CentOSでHadoopを構築する
構築手順:Hadoopを初めて構築する場合は、ソフトウェア環境と構築する記事の手順に厳密に従ってください。バージョンが異なると問題が発生する可能性があります。
ソフトウェア環境:##
仮想マシン:VMware Pro14
Linux:CentOS-6.4([ダウンロードアドレス](https://link.jianshu.com/?t=http%3A%2F%2Fvault.centos.org%2F6.4%2Fisos%2Fx86_64%2F)、DVDバージョンをダウンロードするだけ)
JDK:OpenJDK1.8.0(OracleのLinuxバージョンのJDKを使用しないことを強くお勧めします)
Hadoop:2.6.5([ダウンロードリンク](https://link.jianshu.com/?t=http%3A%2F%2Fmirror.bit.edu.cn%2Fapache%2Fhadoop%2Fcommon%2F))
ここでは、仮想マシンのインストールとLinuxシステムのインストールを省略しています。インストールについては、オンラインチュートリアルを参照してください。通常、大きな問題はありません。ここで入力したユーザーパスワードを覚えておいて、下図のように使用してください。
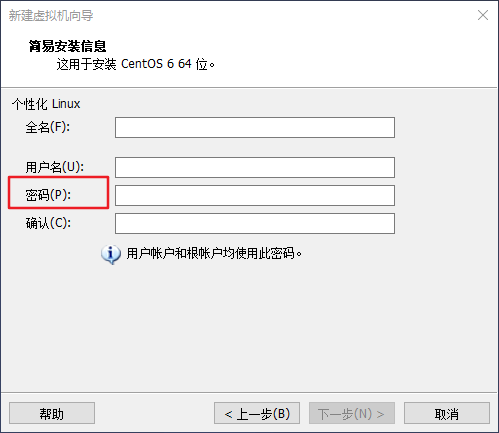
ユーザーpassword.pngを設定します
ユーザーの選択##
仮想マシンを使用してシステムをインストールすると、次の図に示すようなログインインターフェイスが表示されます。
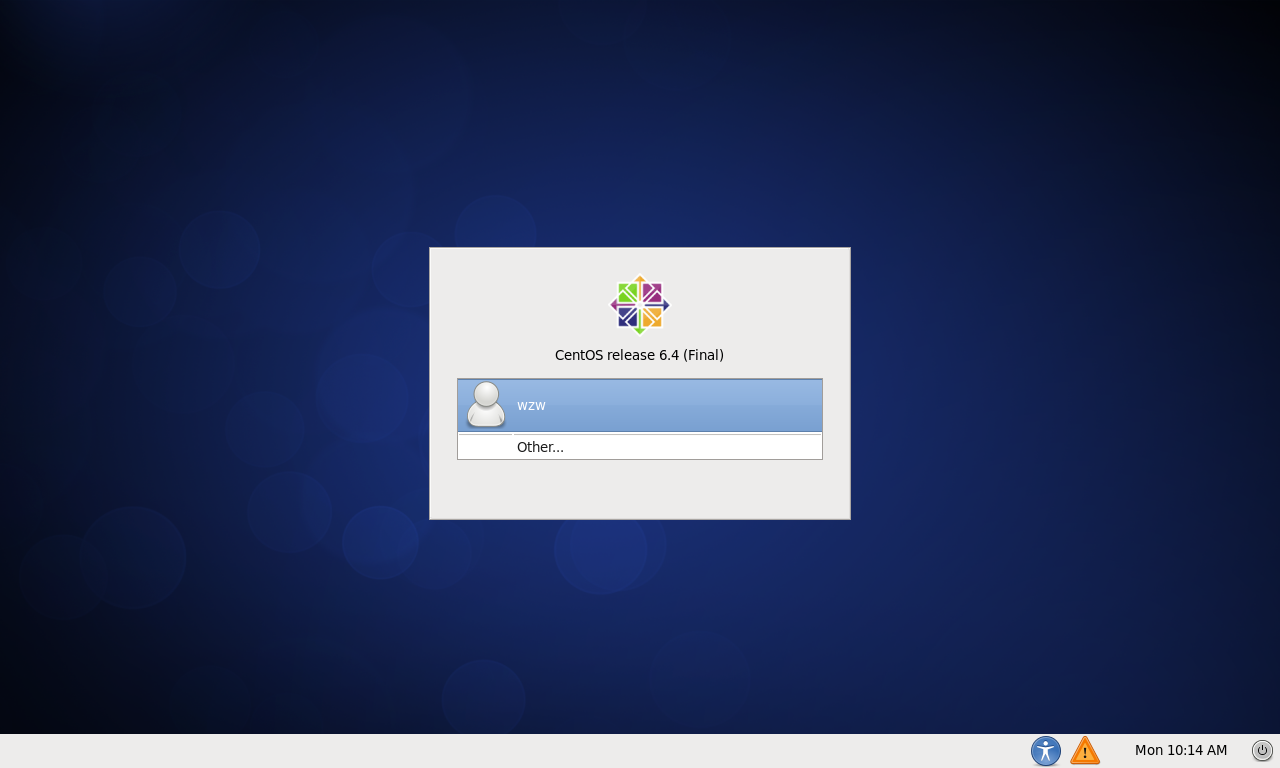
system.pngと入力します
その他を選択し、ユーザー名入力ボックスに** root **と入力し、Enterキーを押してから、パスワード入力ボックスにユーザーを作成したときにパスワードを入力します。 rootユーザーは、CentOSのインストール時に自動的に作成されるスーパーユーザーですが、パスワードは、システムのインストール時に作成される通常のユーザーパスワードと同じです。
通常、CentOSを使用する場合、rootユーザーを使用することはお勧めしません。このユーザーはシステム全体の最高の権限を持っているため、このユーザーを使用すると深刻な結果を招く可能性がありますが、Linuxに精通している場合にのみ誤用します。 Hadoopビッグデータプラットフォームを構築するには、通常のユーザーを使用します。多くのコマンドでは、rootユーザーのアクセス許可を取得するためにsudoコマンドが必要ですが、これはさらに面倒なので、rootユーザーを直接使用するだけです。
SSHをインストールします##
クラスタモードとシングルノードモードの両方でSSHログインが必要です(リモートログインと同様に、Linuxホストにログインしてコマンドを実行できます)。
まず、CentOSシステムが正常にインターネットにアクセスできることを確認します。デスクトップの右上隅にあるネットワークアイコンを確認できます。赤い十字が表示されている場合は、インターネットに接続していないことを意味します。クリックして利用可能なネットワークを選択するか、デスクトップの左上隅にあるFirefoxブラウザを使用してURLを入力できます。ネットワーク接続は正常です。それでもインターネットにアクセスできない場合は、仮想マシンの設定を確認するか、NATモードを選択するか、Baiduにアクセスして解決してください。
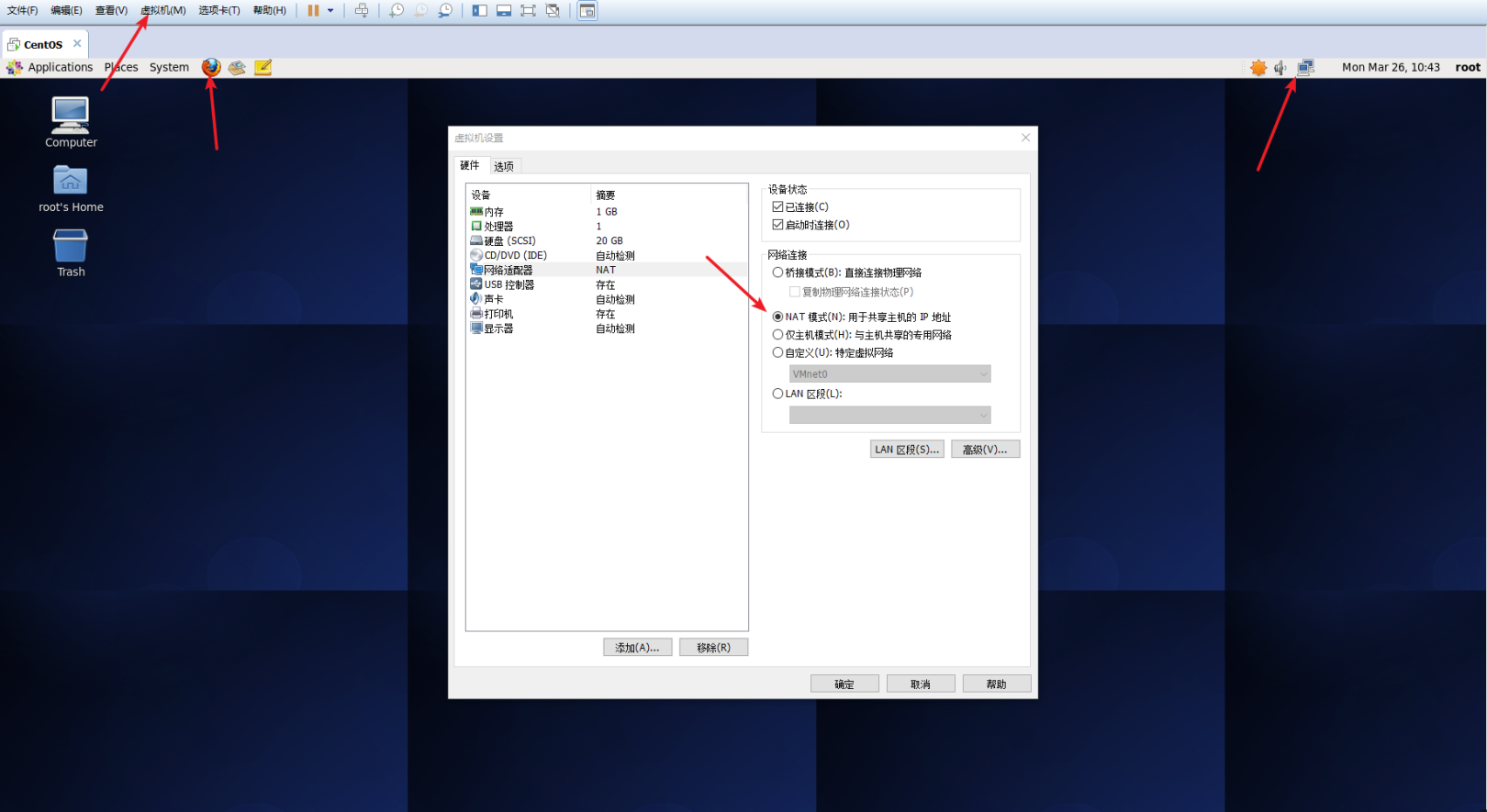
ネットワークstatus.pngを確認してください
次の図に示すように、ネットワーク接続が正常であることを確認したら、CentOSターミナルを開き、CentOSデスクトップでマウスの右ボタンをクリックして、[ターミナルで開く]を選択します。
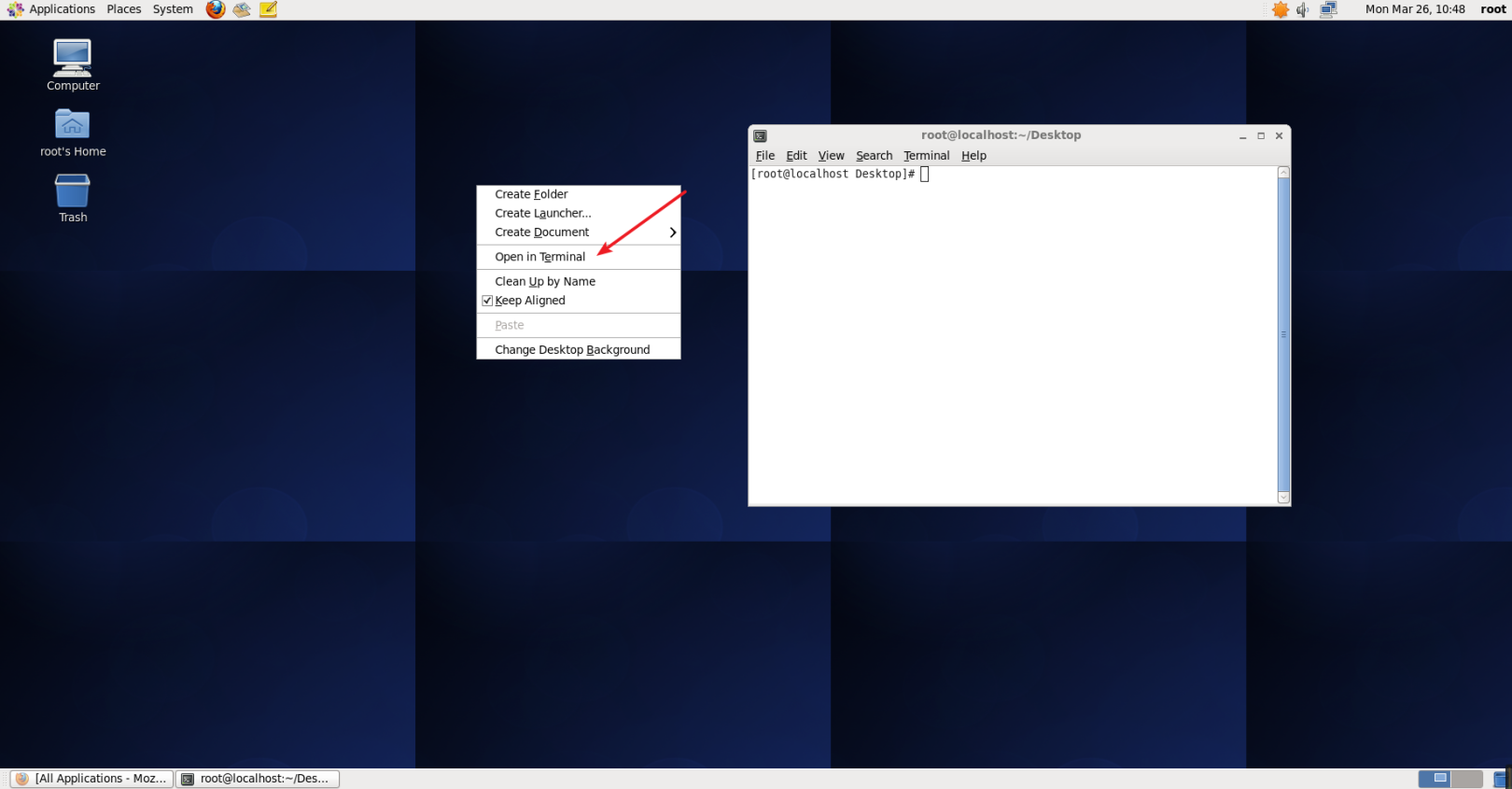
terminal.pngを開きます
通常、CentOSはデフォルトでSSHクライアントとSSHサーバーをインストールしています。ターミナルを開き、次のコマンドを実行して確認できます。
rpm -qa | grep ssh
返された結果がSSHクライアントとSSHサーバーを含めて次の図のようになっている場合は、再度インストールする必要はありません。
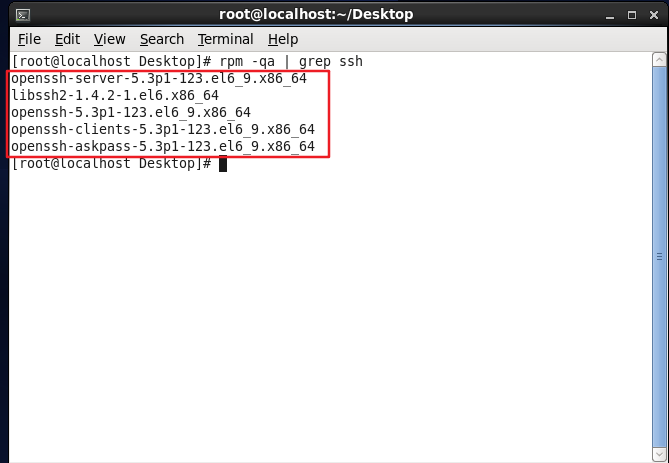
SSHがインストールされているかどうかを確認します。
インストールする必要がある場合は、yumパッケージマネージャーからインストールできます。 (インストールプロセス中に[y / N]を入力してから、yを入力するように求められます)
***注:コマンドは、2つのコマンドを直接貼り付けるのではなく、単一の順序で実行されます。 ***
ターミナルへの貼り付けは、マウスを右クリックして貼り付けを選択するか、ショートカットキー[Shift + Insert]で貼り付けることができます。
yum install openssh-clients
yum install openssh-server
SSHのインストールが完了したら、次のコマンドを実行して、SSHが使用可能かどうかをテストします(最初にSSHログインでyes / no情報が表示されたら、yesと入力し、プロンプトに従ってrootユーザーのパスワードを入力して、マシンにログインできるようにします)。 。

初めてSSH.pngにログインする
ただし、ログインするたびにパスワードを入力する必要があるため、パスワードなしでログインするようにSSHを構成する必要があります。
最初に exitと入力して、今すぐsshを終了し、元のターミナルウィンドウに戻ります。次に、ssh-keygenを使用してキーを生成し、キーを認証に追加します。
exit #sshlocalhostだけを終了します
cd ~/.ssh/ #そのようなディレクトリがない場合は、最初にsshlocalhostを実行してください
ssh-keygen -t rsa #プロンプトが表示されます。Enterキーを押すだけです。
cat id_rsa.pub >> authorized_keys #承認に参加する
chmod 600./authorized_keys #ファイルのアクセス許可を変更する
この時点で、もう一度 ssh localhostコマンドを使用すると、次の図に示すように、パスワードを入力せずに直接ログインできます。
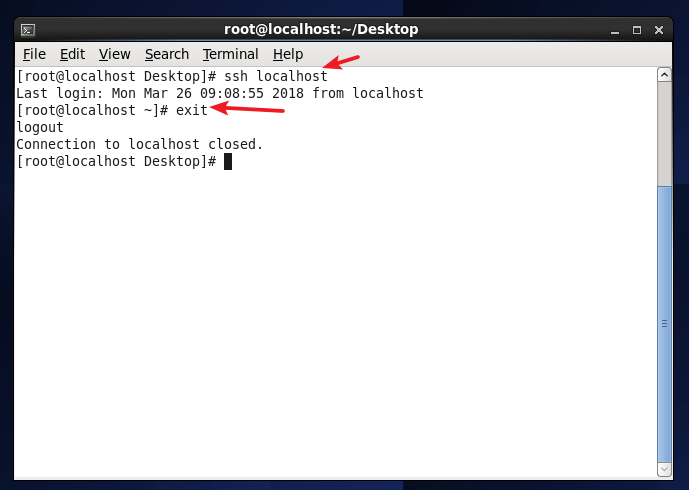
SSH.pngに再度ログインします
Java環境をインストールします##
Java環境では、OracleのJDKまたはOpenJDK(JDKのオープンソースバージョンと見なすことができます)を選択できます。現在、一般的なLinuxシステムのデフォルトインストールは基本的にOpenJDKであり、ここにインストールされるバージョンはOpenJDK1.8.0です。
一部のCentOS6.4はデフォルトでOpenJDK1.7をインストールします。ここでは、コマンドを使用して確認できます。Windowsのコマンドと同様に、環境変数JAVA_HOMEの値も確認できます。
java -version #Javaバージョンを表示
javac -version #コンパイルコマンドJavacのバージョンを表示する
echo $JAVA_HOME #見る$JAVA_この環境変数HOMEの値
システムにOpenJDKがインストールされていない場合は、yumパッケージマネージャーを使用してインストールできます。 (インストールプロセス中に、[y / N]を入力してyを入力するように求められます)
yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel #openjdk1をインストールします.8.0
上記のコマンドを使用してOpenJDKをインストールします。デフォルトのインストール場所は/usr/lib/jvm/java-1.8.0です。この場所は、以下のJAVA_HOMEを構成するときに使用されます。
次に、JAVA_HOME環境変数を構成する必要があります。便宜上、〜/ .bashrcに直接設定します。これは、Windowsのユーザー環境変数を構成するのと同じです。これは1人のユーザーに対してのみ有効です。ユーザーがログインした後、シェル端末を開くたびに、 bashrcファイルが読み取られます。
ファイルを変更するには、vimエディターを直接使用してファイルを開くか、Windowsメモ帳と同様のgeditテキストエディターを使用できます。
次のいずれかのコマンドを選択します。
vim ~/.bashrc #vimエディターでターミナルで開く.bashrcファイル
gedit ~/.bashrc #geditテキストエディタで開く.bashrcファイル
ファイルの最後に(JDKのインストール場所を指す)次の1行を追加し、保存します。
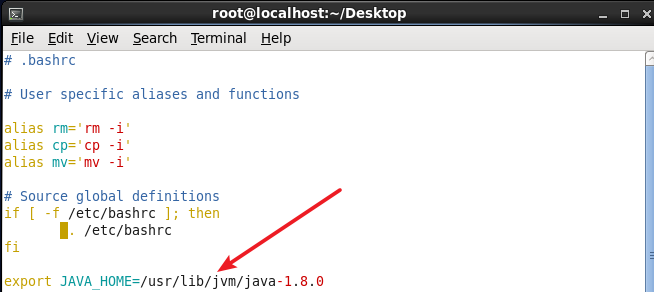
JAVA_HOME環境variable.pngを構成します
次に、環境変数を有効にして、次のコマンドを実行する必要があります。
source ~/.bashrc #変数設定を有効にする
設定後、下図のように設定が正しいか確認してみましょう。
echo $JAVA_HOME #テスト変数値
java -version
javac -version
$JAVA_HOME/bin/java -version #そして直接javaを実行します-同じバージョン
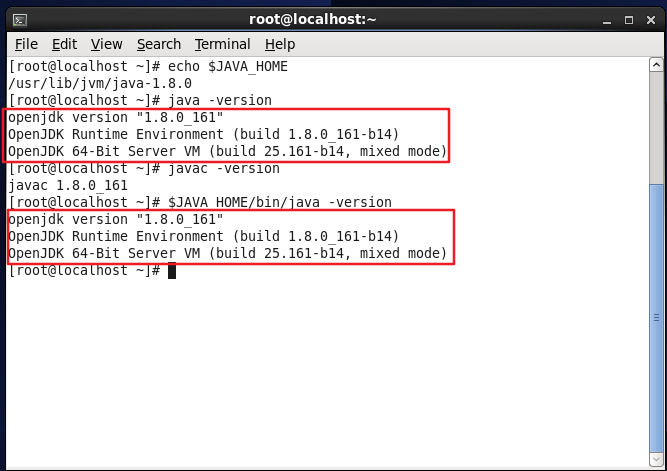
JAVA_HOME環境変数が正しく構成されているかどうかを確認してください。
このようにして、Hadoopに必要なJavaランタイム環境がインストールされます。
Hadoopをインストールします##
以前のソフトウェア環境では、hadoop 2.6.5のダウンロードアドレスが指定されていました。ダウンロードはFirefoxブラウザーから直接開くことができます。デフォルトのダウンロード場所は、次の図に示すように、ユーザーのホームのDownloadsフォルダーの下にあります。
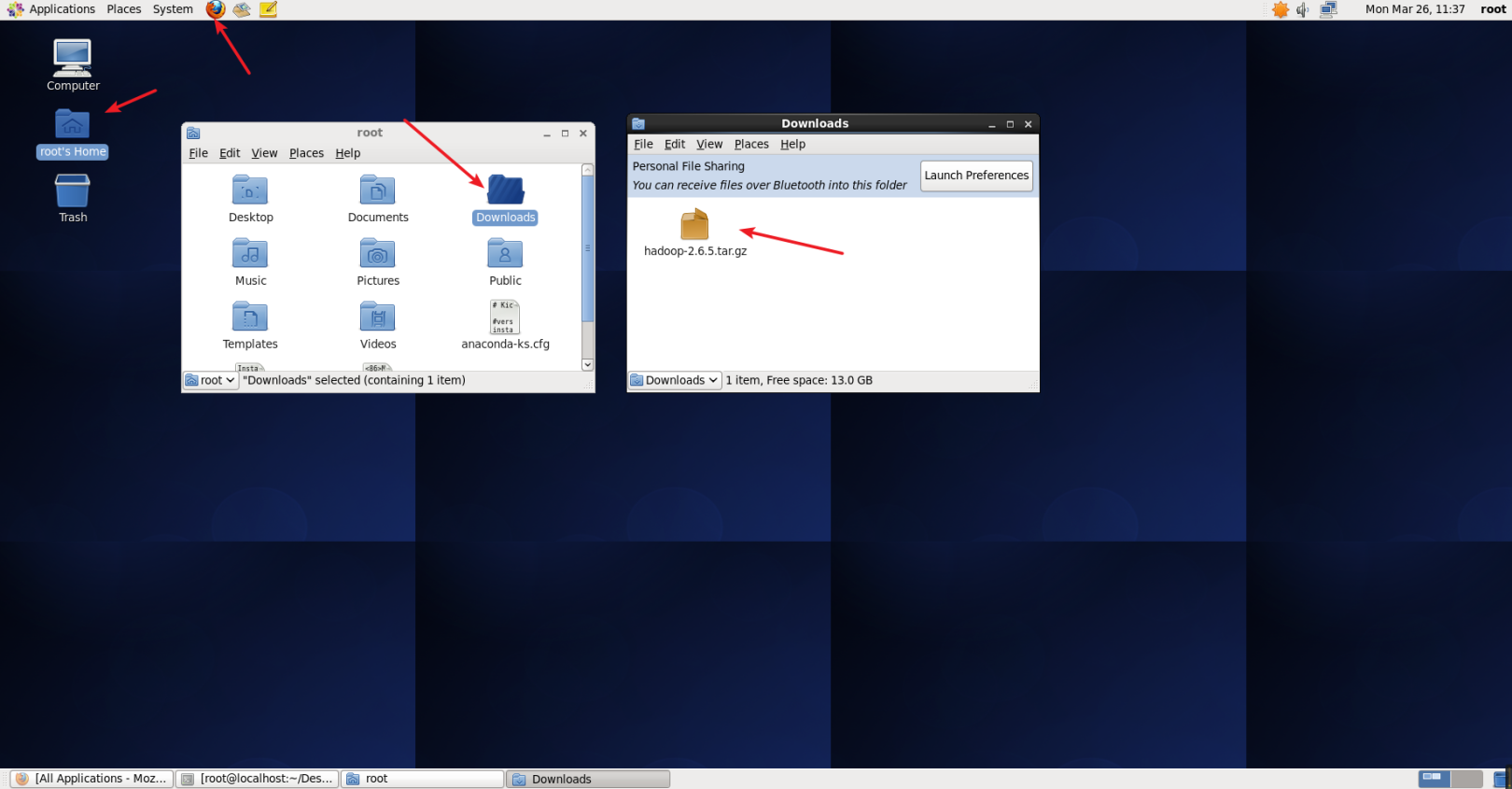
Hadoop.pngをダウンロード
ダウンロードが完了したら、Hadoopを/ usr / local /に解凍します。
tar -zxf ~/ダウンロード/hadoop-2.6.5.tar.gz -C /usr/local #に解凍/usr/ローカルディレクトリ
cd /usr/local/ #現在のディレクトリをに切り替えます/usr/ローカルディレクトリ
mv ./hadoop-2.6.5/./hadoop #フォルダ名をhadoopに変更します
chown -R root:root ./hadoop #ファイルのアクセス許可を変更します。rootは現在のユーザー名です
Hadoopは解凍後に使用できます。次のコマンドを入力して、Hadoopが使用可能かどうかを確認します。成功すると、Hadoopのバージョン情報が表示されます。
cd /usr/local/hadoop #現在のディレクトリをに切り替えます/usr/local/hadoopディレクトリ
. /bin/hadoop version #Hadoopのバージョン情報を表示する
または、 hadoopversionコマンドを直接入力して表示することもできます。
hadoop version #Hadoopのバージョン情報を表示する
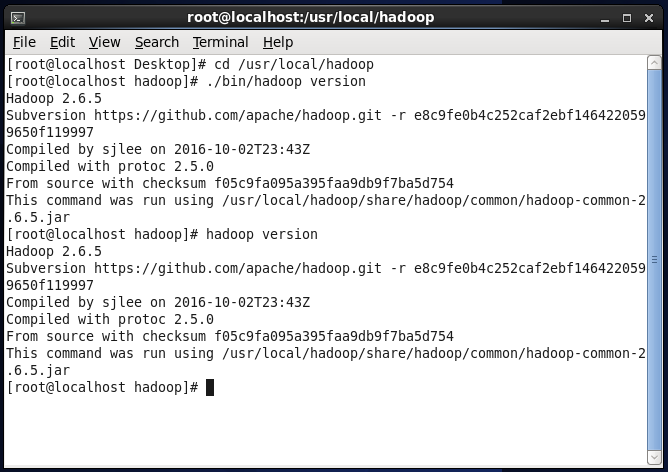
Hadoopバージョンinformation.pngを表示
**Hadoopをインストールするには、スタンドアロンモード、疑似分散モード、分散モードの3つの方法があります。 ****
- スタンドアロンモード:Hadoopのデフォルトモードは非分散モード(ローカルモード)であり、他の構成なしで実行できます。デバッグに便利な非分散または単一のJavaプロセス。
- 疑似分散モード:Hadoopは、単一ノード上で疑似分散方式で実行できます。Hadoopプロセスは個別のJavaプロセスとして実行されます。ノードは、NameNodeとDataNodeの両方として機能します。同時に、HDFS内のファイルを読み取ります。
- 分散モード:複数のノードを使用してクラスター環境を形成し、複数のホストまたは仮想ホストを必要とするHadoopを実行します。
Hadoop疑似分散構成##
これで、Hadoopを使用していくつかの例を実行できます。Hadoopには多くの例があります。 hadoopjar。/ share / hadoop / mapreduce / hadoop-mapreduce-examples-2.6.5.jarを実行して、すべての例を表示できます。
ここでクエリの例を実行してみましょう。入力フォルダを入力フォルダとして使用し、正規表現 dfs [az。] +に一致する単語をフィルタリングし、回数をカウントして、フィルタ結果を出力フォルダに出力します。
cd /usr/local/hadoop #現在のディレクトリをに切り替えます/usr/local/hadoopディレクトリ
mkdir ./input #現在のディレクトリに入力フォルダを作成します
cp ./etc/hadoop/*.xml ./input #hadoopの構成ファイルを新しく作成した入力フォルダーinputにコピーします
. /bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* #出力を表示
コマンド cat。/ output / *で結果を表示すると、規則性に準拠したdfsadminという単語が1回表示されます。
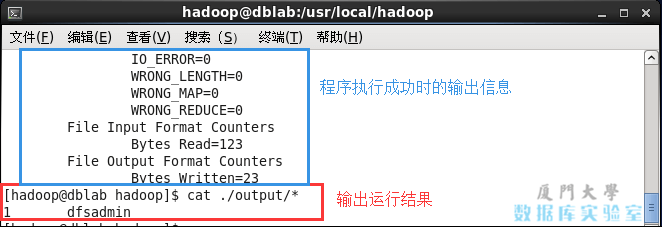
テストHadoopexample.pngを実行します
操作中にエラーが発生した場合、以下のようなプロンプトが表示されます。
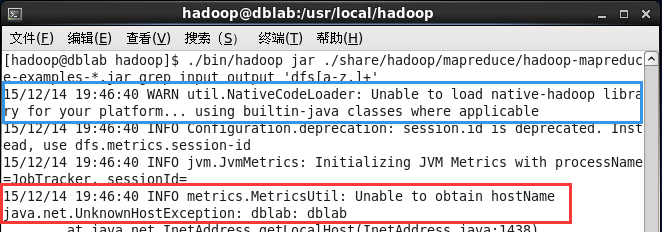
Hadoopexample.pngの実行中にエラーが発生しました
「WARNutil.NativeCodeLoader:プラットフォームのnative-hadoopライブラリをロードできません...該当する場合は組み込みのjavaクラスを使用してください」というプロンプトが表示された場合、WARNプロンプトは無視でき、Hadoopの通常の操作には影響しません。
***注:Hadoopはデフォルトでは結果ファイルを上書きしないため、上記の例を再度実行するとエラーが発生します。最初に出力フォルダーを削除する必要があります。 ***
rm -rf ./output #に/usr/local/hadoopディレクトリの下で実行します
Hadoopのインストールをテストするのに問題はありません。Hadoopの環境変数の設定を開始できます。これも〜/ .bashrcファイルで構成されています。
gedit ~/.bashrc #geditテキストエディタで開く.bashrcファイル
.bashrcファイルの最後に次のコンテンツを追加します。HADOOP_HOMEの場所が正しいことに注意してください。前の構成に従うと、この部分をコピーできます。
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
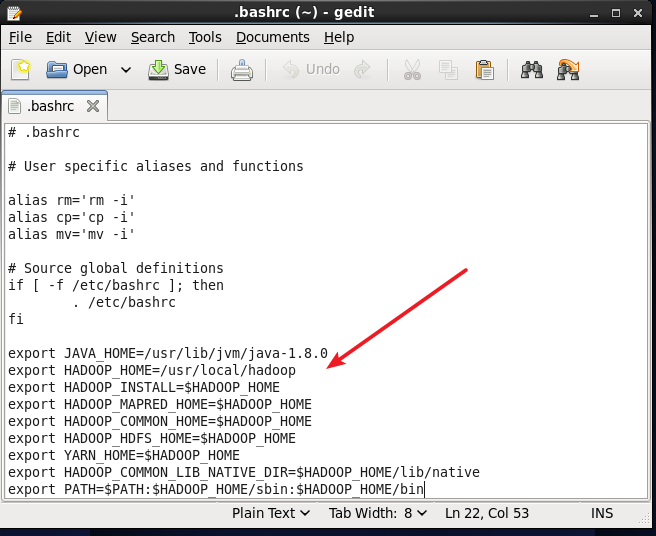
Hadoop環境variables.pngの構成
保存後にgeditプログラムを閉じることを忘れないでください。そうしないと、端末が占有され、次のコマンドを実行できなくなります。[Ctrl + C]を押してプログラムを終了できます。
保存後、設定を有効にするために次のコマンドを実行することを忘れないでください。
source ~/.bashrc
Hadoopの構成ファイルは/ usr / local / hadoop / etc / hadoop /の下にあります。疑似配布の場合、2つの構成ファイル** core-site.xml と hdfs-site.xml **を変更する必要があります。 Hadoop構成ファイルはxml形式であり、各構成はプロパティの名前と値を宣言することによって実装されます。
構成ファイル** core-site.xml **を変更します(geditを使用して編集する方が便利で、コマンド gedit。/ etc / hadoop / core-site.xmlを入力します)。
で <configuration></configuration> 真ん中に次のコードを挿入します。
< configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
同様に、構成ファイル** hdfs-site.xml **、 gedit。/ etc / hadoop / hdfs-site.xmlを変更します
< configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>
構成が完了したら、NameNodeをフォーマットします。 (このコマンドは、Hadoopの最初の起動に必要です)
hdfs namenode -format
成功すると、「正常にフォーマットされました」と「ステータス0で終了します」というプロンプトが表示されます。「ステータス1で終了します」の場合は、エラーを意味します。
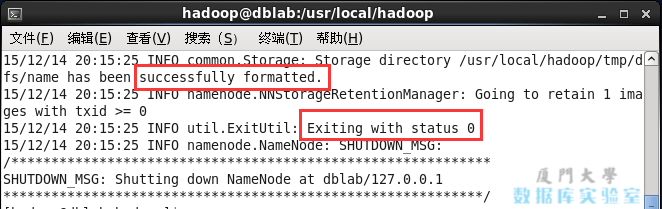
NameNode format.png
次に、Hadoopを起動します。
start-dfs.sh #NameNodeプロセスとDataNodeプロセスを開始します
次のSSHプロンプト「接続を続行してもよろしいですか」が表示された場合は、「はい」と入力します。
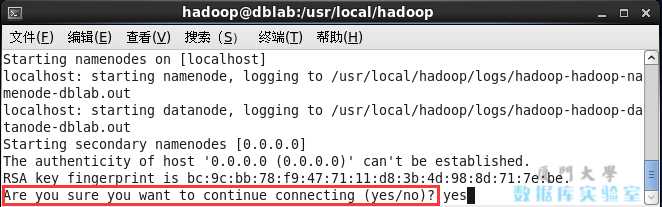
Hadoopを起動するための注意事項。
起動が完了したら、コマンド jpsを使用して、起動が成功したかどうかを判断できます。NameNode、DataNode、SecondaryNameNode、およびJpsの次の4つのプロセスが表示された場合、Hadoopの起動は成功しています。
jps #プロセスを表示して、Hadoopが正常に開始されたかどうかを確認します
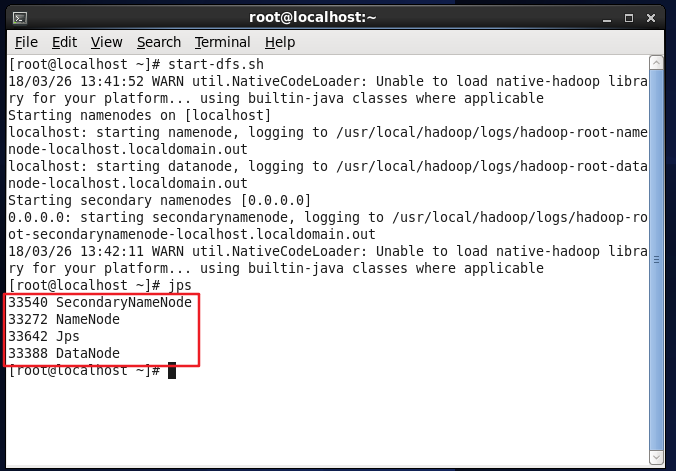
Hadoopが正常に開始されたかどうかを確認します。
正常に起動した後、Webインターフェイス[http:// localhost:50070](https://link.jianshu.com/?t=http%3A%2F%2Flocalhost%3A50070%2F)にアクセスしてNameNodeおよびDatanode情報を表示したり、HDFSのファイルをオンラインで表示したりすることもできます。
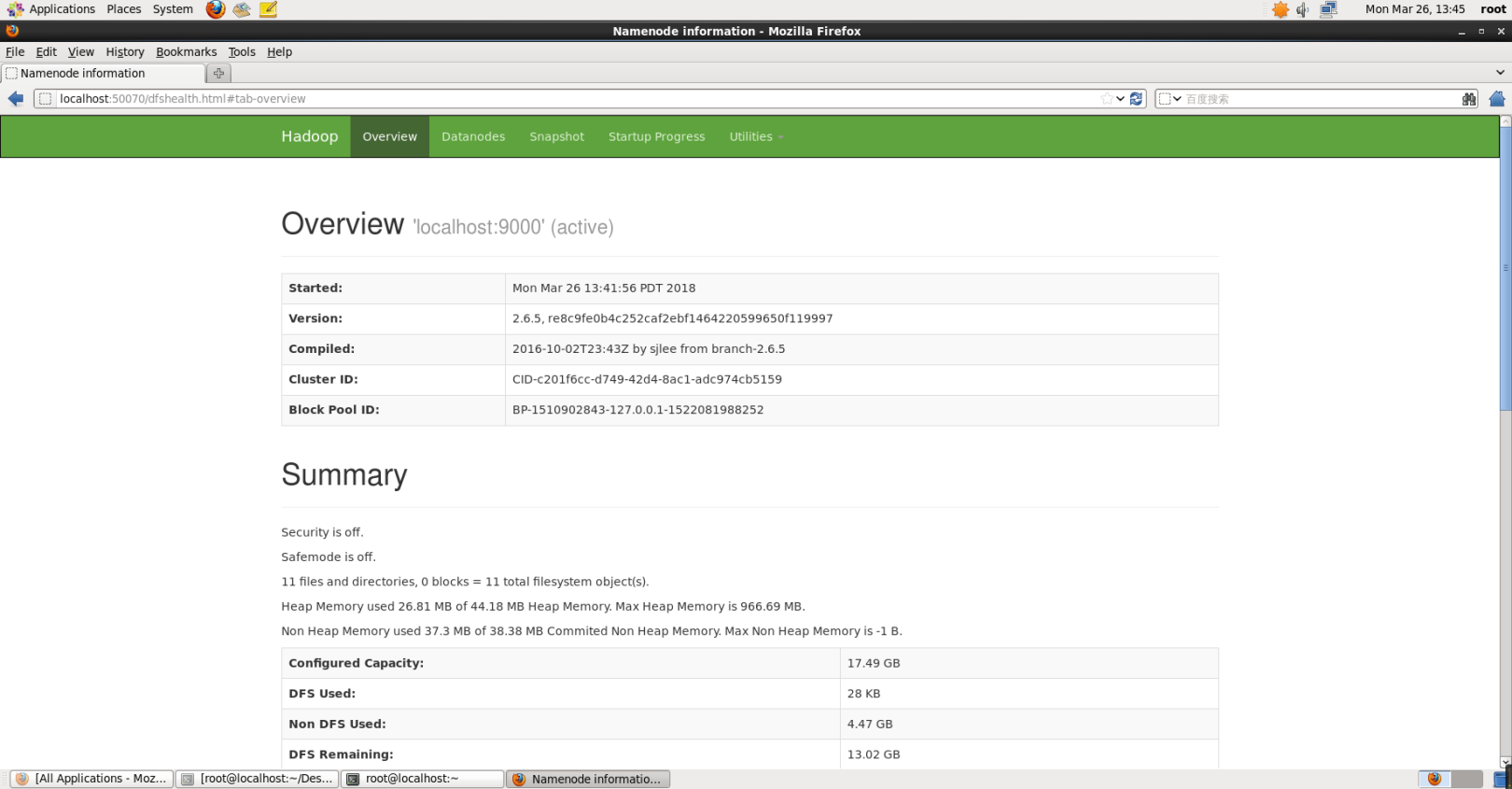
Hadoopは通常Webインターフェイスを開始します。png
YARNを開始します##
YARNはMapReduceから分離されており、リソース管理とタスクスケジューリングを担当します。 YARNはMapReduceで実行され、高い可用性と高いスケーラビリティを提供します。 (疑似配布もYARNを開始できません。通常、プログラムの実行には影響しません)
上記の start-dfs.shコマンドを使用してHadoopを起動すると、MapReduce環境のみが起動します。YARNを起動して、YARNにリソース管理とタスクスケジューリングを任せることができます。
最初に構成ファイル** mapred-site.xml **を変更し、mapred-site.xml.templateファイルの名前をmapred-site.xmlに変更する必要があります。
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml #ファイルの名前変更
gedit ./etc/hadoop/mapred-site.xml #geditテキストエディタで開く
< configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
次に、構成ファイル** yarn-site.xml **を変更します。
gedit ./etc/hadoop/yarn-site.xml #geditテキストエディタで開く
< configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
次に、YARNを起動し、 start-yarn.shコマンドを実行します。
注:YARNを開始する前に、dfs Hadoopが開始されていること、つまり start-dfs.shが実行されていることを確認してください。
start-yarn.sh #YARNを開始します
mr-jobhistory-daemon.sh start historyserver #履歴サーバーがWeb上でタスクの実行ステータスを表示できるようにします
jpsで開いた後、次の図に示すように、NodeManagerとResourceManagerの2つのプロセスがあることがわかります。
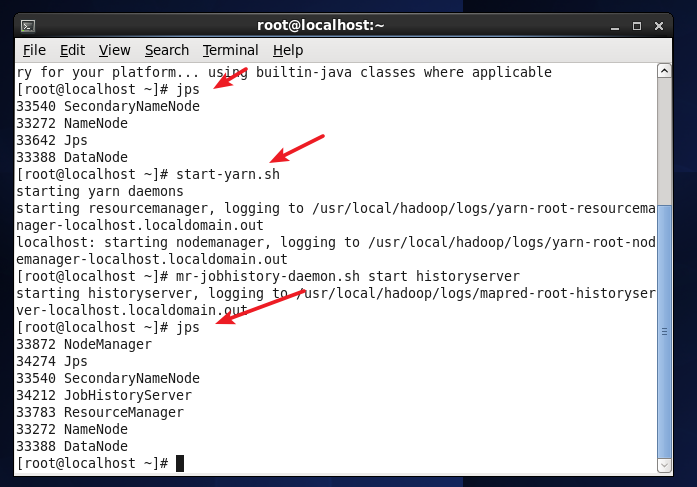
YARN.pngを開始
YARNを起動した後も、リソース管理方法とタスクスケジューリングが異なることを除いて、インスタンスの実行方法は同じです。 YARNを開始する利点は、次の図に示すように、Webインターフェイス[http:// localhost:8088 / cluster](https://link.jianshu.com/?t=http%3A%2F%2Flocalhost%3A8088%2Fcluster)を介してタスクの実行ステータスを表示できることです。
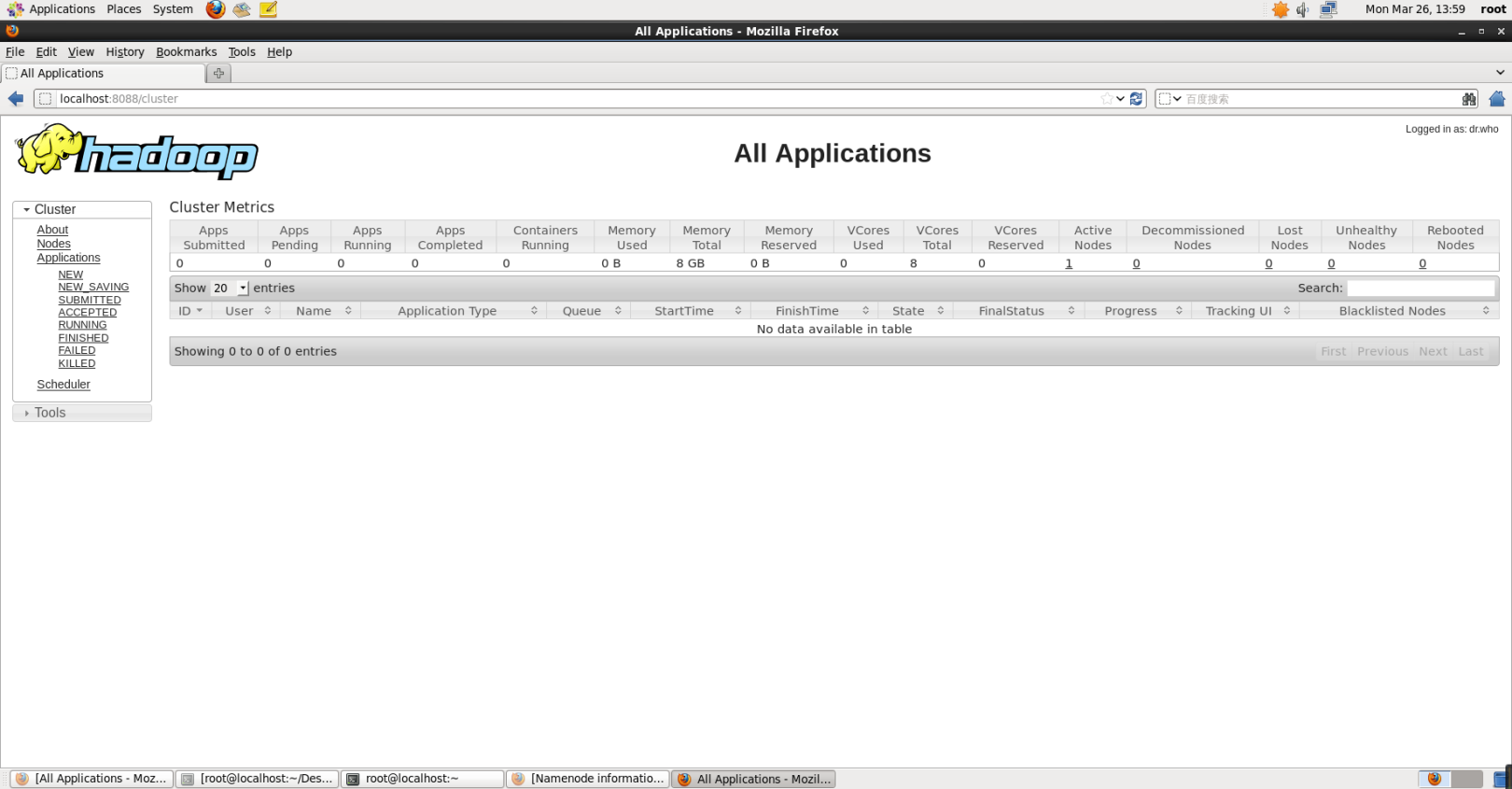
YARN web interface.png
YARNは主に、クラスターのリソース管理とタスクスケジューリングを改善することを目的としています。YARNを開始しない場合は、構成ファイル** mapred-site.xml **の名前をmapred-site.xml.templateに変更し、使用する必要があるときに元に戻す必要があります。それでおしまい。それ以外の場合、構成ファイルが存在し、YARNがオンになっていないと、実行中のプログラムは「サーバーへの接続の再試行:0.0.0.0/0.0.0.0:8032」エラーを要求します。これが、構成ファイルの初期ファイル名がマップされる理由です。 site.xml.template。
YARNをオフにするコマンドは次のとおりです。オンは開始、オフは停止です。
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
通常の学習では、疑似配布を使用するだけで十分です。
参考記事:
- [ Hadoopインストールチュートリアル疑似分散構成 CentOS6.4 / Hadoop2.6.0](https://link.jianshu.com/?t=http%3A%2F%2Fdblab.xmu.edu.cn%2Fblog%2Finstall-hadoop -in-centos%2F)
- [ ビッグデータ処理アーキテクチャHadoop学習ガイド](https://link.jianshu.com/?t=https%3A%2F%2Fdblab.xmu.edu.cn%2Fblog%2F285%2F)
- [ CentOS7はyumコマンドを使用してJavaSDK(openjdk)をインストールします](https://link.jianshu.com/?t=https%3A%2F%2Fblog.csdn.net%2Fyouzhouliu%2Farticle%2Fdetails%2F51183115)
Recommended Posts