Detailed analysis of Python garbage collection mechanism
Introduce
Why is there a garbage collection mechanism
The garbage collection mechanism in Python is abbreviated as (GC). We will generate a large number of variables to save data during the running of the program, and sometimes some variables are no longer used and need to be cleaned up to release the memory space occupied by the variables. In some relatively low-level languages (such as: C language, assembly language), the release of memory space needs to be performed manually by programmers. This kind of operation directly dealing with the underlying hardware is very dangerous and cumbersome, and based on C In order to solve this concern, Python, which was developed by the language, has its own garbage collection mechanism, so that developers can devote themselves to development without worrying too much about memory usage.
name ="yunya" #yunya is going to change her name
name ="yunyaya" #Originally, the name yunya is no longer used. Now it must be cleaned up or it will occupy memory space. Fortunately, Python’s garbage collection mechanism will help me clean it up."yunya"
The concept of heap area and stack area
If you read the article I wrote before about the underlying principles of Python variables, then you must have a certain understanding of the heap area and stack area memory. If you haven't read it then it doesn't matter, the link is as follows:
Python variables and basic data types
The underlying working principle
Reference count
To put it plainly, reference counting is to count the variable names of the stack area bound to the variable values of the heap area. As shown:
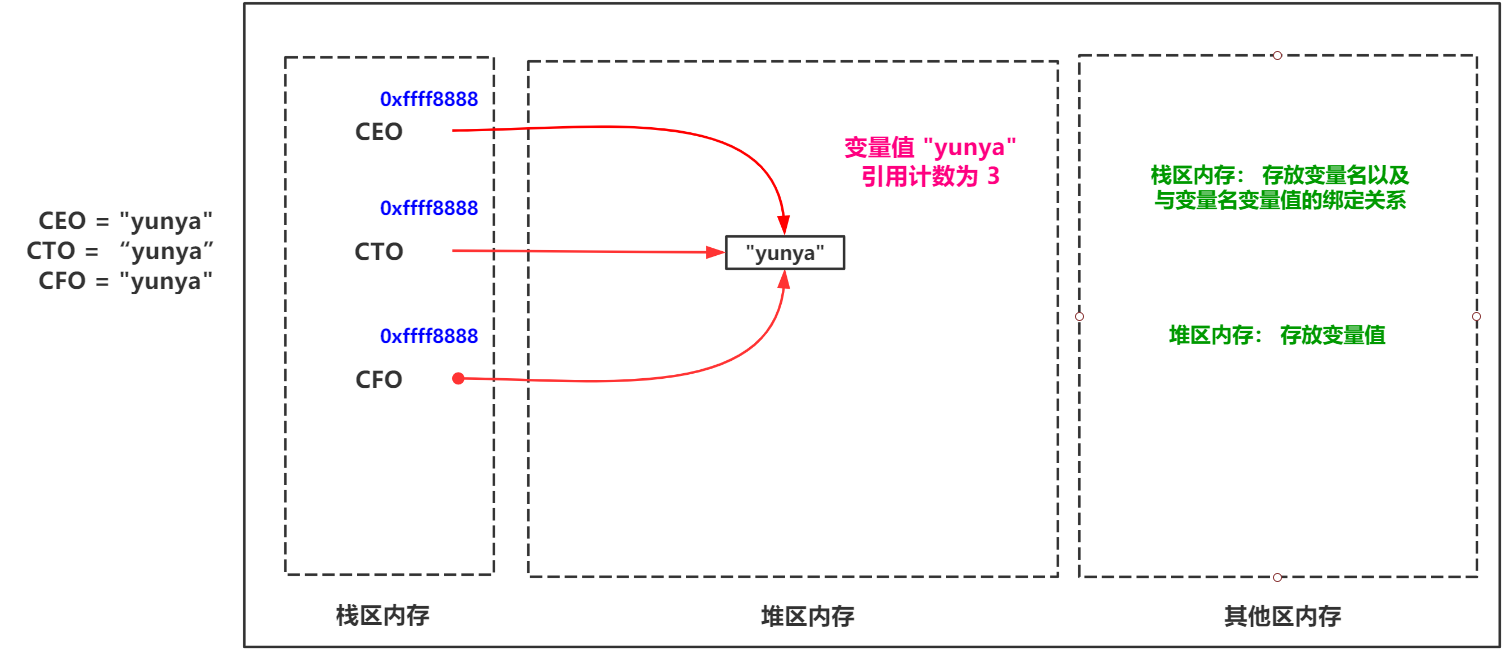
When using del or reassigning a variable name, the reference count of the variable value will be -1. When the reference count is 0, the next time the Python memory recycling mechanism performs a memory scan, the variable value will be recycled as garbage.
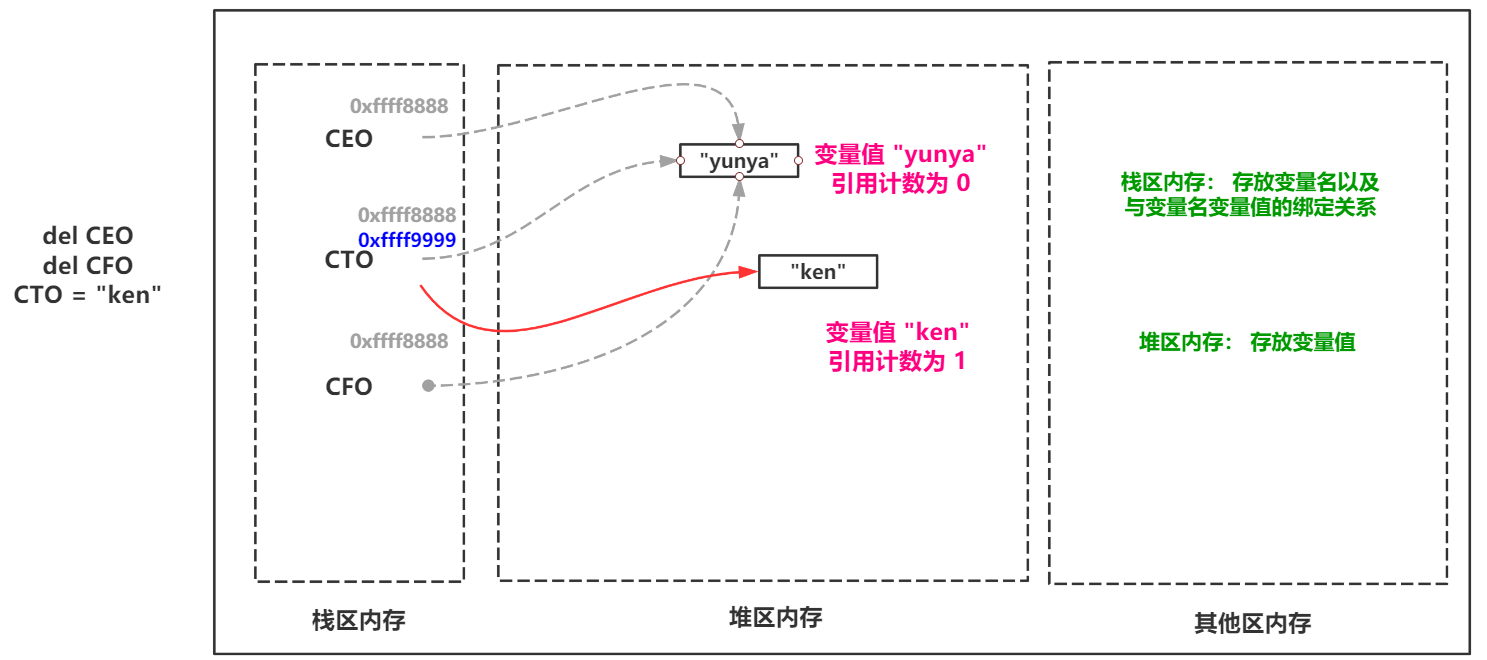
So here is the most basic and most commonly used reference counting introduction in Python's memory recovery mechanism.
Circular reference-memory leak
Although reference counting is one of the most frequently used mechanisms in Python's memory recovery mechanism, it also has certain disadvantages. Let's look at the following code:
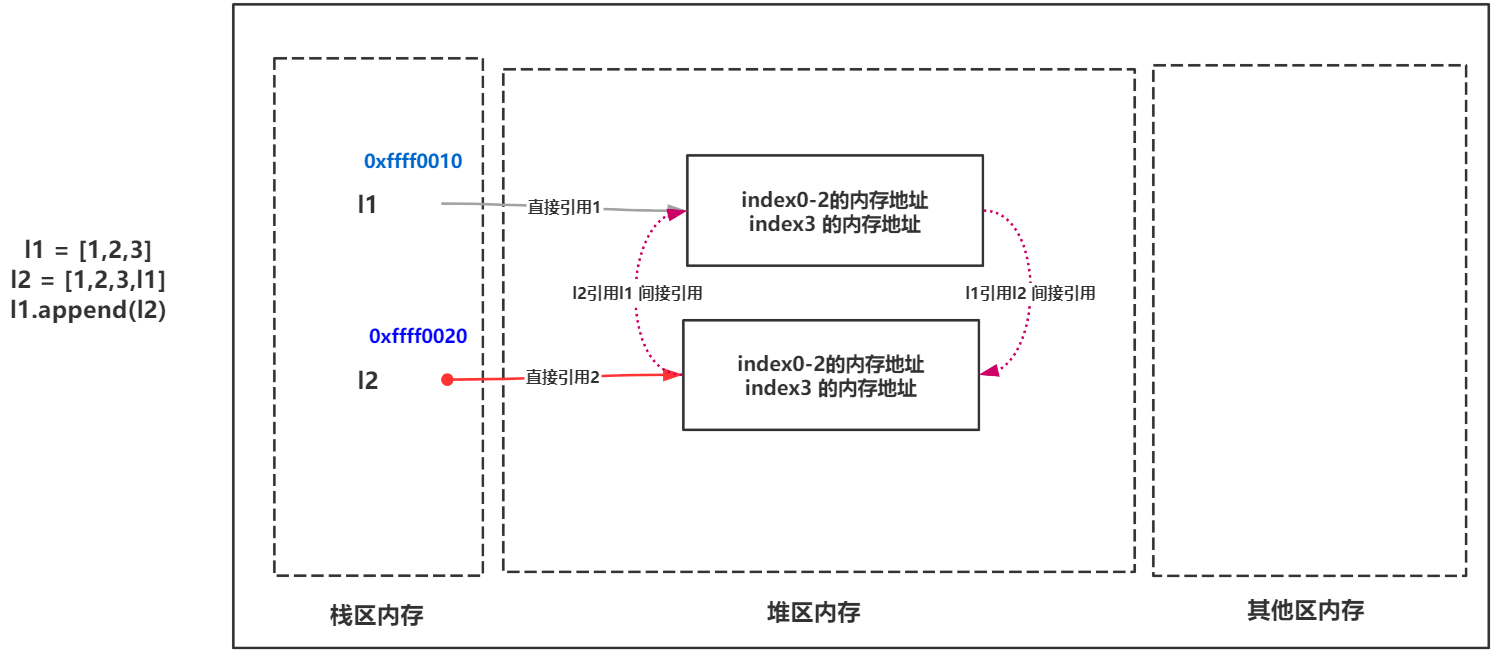
l1 =[1,2,3]
l2 =[1,2,3,l1]
l1.append(l2) #append()Method is used to add an element value to the list
l1
[1,2,3,[1,2,3,[...]]]
l2
[1,2,3,[1,2,3,[...]]]
Now l1 and l2 are all referred to each other. So for this kind of reference is called circular reference (also known as cross reference), circular reference will bring a problem:
- The reference count of the l1 variable value is currently 2
- l2 The reference count of the variable value is currently 2
- What about when del l1 and del l2 are used?
- Their reference variables are all reduced by 1, but the variable names of the reference method are all deleted from each other. It stands to reason that these variable values are all garbage variables. It is impossible to clean up these garbage variables based on the reference count alone.
del l1
del l2
# How to access li1 or li2 now? Can't access, but their variable value still exists in memory, and the reference count changes from 2 to 1.
Mark-clear
Mark clearing means that when the application's available memory space is about to be exhausted, it will start to scan the stack area, and will mark the variable value in the heap area along the variable name of the stack area. If there is no stack area in the heap area The data corresponding to the variable name will be considered garbage data and will be cleaned up by the Python garbage collection mechanism.

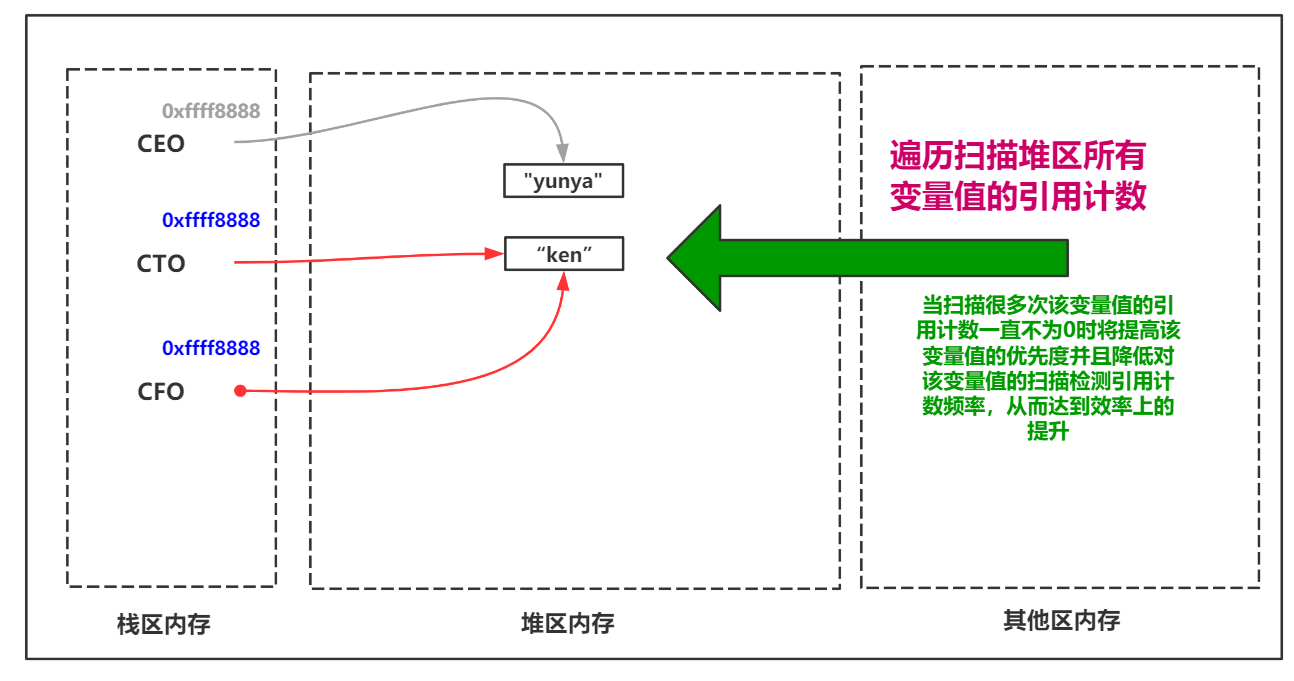
Efficiency problem solution-generational collection
The reference count-based garbage collection mechanism will traverse the reference count of the variable value of the entire heap area before performing a cleanup operation. This is very time consuming, so the Python garbage collection mechanism adds a generational collection strategy to improve efficiency.
references
https://www.zalou.cn/article/161474.htm
The above is the detailed analysis of the Python garbage collection mechanism. For more information about the Python garbage collection mechanism, please pay attention to other related articles on ZaLou.Cn!
Recommended Posts