="http://$ETCD_Server:2379"
EOF
# Temporary script,Add users and groups
cat > /tmp/foruser <<EOF
#! /bin/bash
if [ \`cat /etc/group|grep etcd|wc -l\` -eq 0 ];then groupadd -g 217 etcd;fi
if [ \`cat /etc/passwd|grep etcd|wc -l\` -eq 0 ];then mkdir -p /var/lib/etcd && useradd -g 217 -u 111 etcd -d /var/lib/etcd/ -s /bin/false;fi
if [ \`cat /etc/profile|grep ETCDCTL_API|wc -l\` -eq 0 ];then bash -c "echo 'export ETCDCTL_API=3' >> /etc/profile" && bash -c "source /etc/profile";fi
EOF
# Execute script
bash /tmp/foruser
# Start service
systemctl daemon-reload
systemctl enable etcd.service
chown -R etcd:etcd /var/lib/etcd
systemctl restart etcd.service
# netstat -anpt | grep 2379
# View version
etcdctl -v
# Access API, -s Remove curl statistics. python3 -m json.tool means json format
curl $initial_cluster/version -s | python3 -m json.tool
# Delete temporary files
rm -rf /tmp/foruser /tmp/etcd-v3.3.10-linux-amd64
Execute the script and output:
Please enter the local ip
Example:192.168.0.1etcd server ip=192.168.75.129etcdctl version:3.3.10API version:2{"etcdserver":"3.3.10","etcdcluster":"3.3.0"}
If you need to clear the value of etcd, use the following command
rm -rf /var/lib/etcd/member/*
Restart etcd
service etcd restart
View all the values of etcd, where --endpoints is used to specify the etcd server address
etcdctl get/--prefix --keys-only --endpoints=192.168.0.88:2379
Recommended Posts