Detailed explanation of Python web page parser usage examples
python web parser
- Common python web page parsing tools include: re regular matching, python's own html.parser module, third-party library BeautifulSoup (emphasis on learning) and lxm library.
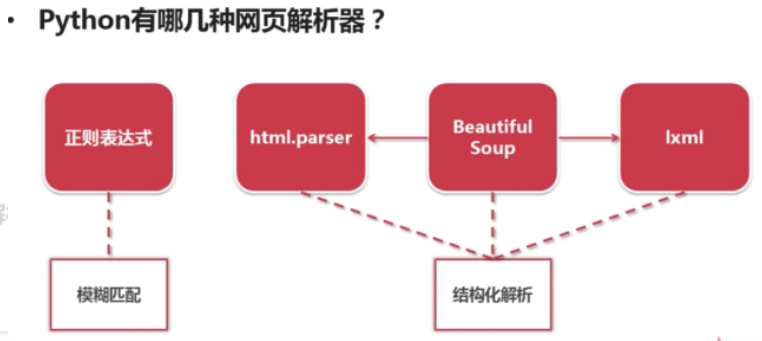
- Classification of common web page parsers
(1) Fuzzy matching: re regular expression is a string-like fuzzy matching mode;
(2) Structural analysis: BeatufiulSoup, html.parser and lxml, they all use the DOM tree structure as the standard to extract the label structure information.
- DOM tree explanation: namely Document Object Model, its tree label structure, please see the figure below.
The so-called structured analysis means that the web page parser treats the entire downloaded HTML document as a Doucment object, and then uses the label form of its upper and lower structure to traverse the upper and lower labels of this object and extract information.
# Introduce related packages, urllib and bs4, which are the most commonly used libraries for obtaining and parsing web pages
from urllib.request import urlopen
from bs4 import BeautifulSoup
# Open link
html=urlopen("https://www.datalearner.com/website_navi")
# Obtain the web page object through urlopen, put it into BeautifulSoup, the html document of the target web page stored by bsObj
bsObj=BeautifulSoup(html.read())print(bsObj)
soup = BeautifulSoup(open(url,’r’,encoding = ‘utf-8’))
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36','referer':"www.mmjpg.com"}
all_url ='http://www.mmjpg.com/'
#' User-Agent':Request method
#' referer':From which link
start_html = requests.get(all_url, headers=headers)
# all_url: the starting address, which is the first page visited
# headers: request headers, tell the server who is coming.
# requests.get: One method can get all_url the page content and return the content.
Soup =BeautifulSoup(start_html.text,'lxml')
# BeautifulSoup: Parse the page
# lxml: parser
# start_html.text: the content of the page
The above is the whole content of this article, I hope it will be helpful to everyone's study.
Recommended Posts