Detailed explanation of Python IO port multiplexing
**What is IO multiplexing? **
One of my SocketServer has 500 links connected. I want 500 links to be concurrent. Each link needs to operate IO, but the IO under single thread is serial. I realized multiple channels, which looks like Is the effect of concurrency, this is multiplexing!
**Concept description: **
Before explaining, we must first explain a few concepts:
– User space and kernel space
Now operating systems use virtual memory, so for 32-bit operating systems, its addressing space (virtual storage space) is 4G (2 to the 32th power). The core of the operating system is the kernel, which is independent of ordinary applications and can access the protected memory space as well as all permissions to access the underlying hardware devices. In order to ensure that user processes cannot directly manipulate the kernel and ensure the security of the kernel, the worry system divides the virtual space into two parts, one part is the kernel space and the other is the user space. For the Linux operating system, the highest 1G byte (from virtual address 0xC0000000 to 0xFFFFFFFF) is used by the kernel, called kernel space, and the lower 3G byte (from virtual address 0x00000000 to 0xBFFFFFFF) is used for each Process usage is called user space.
– Process switching (same as thread switching)
– Process blocking
The process being executed, because some expected events have not occurred, such as requesting system resources failure, waiting for the completion of a certain operation, new data has not arrived or no new work, etc., the blocking primitive (Block) is automatically executed by the system, Turn yourself from the running state to the blocking state. It can be seen that the blocking of the process is an active behavior of the process itself, and therefore only the process in the running state (obtaining the CPU) can turn it into the blocking state. When the process enters the blocking state, it does not occupy CPU resources.
– File descriptor
File descriptor is a term in computer science, an abstract concept used to express references to files.
The file descriptor is a non-negative integer in form. In fact, it is an index value that points to the record table of files opened by the process maintained by the kernel for each process. When the program opens an existing file or creates a new file, the kernel returns a file descriptor to the process. In programming, some programming involving the bottom layer is often developed around file descriptors. However, the concept of file descriptors is often only applicable to operating systems such as UNIX and Linux.
– Cache I/O
Cached I/O is also called standard I/O, and most file system default I/O operations are cached I/O. In the cache I/O mechanism of Linux, the operating system will cache the I/O data in the page cache of the file system, that is, the data will be copied to the buffer of the operating system kernel first. Then it will be copied from the buffer of the operating system kernel to the address space of the application.
Disadvantages of cached I/O:
In the process of data transmission, multiple data copy operations are required in the application address space and the kernel. The CPU and memory overhead caused by these data copy operations is very large.
IO mode
As mentioned earlier, for an IO access (take read as an example), the data will first be copied to the operating system kernel buffer, and then from the operating system kernel buffer to the address space of the application. So, when a read operation occurs, it will go through two stages:
-
Waiting for the data to be ready
-
Copying the data from the kernel to the process
Formally because of these two stages, the Linux system has produced the following five network mode solutions.
-Blocking I/O (blocking IO)
-Non-blocking I/O (nonblocking IO)
– I/O multiplexing (IO multiplexing)
– Signal driven I/O (signal driven IO)
– Asynchronous I/O (asynchronous IO)
Note: Since signal driven IO is not commonly used in practice, I only mention the remaining four IO models.
1、 Blocking I/O (blocking IO)
In Linux, all sockets are blocking by default. A typical read operation flow is roughly like this:
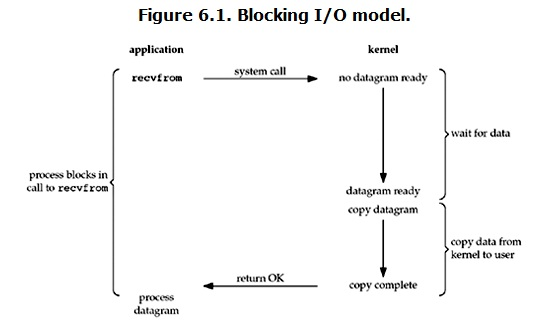
When the user process calls the recvfrom system call, the kernel starts the first stage of IO: preparing data (for network IO, many times the data has not arrived at the beginning. For example, it has not received a complete UDP Package. At this time, the kernel has to wait for enough data to arrive). This process requires waiting, which means that it takes a process for data to be copied into the buffer of the operating system kernel. On the user process side, the entire process will be blocked (of course, it is the blocking of the process's own choice). When the kernel waits until the data is ready, it copies the data from the kernel to the user memory, and then the kernel returns the result, and the user process releases the block state and restarts.
Therefore, the characteristic of blocking IO is that it is blocked in both stages of IO execution.
2、 Non-blocking I/O (nonblocking IO)
Under linux, you can make it non-blocking by setting the socket. When performing a read operation on a non-blocking socket, the process looks like this:
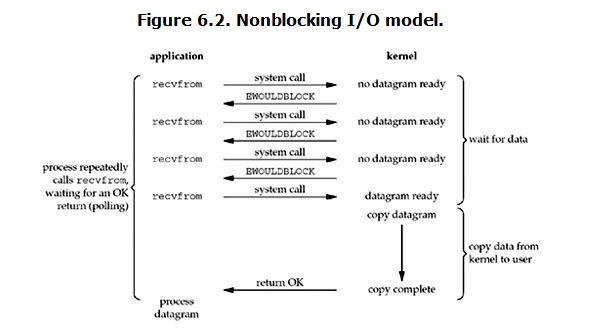
When the user process issues a read operation, if the data in the kernel is not ready, it will not block the user process, but immediately returns an error. From the perspective of the user process, after it initiates a read operation, it does not need to wait, but gets a result immediately. When the user process judges that the result is an error, it knows that the data is not ready, so it can send the read operation again. Once the data in the kernel is ready, and it receives the system call from the user process again, it immediately copies the data to the user memory and returns.
Therefore, the characteristic of nonblocking IO is that the user process needs to actively ask whether the kernel data is good.
3、 I/O multiplexing (IO multiplexing)
IO multiplexing is what we call select, poll, and epoll. In some places, this IO method is also called event driven IO. The advantage of select/epoll is that a single process can handle multiple network-connected IO at the same time. Its basic principle is that the function of select, poll, and epoll will continuously poll all sockets in charge, and when a socket has data arrived, it will notify the user process.
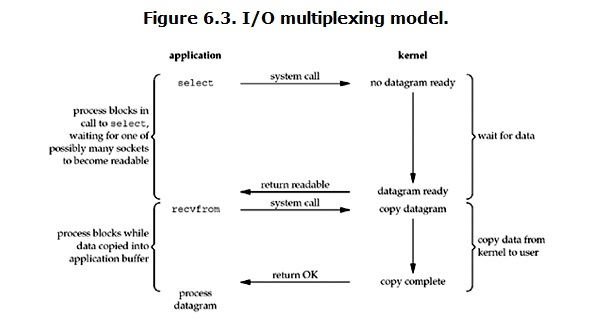
**When the user process calls select, the entire process will be blocked. At the same time, the kernel will "monitor" all the sockets responsible for select. When the data in any socket is ready, select will return. At this time, the user process calls the read operation again to copy the data from the kernel to the user process.
Therefore, the characteristic of I/O multiplexing is that through a mechanism, a process can wait for multiple file descriptors at the same time, and any one of these file descriptors (socket descriptors) enters the read-ready state, select( ) Function can return.
This picture is not very different from the blocking IO picture, in fact, it is even worse. Because two system calls (select and recvfrom) are needed here, and blocking IO only calls one system call (recvfrom). However, the advantage of using select is that it can handle multiple connections at the same time.
Therefore, if the number of connections processed is not very high, the web server using select/epoll may not have better performance than the web server using multi-threading + blocking IO, and the delay may be even greater. The advantage of select/epoll is not that it can handle a single connection faster, but that it can handle more connections. )
In the IO multiplexing Model, in practice, each socket is generally set to non-blocking, but, as shown in the figure above, the entire user process is actually blocked all the time. It's just that the process is selected by the function block instead of being given to the block by socket IO.
4、 Asynchronous I/O (asynchronous IO)
Asynchronous IO under Linux is rarely practical. First look at its process:
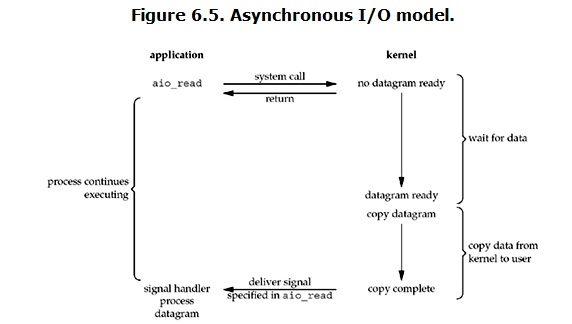
After the user process initiates the read operation, it can start to do other things immediately. On the other hand, from the perspective of the kernel, when it receives an asynchronous read, it will first return immediately, so it will not generate any block to the user process. Then, the kernel will wait for the completion of the data preparation, and then copy the data to the user memory. When all this is completed, the kernel will send a signal to the user process to tell it that the read operation is complete.
to sum up
1、 The difference between blocking and non-blocking:
Calling blocking IO will block the corresponding process until the operation is completed, and non-blocking IO will return immediately when the kernel is still preparing data.
2、 The difference between synchronous IO and asynchronous IO:
Before explaining the difference between synchronous IO and asynchronous IO, we need to give the definition of both. The definition of POSIX looks like this:
– A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
– An asynchronous I/O operation does not cause the requesting process to be blocked;
The difference between the two is that synchronous IO will block the process when doing "IO operation". According to this definition, the aforementioned blocking IO, non-blocking IO, and IO multiplexing all belong to synchronous IO.
Some people will say that non-blocking IO is not blocked. There is a very "cunning" place here. The "IO operation" in the definition refers to the real IO operation, which is the system call of recvfrom in the example. When non-blocking IO executes the recvfrom system call, if the kernel data is not ready, the process will not be blocked at this time. However, when the data in the kernel is ready, recvfrom will copy the data from the kernel to the user memory. At this time, the process is blocked. During this time, the process is blocked.
The asynchronous IO is different. When the process initiates an IO operation, it returns directly and ignores it again until the kernel sends a signal to tell the process that the IO is complete. During this whole process, the process was not blocked at all.
The comparison of each IO Model is shown in the figure:

Through the above picture, you can find that the difference between non-blocking IO and asynchronous IO is still very obvious. In non-blocking IO, although the process will not be blocked most of the time, it still requires the process to actively check, and when the data preparation is completed, the process also needs to call recvfrom again to copy the data to the user memory. . Asynchronous IO is completely different. It is like the user process handing over the entire IO operation to someone else (kernel) to complete, and then the other person will send a signal when finished. During this period, the user process does not need to check the status of the IO operation, nor does it need to actively copy data.
The above is the detailed content of Python IO port multiplexing. For more information about Python IO port multiplexing, please pay attention to other related articles on ZaLou.Cn!
Recommended Posts