Python image recognition OCR
Article Directory###
-
Python image recognition OCR
-
#1 demand
-
#2 surroundings
-
#3 installation
-
#3.1 macOS
-
#3.2 Linux(CentOS)
-
#4 use
-
#4.1 python install pytesseract library
-
#4.2 Python code
-
#5 Online case
Python image recognition OCR
#1 demand##
- Identify the information in the picture, such as a QR code
#2 surroundings##
macOS / Linux
Python3.7.6
#3 installation##
#3.1 macOS
- Install tesseract
//Only install tesseract, do not install training tools
brew install tesseract
//Install the training tool while installing tesseract
brew install --with-training-tools tesseract
//When installing tesseract, install all languages at the same time. The language pack is relatively large. If it takes a long time to install, it is recommended not to install it. Choose according to your needs
brew install --all-languages tesseract
//Install tesseract, and install training tools and languages
brew install --all-languages --with-training-tools tesseract
- Download language pack
Address: https://github.com/tesseract-ocr/tessdata
I installed the Chinese language pack here
Chinese language pack: https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
Then copy the downloaded Chinese language pack to the following path:
/usr/local/Cellar/tesseract/4.0.0_1/share/tessdata
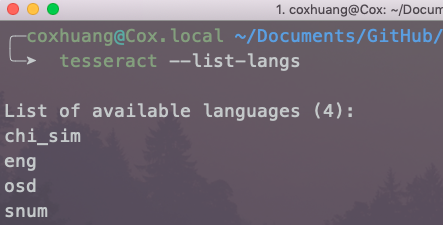
- View local language pack
tesseract --list-langs
#3.2 Linux(CentOS)
- Installation dependencies
yum install autoconf automake libtool libjpeg-devel libpng-devel libtiff-devel zlib-devel
- Install leptonica
Download: wget https://github.com/tesseract-ocr/tesseract/archive/4.1.0.tar.gz
Unzip and install
tar -xzvf leptonica-1.74.4.tar.gz
cd leptonica-1.74.4.tar.gz
. /configure --profix=/usr/local/leptonica
make
sudo make install
- Install tesseract-ocr
wget https://github.com/tesseract-ocr/tesseract/archive/3.04.zip
unzip 3.04.zip
cd tesseract-3.04/./configure
make && make install
sudo ldconfig
I installed the Chinese language pack here
Chinese language pack: https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
Then copy the downloaded Chinese language pack to the following path:
/usr/local/share/tessdata
#4 use##
#4.1 python install pytesseract library###
pip install pytesseract
pip install Pillow
#4.2 Python code###
from PIL import Image
import pytesseract
# Specify the image path and recognized language
data = pytesseract.image_to_string(Image.open('/Users/Documents/1.png'), lang='chi_sim')print(data)
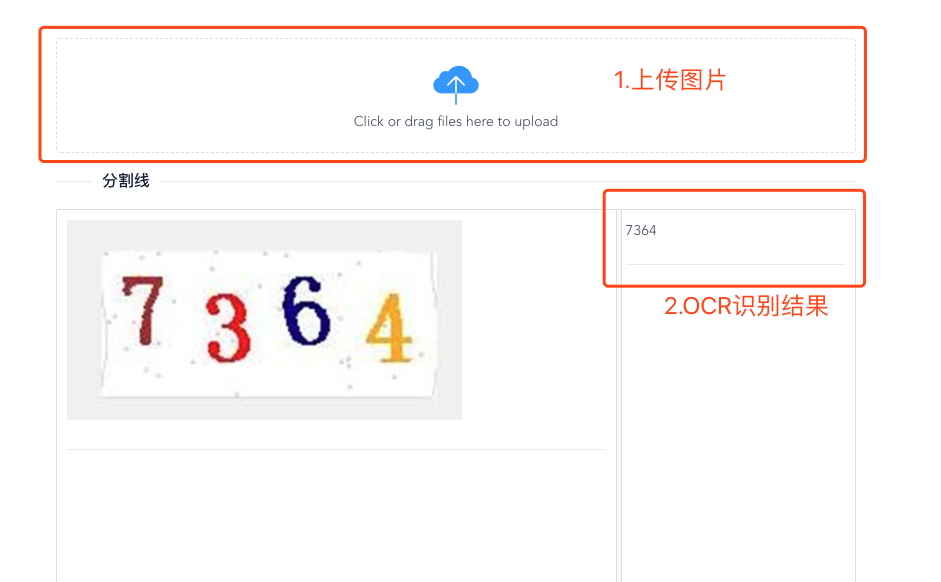
#5 Online case##
address:
Recommended Posts