Concise summary of Ceph deployment on Centos7
Recently, I need to study Ceph and deploy some environment. This article is divided into chapters 1, 2, 3, and 4 for concept introduction, and chapter 5 for practice.
1 Ceph basic introduction
Ceph is a reliable, automatic rebalancing, and automatic recovery distributed storage system. According to the scene, Ceph can be divided into three major parts, namely [Object Storage] (https://cloud.tencent.com/product/cos?from=10680), block device storage and file system services. In the field of virtualization, Ceph block device storage is more commonly used. For example, in the OpenStack project, Ceph block device storage can be connected to OpenStack's cinder back-end storage, Glance image storage and virtual machine data storage, which is more intuitive The Ceph cluster can provide a raw format block storage as the hard disk of the virtual machine instance.
The advantage of Ceph over other storage is that it is not only storage, but also makes full use of the computing power on the storage node. When storing each data, it will calculate the location of the data storage, and try to balance the data distribution. At the same time, because of the good design of Ceph, the CRUSH algorithm, HASH ring and other methods are used, so that it does not have the traditional single point of failure problem, and the performance will not be affected as the scale expands.
2 Ceph core components
The core components of Ceph include Ceph OSD, Ceph Monitor and Ceph MDS.
Ceph OSD: The full English name of OSD is Object Storage Device. Its main function is to store data, copy data, balance data, restore data, etc., perform heartbeat checks with other OSDs, etc., and report some changes to Ceph Monitor . Generally, a hard disk corresponds to an OSD, and the storage of the hard disk is managed by the OSD. Of course, a partition can also become an OSD.
The architecture of Ceph OSD consists of physical disk drives, Linux file systems and Ceph OSD services. For Ceph OSD Deamon, the Linux file system explicitly supports its scalability. Generally, there are several Linux file systems, such as BTRFS. , XFS, Ext4, etc. Although BTRFS has many advantages and features, it has not yet reached the stability required by the production environment. XFS is generally recommended.
There is also a concept accompanying OSD called Journal disk. Generally, when writing data to a Ceph cluster, the data is written to the Journal disk first, and then the data in the Journal disk is refreshed to the file system every once in a while, for example, 5 seconds. in. Generally speaking, in order to make the read and write latency smaller, the Journal disk uses SSD, and generally allocates more than 10G. Of course, it is better to allocate more points. The concept of the Journal disk is introduced in Ceph because the Journal allows the Ceph OSD function to be quickly made smaller. Write operation; a random write is first written to the previous continuous journal, and then flushed to the file system. This gives the file system enough time to merge and write to the disk. In general, using SSD as the OSD journal can effectively buffer Burst load.
Ceph Monitor: From the English name, we can know that it is a monitor, responsible for monitoring the Ceph cluster, maintaining the health of the Ceph cluster, and maintaining various Map maps in the Ceph cluster, such as OSD Map, Monitor Map, PG Map and CRUSH Map. These Maps are collectively called Cluster Map. Cluster Map is the key data structure of RADOS. It manages the distribution of all members, relationships, attributes and other information in the cluster, as well as data. You need to get the latest map through the Monitor first, and then calculate the final storage location of the data based on the map and object id.
Ceph MDS: The full name is Ceph MetaData Server, which mainly saves metadata of file system services, but object storage and block storage devices do not need to use this service.
To view the information of various maps, you can use the following command: ceph osd(mon, pg) dump
3 Ceph infrastructure components
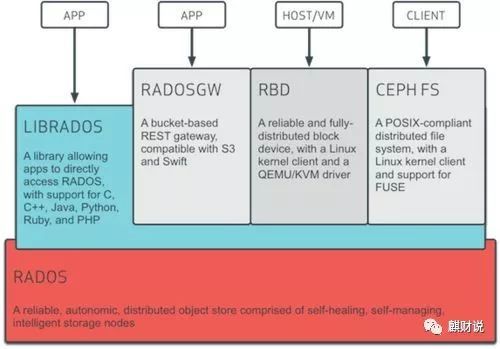
From the architecture diagram, you can see that the bottom layer is RADOS. RADOS itself is a complete distributed object storage system. It has the characteristics of reliability, intelligence, and distribution. Ceph is highly reliable, highly scalable, high-performance, and highly automated. All are provided by this layer, and the storage of user data is ultimately stored through this layer. RADOS can be said to be the core of Ceph.
The RADOS system is mainly composed of two parts, namely OSD and Monitor.
The upper layer based on the RADOS layer is LIBRADOS. LIBRADOS is a library that allows applications to interact with the RADOS system by accessing the library and supports multiple programming languages, such as C, C++, Python, etc.
Based on the LIBRADOS layer development, you can see that there are three layers, namely RADOSGW, RBD and CEPH FS.
RADOSGW: RADOSGW is a set of gateways based on the currently popular RESTFUL protocol and compatible with S3 and Swift.
RBD: RBD provides a distributed block device through the Linux kernel client and QEMU/KVM driver.
CEPH FS: CEPH FS provides a POSIX compatible file system through Linux kernel client and FUSE.
4 Introduction to Ceph Storage
The relationship between stored data and objects: When a user wants to store data in a Ceph cluster, the stored data will be divided into multiple objects. Each object has an object id. The size of each object can be set. The default is 4MB , Object can be regarded as the smallest storage unit of Ceph storage.
The relationship between object and pg: Due to the large number of objects, Ceph introduces the concept of pg to manage objects. Each object is finally mapped to a pg through CRUSH calculation. A pg can contain multiple objects.
Summary through experiments:
(1) PG is the number of directories that specify storage pool storage objects, and PGP is the number of OSD distribution combinations of storage pool PG
(2) The increase of PG will cause the data in PG to split, split among the newly generated PG on the same OSD
(3) The increase of PGP will cause the distribution of some PGs to change, but it will not cause changes in the objects in the PG
The relationship between pg and pool: pool is also a logical storage concept. When we create a storage pool, we need to specify the number of pg and pgp. Logically speaking, pg belongs to a storage pool, just like an object belongs to a certain storage pool. pg.
The following figure shows the relationship between storage data, object, pg, pool, osd, and storage disk
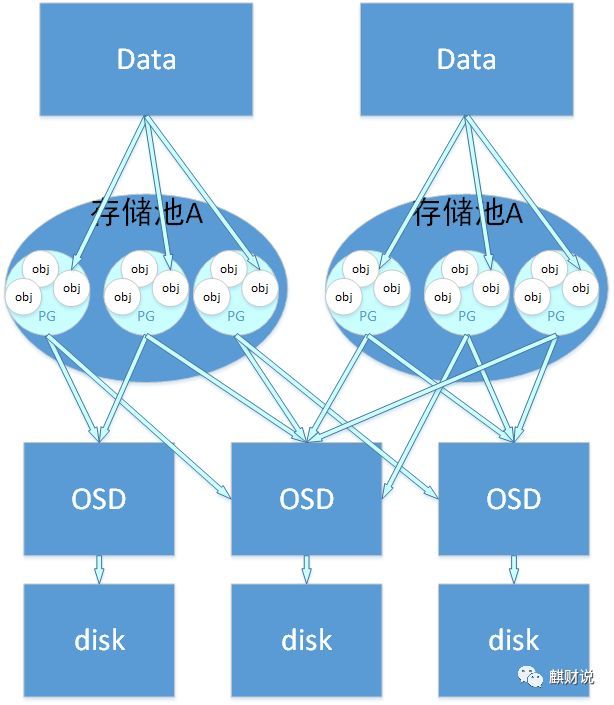
- Note: The above is a quoted article 1*
5 deploy
Environmental preparation,
All servers install centos7.5192.168.3.8 ceph-admin(ceph-deploy) mds1, mon1 (you can also put the monit node on another machine)
192.168.3.7 ceph-node1 osd1
192.168.3.6 ceph-node2 osd2
-------------------------------------------------
Modify the host name of each node
# hostnamectl set-hostname ceph-admin
# hostnamectl set-hostname ceph-node1
# hostnamectl set-hostname ceph-node2
-------------------------------------------------
Host name mapping for each node binding
# cat /etc/hosts
192.168.3.8 ceph-admin
192.168.3.7 ceph-node1
192.168.3.6 ceph-node2
-------------------------------------------------
Each node confirms connectivity
# ping -c 3 ceph-admin
# ping -c 3 ceph-node1
# ping -c 3 ceph-node2
-------------------------------------------------
Turn off the firewall and selinux on each node
# systemctl stop firewalld
# systemctl disable firewalld
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g'/etc/selinux/config
# setenforce 0-------------------------------------------------
Install and configure NTP for each node (the official recommendation is to install and configure NTP for all nodes in the cluster, and you need to ensure that the system time of each node is consistent. If you don't deploy your own ntp server, synchronize NTP online)
# yum install ntp ntpdate ntp-doc -y
# systemctl restart ntpd
# systemctl status ntpd
-------------------------------------------------
Prepare yum source for each node
Delete the default source, foreign ones are slower
# yum clean all
# mkdir /mnt/bak
# mv /etc/yum.repos.d/* /mnt/bak/
Download Alibaba Cloud's base source and epel source
# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
Add ceph source
# vim /etc/yum.repos.d/ceph.repo
[ ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
gpgcheck=0
priority =1
[ ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
gpgcheck=0
priority =1
[ ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS
gpgcheck=0
priority=1
------------------------------------------------------------
Create cephuser user for each node, set sudo permissions
# useradd -d /home/cephuser -m cephuser
# echo "cephuser"|passwd --stdin cephuser
# echo "cephuser ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephuser
# chmod 0440 /etc/sudoers.d/cephuser
# sed -i s'/Defaults requiretty/#Defaults requiretty'/g /etc/sudoers
Test cephuser's sudo permissions
# su - cephuser
$ sudo su -
#
------------------------------------------------------------
Configure mutual ssh trust relationship
Now ceph-Public and private key files are generated on the admin node, and then the ceph-admin node.Copy the ssh directory to other nodes
[ root@ceph-admin ~]# su - cephuser
[ cephuser@ceph-admin ~]$ ssh-keygen -t rsa #Enter all the way
[ cephuser@ceph-admin ~]$ cd .ssh/
[ cephuser@ceph-admin .ssh]$ ls
id_rsa id_rsa.pub
[ cephuser@ceph-admin .ssh]$ cp id_rsa.pub authorized_keys
[ cephuser@ceph-admin .ssh]$ scp -r /home/cephuser/.ssh ceph-node1:/home/cephuser/
[ cephuser@ceph-admin .ssh]$ scp -r /home/cephuser/.ssh ceph-node2:/home/cephuser/
Then directly verify the ssh mutual trust relationship under the cephuser user at each node
$ ssh -p22 cephuser@ceph-admin
$ ssh -p22 cephuser@ceph-node1
$ ssh -p22 cephuser@ceph-node2
[ root@ceph-admin ~]# su - cephuser
Install ceph-deploy
[ cephuser@ceph-admin ~]$ sudo yum update -y && sudo yum install ceph-deploy -y
Create a cluster directory
[ cephuser@ceph-admin ~]$ mkdir cluster
[ cephuser@ceph-admin ~]$ cd cluster/[cephuser@ceph-admin cluster]$ ceph-deploy newceph-admin ceph-node1 ceph-node2
[ cephuser@ceph-admin cluster]$ vim ceph.conf
Add the following content to the configuration file
osd pool default size =2
mon_clock_drift_allowed =1[cephuser@ceph-admin cluster]$ ceph-deploy install --release=luminous ceph-admin ceph-node1 ceph-node2
Initialize the monit monitoring node and collect all keys
[ cephuser@ceph-admin cluster]$ ceph-deploy mon create-initial
[ cephuser@ceph-admin cluster]$ ceph-deploy gatherkeys ceph-admin
Add OSD to the cluster
Check all available disks on the OSD node
[ cephuser@ceph-admin cluster]$ ceph-deploy disk list ceph-node1 ceph-node2
[ cephuser@ceph-admin ~]$ ssh ceph-node1 "sudo mkdir /var/local/osd0 && sudo chown ceph:ceph /var/local/osd0"[cephuser@ceph-admin ~]$ ssh ceph-node2 "sudo mkdir /var/local/osd1 && sudo chown ceph:ceph /var/local/osd1"[cephuser@ceph-admin ~]$ ceph-deploy osd prepare ceph-node1:/var/local/osd0 ceph-node2:/var/local/osd1
[ cephuser@ceph-admin ~]$ ceph-deploy osd activate ceph-node1:/var/local/osd0 ceph-node2:/var/local/osd1
Update configuration
[ cephuser@ceph-admin ~]$ ceph-deploy admin ceph-admin ceph-node1 ceph-node2
[ cephuser@ceph-admin ~]$ sudo chmod +r /etc/ceph/ceph.client.admin.keyring
[ cephuser@ceph-admin ~]$ ssh ceph-node1 sudo chmod +r /etc/ceph/ceph.client.admin.keyring
[ cephuser@ceph-admin ~]$ ssh ceph-node2 sudo chmod +r /etc/ceph/ceph.client.admin.keyring
test
service status
[ cephuser@ceph-admin ~]$ ceph health
HEALTH_OK
[ cephuser@ceph-admin ~]$ ceph -s
cluster 50fcb154-c784-498e-9045-83838bc3018e
health HEALTH_OK
monmap e1:3 mons at {ceph-admin=192.16.3.8:6789/0,ceph-node1=192.16.3.7:6789/0,ceph-node2=192.16.3.6:6789/0}
election epoch 4, quorum 0,1,2 ceph-node2,ceph-node1,ceph-admin
osdmap e12:2 osds:2 up,2in
flags sortbitwise,require_jewel_osds
pgmap v624:64 pgs,1 pools,136 MB data,47 objects
20113 MB used,82236 MB /102350 MB avail
64 active+clean
Mount test
[ cephuser@ceph-admin ~]$ sudo rbd create foo --size 4096-m ceph-node1
[ cephuser@ceph-admin ~]$ sudo rbd map foo --pool rbd --name client.admin -m ceph-node1
[ cephuser@ceph-admin ~]$ sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo
[ cephuser@ceph-admin ~]$ sudo mkdir /mnt/ceph-block-device
[ cephuser@ceph-admin ~]$ sudo mount /dev/rbd/rbd/foo /mnt/ceph-block-device
The basic environment is now set up, but if you want to configure it, there is still some way to go.
If you don't have children's shoes in the environment, you can consider using vagrant to simulate. The connection of reference material 2 is a vagrant project, which is very easy to use.
Reference materials:
Recommended Posts