Pythonは検証コード認識を実装します
一般的な紹介
pythonクローラーが特定のWebサイトの検証コードをクロールすると、検証コードの識別の問題が発生する可能性があります。現在、ほとんどの検証コードは4つのカテゴリに分類されています。
1.検証コードを計算します
2.スライダー検証コード
3.画像検証コード
4.音声確認コード
このブログは主に、簡単な検証コードを認識する画像認識検証コードを記述しています。認識率を高め、認識をより正確にするには、独自のフォントライブラリをトレーニングするのに多大な労力を要します。
識別確認コードは通常、次の手順です。
1.グレースケール処理
2.二値化
3.境界線を削除します(ある場合)
4.ノイズリダクション
5.文字をカットまたは傾き補正
6.トレーニングフォントライブラリ
7.識別
この6つのステップの最初の3つのステップは基本です。実際の状況に応じて4または5を選択できますが、必ずしも検証コードが削減されるわけではありません。認識率は大幅に増加し、場合によっては減少します。
このブログにはトレーニングフォントライブラリの内容は含まれていませんので、ご自身で検索してください。また、基本的な文法についても説明していません。
使用されるいくつかの主要なpythonライブラリ:Pillow(python画像処理ライブラリ)、OpenCV(高度な画像処理ライブラリ)、pytesseract(認識ライブラリ)
グレースケール処理と2値化
グレースケール処理は、色確認コード画像を灰色画像に変換することです。
二値化とは、画像を白黒のみの画像に処理することであり、これはその後の画像処理と認識に役立ちます。
OpenCVには、グレースケール処理と2値化のための既製の方法があります。処理後の効果:
コード:
# 適応しきい値の2値化
def _get_dynamic_binary_image(filedir, img_name):
filename ='./out_img/'+ img_name.split('.')[0]+'-binary.jpg'
img_name = filedir +'/'+ img_name
print('.....'+ img_name)
im = cv2.imread(img_name)
im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) #グレー値
# 二値化
th1 = cv2.adaptiveThreshold(im,255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY,21,1)
cv2.imwrite(filename,th1)return th1
境界線を削除
確認コードに境界線がある場合は、境界線を削除する必要があります。境界線を削除するには、ピクセルをトラバースし、4つの境界線上のすべてのポイントを見つけて、それらを白に変更します。ここでの境界線の幅は2ピクセルです。
注:OpenCVを使用すると、画像のマトリックスポイントが逆になります。つまり、長さと幅が逆になります。
コード:
# 境界線を削除します
def clear_border(img,img_name):
filename ='./out_img/'+ img_name.split('.')[0]+'-clearBorder.jpg'
h, w = img.shape[:2]for y inrange(0, w):for x inrange(0, h):if y <2 or y w -2:
img[x, y]=255if x <2 or x h -2:
img[x, y]=255
cv2.imwrite(filename,img)return img
ノイズ減少
ノイズリダクションは検証コード処理の重要なステップです。ここではポイントノイズリダクションとラインノイズリダクションを使用しました。

ラインノイズリダクションの考え方は、このポイントに隣接する4つのポイント(図でマークされている緑色のポイント)を検出し、これらの4つのポイントの中で白いポイントの数を決定することです.2つ以上の白いピクセルがある場合は、それが考慮されますこの点は白で干渉線全体を除去できますが、この方法は限られています。干渉線が太すぎると除去できず、細い干渉線のみを除去します
コード:
# 干渉線ノイズの低減
def interference_line(img, img_name):
filename ='./out_img/'+ img_name.split('.')[0]+'-interferenceline.jpg'
h, w = img.shape[:2]
# ! ! ! opencvマトリックスポイントは逆です
# img[1,2]1:写真の高さ、2:写真の幅
for y inrange(1, w -1):for x inrange(1, h -1):
count =0if img[x, y -1]245:
count = count +1if img[x, y +1]245:
count = count +1if img[x -1, y]245:
count = count +1if img[x +1, y]245:
count = count +1if count 2:
img[x, y]=255
cv2.imwrite(filename,img)return img
ポイントノイズリダクションの考え方はラインノイズリダクションの考え方と似ていますが、異なる位置で検出されたポイントが異なり、コメントは非常に明確です。
コード:
# ポイントノイズリダクション
def interference_point(img,img_name, x =0, y =0):"""
9 近所の箱,現在のポイントを中心としたフィールドボックス,黒い点の数
: param x::param y::return:"""
filename ='./out_img/'+ img_name.split('.')[0]+'-interferencePoint.jpg'
# todo画像の長さと幅の下限を決定します
cur_pixel = img[x,y]#現在のピクセル値
height,width = img.shape[:2]for y inrange(0, width -1):for x inrange(0, height -1):if y ==0: #最初の行
if x ==0: #左上の頂点,4近所
# 中心点の隣に3点
sum =int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=2*245:
img[x, y]=0
elif x == height -1: #右上の頂点
sum =int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y +1])if sum <=2*245:
img[x, y]=0else: #トップ非頂点,6近所
sum =int(img[x -1, y]) \
+ int(img[x -1, y +1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=3*245:
img[x, y]=0
elif y == width -1: #結論
if x ==0: #左下の頂点
# 中心点の隣に3点
sum =int(cur_pixel) \
+ int(img[x +1, y]) \
+ int(img[x +1, y -1]) \
+ int(img[x, y -1])if sum <=2*245:
img[x, y]=0
elif x == height -1: #右下の頂点
sum =int(cur_pixel) \
+ int(img[x, y -1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y -1])if sum <=2*245:
img[x, y]=0else: #下部の非頂点,6近所
sum =int(cur_pixel) \
+ int(img[x -1, y]) \
+ int(img[x +1, y]) \
+ int(img[x, y -1]) \
+ int(img[x -1, y -1]) \
+ int(img[x +1, y -1])if sum <=3*245:
img[x, y]=0else: #yは境界上にありません
if x ==0: #左側の非頂点
sum =int(img[x, y -1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y -1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=3*245:
img[x, y]=0
elif x == height -1: #右側の非頂点
sum =int(img[x, y -1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x -1, y -1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y +1])if sum <=3*245:
img[x, y]=0else: #9つの分野で認定
sum =int(img[x -1, y -1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y +1]) \
+ int(img[x, y -1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y -1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=4*245:
img[x, y]=0
cv2.imwrite(filename,img)return img
効果:

実際、この段階でこれらの文字を認識できるようになり、文字をカットする必要がなくなり、この3種類の検証コードの認識率は50%以上になりました。
キャラクターカット
文字カットは通常、確認コードで接着された文字に使用されます。接着された文字は認識しにくいため、認識のために接着された文字を個々の文字にカットする必要があります。
キャラクターカットのアイデアは、黒い点を見つけてから、接続されているすべての黒い点がトラバースされるまでそれに隣接する黒い点をトラバースし、これらのポイントの中で最高点、最低点、最低点を見つけることです。右端と左端のポイントを記録し、これをキャラクターだと思って、黒いポイントが見つかるまで後方にトラバースし、上記の手順を続けます。最後に、各キャラクターの4つのポイントを切り取ります
図の赤い点は、コードの実行後に識別された各文字の4つの点であり、これらの4つの点に従って切り取られます(図にはいくつかのエラーがありますが、理解してください)
ただし、m2が接着されており、コードが文字と見なしているため、各文字の幅を確認する必要があります。幅が広すぎる場合は、2つの文字が接着されていると見なされます。そしてそれを真ん中で切る
各文字の4つのドットコードを決定します。
def cfs(im,x_fd,y_fd):'''過剰なcfsアクセスの問題を解決するために、純粋な再帰ではなく、キューとコレクションを使用してトラバースされたピクセル座標を記録します
'''
# print('**********')
xaxis=[]
yaxis=[]
visited =set()
q =Queue()
q.put((x_fd, y_fd))
visited.add((x_fd, y_fd))
offsets=[(1,0),(0,1),(-1,0),(0,-1)]#4つの近所
while not q.empty():
x,y=q.get()for xoffset,yoffset in offsets:
x_neighbor,y_neighbor = x+xoffset,y+yoffset
if(x_neighbor,y_neighbor)in(visited):continue #すでに訪問しました
visited.add((x_neighbor, y_neighbor))try:if im[x_neighbor, y_neighbor]==0:
xaxis.append(x_neighbor)
yaxis.append(y_neighbor)
q.put((x_neighbor,y_neighbor))
except IndexError:
pass
# print(xaxis)if(len(xaxis)==0|len(yaxis)==0):
xmax = x_fd +1
xmin = x_fd
ymax = y_fd +1
ymin = y_fd
else:
xmax =max(xaxis)
xmin =min(xaxis)
ymax =max(yaxis)
ymin =min(yaxis)
# ymin,ymax=sort(yaxis)return ymax,ymin,xmax,xmin
def detectFgPix(im,xmax):'''検索ブロックの開始
'''
h,w = im.shape[:2]for y_fd inrange(xmax+1,w):for x_fd inrange(h):if im[x_fd,y_fd]==0:return x_fd,y_fd
def CFS(im):'''キャラクターの位置を切る
'''
zoneL=[]#各ブロック長のリストL
zoneWB=[]#各ブロックのX軸[始まりと終わり]リスト
zoneHB=[]#各ブロックのY軸[始まりと終わり]リスト
xmax=0#前のブロックの終わりにある黒い点の横軸,これが初期化です
for i inrange(10):try:
x_fd,y_fd =detectFgPix(im,xmax)
# print(y_fd,x_fd)
xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd)
L = xmax - xmin
H = ymax - ymin
zoneL.append(L)
zoneWB.append([xmin,xmax])
zoneHB.append([ymin,ymax])
except TypeError:return zoneL,zoneWB,zoneHB
return zoneL,zoneWB,zoneHB
個別の接着剤文字コード:
# 切断位置
im_position =CFS(im)
maxL =max(im_position[0])
minL =min(im_position[0])
# ハイフンがある場合、文字の長さが長すぎる場合は、ハイフンと見なされ、中央から切り取られます
if(maxL minL + minL *0.7):
maxL_index = im_position[0].index(maxL)
minL_index = im_position[0].index(minL)
# 文字幅を設定する
im_position[0][maxL_index]= maxL // 2
im_position[0].insert(maxL_index +1, maxL // 2)
# 文字X軸を設定する[始まりと終わり]ポジション
im_position[1][maxL_index][1]= im_position[1][maxL_index][0]+ maxL // 2
im_position[1].insert(maxL_index +1,[im_position[1][maxL_index][1]+1, im_position[1][maxL_index][1]+1+ maxL // 2])
# キャラクターのY軸を設定する[始まりと終わり]ポジション
im_position[2].insert(maxL_index +1, im_position[2][maxL_index])
# 文字をカットするには、うまくカットしたい場合はパラメータを設定する必要があります。通常は1または2で十分です。
cutting_img(im,im_position,img_name,1,1)
接着剤コードの切断:
def cutting_img(im,im_position,img,xoffset =1,yoffset =1):
filename ='./out_img/'+ img.split('.')[0]
# 認識された文字の数
im_number =len(im_position[1])
# 文字をカット
for i inrange(im_number):
im_start_X = im_position[1][i][0]- xoffset
im_end_X = im_position[1][i][1]+ xoffset
im_start_Y = im_position[2][i][0]- yoffset
im_end_Y = im_position[2][i][1]+ yoffset
cropped = im[im_start_Y:im_end_Y, im_start_X:im_end_X]
cv2.imwrite(filename +'-cutting-'+str(i)+'.jpg',cropped)
識別
認識はtypesseractライブラリを使用します。このライブラリは、主に1行の文字と1文字のパラメータ設定を認識し、中国語と英語のパラメータ設定を認識します。コードは非常に単純で1行です。ここでの操作のほとんどはフィルタファイルです。
コード:
# 識別確認コード
cutting_img_num =0for file in os.listdir('./out_img'):
str_img =''iffnmatch(file,'%s-cutting-*.jpg'% img_name.split('.')[0]):
cutting_img_num +=1for i inrange(cutting_img_num):try:
file ='./out_img/%s-cutting-%s.jpg'%(img_name.split('.')[0], i)
# 文字を認識する
str_img = str_img +image_to_string(Image.open(file),lang ='eng', config='-psm 10') #1文字は10、1行のテキストは7です。
except Exception as err:
pass
print('作物:%s'% cutting_img_num)print('認識:%s'% str_img)
最後に、この種の接着剤文字の認識率は約30%で、この種類の接着剤は2文字の接着剤しか扱っていないため、2文字以上の接着剤があると認識できませんが、文字幅で区別するのは難しくありません。それを試してみてください
カットせずに文字認識の効果:

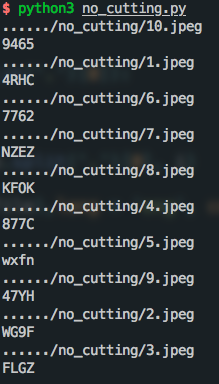
カットする文字の認識効果:

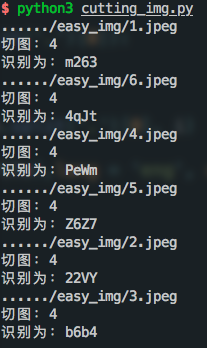
これは単純な検証コードしか認識できず、複雑な検証コードはすべての人に任されています
参考資料:
1、https://www.zalou.cn/article/141621.htm
たくさんの情報を参考にしていますが、久しぶりに見つかりません。誰か見つけたら教えてください。追加します。
指示:
1.認識される検証コードイメージをスクリプトと同じレベルのimgフォルダーに配置し、out_imgフォルダーを作成します。
2、python3 filename
3.二値化とノイズ低減の各段階の写真がout_imgフォルダーに保存され、最終的な認識結果が画面に印刷されます。
最後に、ソースコードを添付します(切り取りを使用して、切り取りたくない場合は自分で変更します)。
from PIL import Image
from pytesseract import*from fnmatch import fnmatch
from queue import Queue
import matplotlib.pyplot as plt
import cv2
import time
import os
def clear_border(img,img_name):'''境界線を削除します
'''
filename ='./out_img/'+ img_name.split('.')[0]+'-clearBorder.jpg'
h, w = img.shape[:2]for y inrange(0, w):for x inrange(0, h):
# if y ==0 or y == w -1 or y == w -2:if y <4 or y w -4:
img[x, y]=255
# if x ==0 or x == h -1 or x == h -2:if x <4 or x h -4:
img[x, y]=255
cv2.imwrite(filename,img)return img
def interference_line(img, img_name):'''
干渉線ノイズの低減
'''
filename ='./out_img/'+ img_name.split('.')[0]+'-interferenceline.jpg'
h, w = img.shape[:2]
# ! ! ! opencvマトリックスポイントは逆です
# img[1,2]1:写真の高さ、2:写真の幅
for y inrange(1, w -1):for x inrange(1, h -1):
count =0if img[x, y -1]245:
count = count +1if img[x, y +1]245:
count = count +1if img[x -1, y]245:
count = count +1if img[x +1, y]245:
count = count +1if count 2:
img[x, y]=255
cv2.imwrite(filename,img)return img
def interference_point(img,img_name, x =0, y =0):"""ポイントノイズリダクション
9 近所の箱,現在のポイントを中心としたフィールドボックス,黒い点の数
: param x::param y::return:"""
filename ='./out_img/'+ img_name.split('.')[0]+'-interferencePoint.jpg'
# todo画像の長さと幅の下限を決定します
cur_pixel = img[x,y]#現在のピクセル値
height,width = img.shape[:2]for y inrange(0, width -1):for x inrange(0, height -1):if y ==0: #最初の行
if x ==0: #左上の頂点,4近所
# 中心点の隣に3点
sum =int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=2*245:
img[x, y]=0
elif x == height -1: #右上の頂点
sum =int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y +1])if sum <=2*245:
img[x, y]=0else: #トップ非頂点,6近所
sum =int(img[x -1, y]) \
+ int(img[x -1, y +1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=3*245:
img[x, y]=0
elif y == width -1: #結論
if x ==0: #左下の頂点
# 中心点の隣に3点
sum =int(cur_pixel) \
+ int(img[x +1, y]) \
+ int(img[x +1, y -1]) \
+ int(img[x, y -1])if sum <=2*245:
img[x, y]=0
elif x == height -1: #右下の頂点
sum =int(cur_pixel) \
+ int(img[x, y -1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y -1])if sum <=2*245:
img[x, y]=0else: #下部の非頂点,6近所
sum =int(cur_pixel) \
+ int(img[x -1, y]) \
+ int(img[x +1, y]) \
+ int(img[x, y -1]) \
+ int(img[x -1, y -1]) \
+ int(img[x +1, y -1])if sum <=3*245:
img[x, y]=0else: #yは境界上にありません
if x ==0: #左側の非頂点
sum =int(img[x, y -1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y -1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=3*245:
img[x, y]=0
elif x == height -1: #右側の非頂点
sum =int(img[x, y -1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x -1, y -1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y +1])if sum <=3*245:
img[x, y]=0else: #9つの分野で認定
sum =int(img[x -1, y -1]) \
+ int(img[x -1, y]) \
+ int(img[x -1, y +1]) \
+ int(img[x, y -1]) \
+ int(cur_pixel) \
+ int(img[x, y +1]) \
+ int(img[x +1, y -1]) \
+ int(img[x +1, y]) \
+ int(img[x +1, y +1])if sum <=4*245:
img[x, y]=0
cv2.imwrite(filename,img)return img
def _get_dynamic_binary_image(filedir, img_name):'''
適応しきい値の2値化
'''
filename ='./out_img/'+ img_name.split('.')[0]+'-binary.jpg'
img_name = filedir +'/'+ img_name
print('.....'+ img_name)
im = cv2.imread(img_name)
im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
th1 = cv2.adaptiveThreshold(im,255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY,21,1)
cv2.imwrite(filename,th1)return th1
def _get_static_binary_image(img, threshold =140):'''
手動の2値化
'''
img = Image.open(img)
img = img.convert('L')
pixdata = img.load()
w, h = img.size
for y inrange(h):for x inrange(w):if pixdata[x, y]< threshold:
pixdata[x, y]=0else:
pixdata[x, y]=255return img
def cfs(im,x_fd,y_fd):'''過剰なcfsアクセスの問題を解決するために、純粋な再帰ではなく、キューとコレクションを使用してトラバースされたピクセル座標を記録します
'''
# print('**********')
xaxis=[]
yaxis=[]
visited =set()
q =Queue()
q.put((x_fd, y_fd))
visited.add((x_fd, y_fd))
offsets=[(1,0),(0,1),(-1,0),(0,-1)]#4つの近所
while not q.empty():
x,y=q.get()for xoffset,yoffset in offsets:
x_neighbor,y_neighbor = x+xoffset,y+yoffset
if(x_neighbor,y_neighbor)in(visited):continue #すでに訪問しました
visited.add((x_neighbor, y_neighbor))try:if im[x_neighbor, y_neighbor]==0:
xaxis.append(x_neighbor)
yaxis.append(y_neighbor)
q.put((x_neighbor,y_neighbor))
except IndexError:
pass
# print(xaxis)if(len(xaxis)==0|len(yaxis)==0):
xmax = x_fd +1
xmin = x_fd
ymax = y_fd +1
ymin = y_fd
else:
xmax =max(xaxis)
xmin =min(xaxis)
ymax =max(yaxis)
ymin =min(yaxis)
# ymin,ymax=sort(yaxis)return ymax,ymin,xmax,xmin
def detectFgPix(im,xmax):'''検索ブロックの開始
'''
h,w = im.shape[:2]for y_fd inrange(xmax+1,w):for x_fd inrange(h):if im[x_fd,y_fd]==0:return x_fd,y_fd
def CFS(im):'''キャラクターの位置を切る
'''
zoneL=[]#各ブロック長のリストL
zoneWB=[]#各ブロックのX軸[始まりと終わり]リスト
zoneHB=[]#各ブロックのY軸[始まりと終わり]リスト
xmax=0#前のブロックの終わりにある黒い点の横軸,これが初期化です
for i inrange(10):try:
x_fd,y_fd =detectFgPix(im,xmax)
# print(y_fd,x_fd)
xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd)
L = xmax - xmin
H = ymax - ymin
zoneL.append(L)
zoneWB.append([xmin,xmax])
zoneHB.append([ymin,ymax])
except TypeError:return zoneL,zoneWB,zoneHB
return zoneL,zoneWB,zoneHB
def cutting_img(im,im_position,img,xoffset =1,yoffset =1):
filename ='./out_img/'+ img.split('.')[0]
# 認識された文字の数
im_number =len(im_position[1])
# 文字をカット
for i inrange(im_number):
im_start_X = im_position[1][i][0]- xoffset
im_end_X = im_position[1][i][1]+ xoffset
im_start_Y = im_position[2][i][0]- yoffset
im_end_Y = im_position[2][i][1]+ yoffset
cropped = im[im_start_Y:im_end_Y, im_start_X:im_end_X]
cv2.imwrite(filename +'-cutting-'+str(i)+'.jpg',cropped)
def main():
filedir ='./easy_img'for file in os.listdir(filedir):iffnmatch(file,'*.jpeg'):
img_name = file
# 適応しきい値の2値化
im =_get_dynamic_binary_image(filedir, img_name)
# 境界線を削除します
im =clear_border(im,img_name)
# 干渉線のノイズ低減
im =interference_line(im,img_name)
# 写真のノイズリダクションを行います
im =interference_point(im,img_name)
# 切断位置
im_position =CFS(im)
maxL =max(im_position[0])
minL =min(im_position[0])
# ハイフンがある場合、文字の長さが長すぎる場合は、ハイフンと見なされ、中央から切り取られます
if(maxL minL + minL *0.7):
maxL_index = im_position[0].index(maxL)
minL_index = im_position[0].index(minL)
# 文字幅を設定する
im_position[0][maxL_index]= maxL // 2
im_position[0].insert(maxL_index +1, maxL // 2)
# 文字X軸を設定する[始まりと終わり]ポジション
im_position[1][maxL_index][1]= im_position[1][maxL_index][0]+ maxL // 2
im_position[1].insert(maxL_index +1,[im_position[1][maxL_index][1]+1, im_position[1][maxL_index][1]+1+ maxL // 2])
# キャラクターのY軸を設定する[始まりと終わり]ポジション
im_position[2].insert(maxL_index +1, im_position[2][maxL_index])
# 文字をカットするには、うまくカットしたい場合はパラメータを設定する必要があります。通常は1または2で十分です。
cutting_img(im,im_position,img_name,1,1)
# 識別確認コード
cutting_img_num =0for file in os.listdir('./out_img'):
str_img =''iffnmatch(file,'%s-cutting-*.jpg'% img_name.split('.')[0]):
cutting_img_num +=1for i inrange(cutting_img_num):try:
file ='./out_img/%s-cutting-%s.jpg'%(img_name.split('.')[0], i)
# 識別確認コード
str_img = str_img +image_to_string(Image.open(file),lang ='eng', config='-psm 10') #1文字は10、1行のテキストは7です。
except Exception as err:
pass
print('作物:%s'% cutting_img_num)print('認識:%s'% str_img)if __name__ =='__main__':main()
上記はPython検証コード認識の詳細な内容です。Python検証コード認識の詳細については、ZaLou.Cnの他の関連記事に注意してください。
Recommended Posts