Python example to calculate IV value
After the variables are binned, the importance of the variable needs to be calculated. IV is one of the statistics to evaluate the discrimination or importance of the variable. The code for calculating the IV value in python is as follows:
def CalcIV(Xvar, Yvar):
N_0 = np.sum(Yvar==0)
N_1 = np.sum(Yvar==1)
N_0_group = np.zeros(np.unique(Xvar).shape)
N_1_group = np.zeros(np.unique(Xvar).shape)for i inrange(len(np.unique(Xvar))):
N_0_group[i]= Yvar[(Xvar == np.unique(Xvar)[i])&(Yvar ==0)].count()
N_1_group[i]= Yvar[(Xvar == np.unique(Xvar)[i])&(Yvar ==1)].count()
iv = np.sum((N_0_group/N_0 - N_1_group/N_1)* np.log((N_0_group/N_0)/(N_1_group/N_1)))return iv
def caliv_batch(df, Kvar, Yvar):
df_Xvar = df.drop([Kvar, Yvar], axis=1)
ivlist =[]for col in df_Xvar.columns:
iv =CalcIV(df[col], df[Yvar])
ivlist.append(iv)
names =list(df_Xvar.columns)
iv_df = pd.DataFrame({'Var': names,'Iv': ivlist}, columns=['Var','Iv'])return iv_df
Among them, df is the data set after binning, Kvar is the primary key, and Yvar is the y variable (0 is good, 1 is bad).
The code running results are as follows:
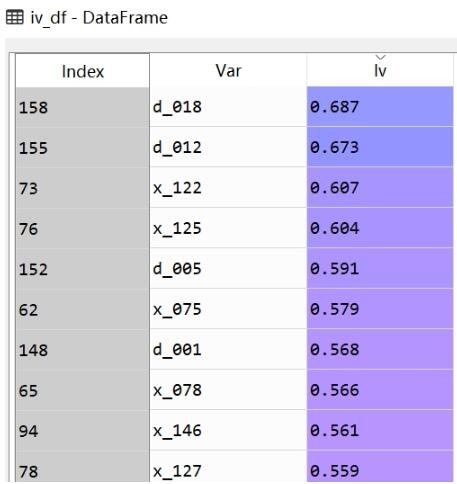
Supplementary extension: python basic IV (slicing, iteration, generating list)
Slice the list
It is a very common operation to take some elements of a list. For example, a list is as follows:
L = [‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
What should I do to take the first 3 elements?
Stupid way:
[ L[0], L[1], L[2]]
[ ‘Adam’, ‘Lisa’, ‘Bart’]
The reason for the stupid way is because it is expanded to take the first N elements.
Take the first N elements, that is, the elements with index 0-(N-1), you can use a loop:
r =[]
n =3for i inrange(n):... r.append(L[i])...
r
[' Adam','Lisa','Bart']
For this type of operation that often takes a specified index range, it is very cumbersome to use a loop. Therefore, Python provides a slice (Slice) operator, which can greatly simplify this operation.
Corresponding to the above question, take the first 3 elements and use one line of code to complete the slice:
L[0:3]
[ ‘Adam’, ‘Lisa’, ‘Bart’]
L[0:3] means that it starts from index 0 and ends at index 3, but does not include index 3. That is, indexes 0, 1, 2, are exactly 3 elements.
If the first index is 0, you can also omit:
L[:3]
[ ‘Adam’, ‘Lisa’, ‘Bart’]
You can also start at index 1, and take out 2 elements:
L[1:3]
[ ‘Lisa’, ‘Bart’]
Only use one:, which means from beginning to end:
L[:]
[ ‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
Therefore, L[:] actually copied a new list.
The slicing operation can also specify a third parameter:
L[::2]
[ ‘Adam’, ‘Bart’]
The third parameter means to take one for every N. The above L[::2] will take one for every two elements, that is, take one every other.
Replacing list with tuple, the slicing operation is exactly the same, but the result of slicing also becomes a tuple.
Reverse slicing
For list, since Python supports L[-1] to take the first element from the bottom, it also supports reciprocal slicing. Try:
L =['Adam','Lisa','Bart','Paul']
L[-2:]['Bart','Paul']
L[:-2]['Adam','Lisa']
L[-3:-1]['Lisa','Bart']
L[-4:-1:2]['Adam','Bart']
Remember that the index of the penultimate element is -1. The reverse slice contains the starting index, but not the ending index.
Slice string
The string'xxx' and the Unicode string u'xxx' can also be regarded as a kind of list, and each element is a character. Therefore, the string can also be sliced, but the result of the operation is still a string:
' ABCDEFG'[:3]'ABC''ABCDEFG'[-3:]'EFG''ABCDEFG'[::2]'ACEG'
In many programming languages, various interception functions are provided for strings, but the purpose is to slice strings. Python does not have an interception function for strings. It only needs to slice one operation to complete, which is very simple.
What is iteration
In Python, if a list or tuple is given, we can traverse this list or tuple through a for loop, and this traversal is called Iteration.
In Python, iteration is done through for… in, while in many languages such as C or Java, iterating list is done through subscripts, such as Java code:
for(i=0; i<list.length; i++){
n = list[i];}
It can be seen that Python's for loop is more abstract than Java's for loop.
Because Python's for loop can be used not only on lists or tuples, but also on any other iterable objects.
Therefore, the iterative operation is for a collection, no matter whether the collection is ordered or unordered, we can always use a for loop to retrieve each element of the collection in turn.
Note: A collection refers to a data structure that contains a group of elements. The ones we have introduced include:
-
Ordered collection: list, tuple, str and unicode;
-
Unordered collection: set
-
Unordered collection with key-value pairs: dict
And iteration is a verb, it refers to an operation, in Python, it is a for loop.
The biggest difference between iterating and accessing an array by index is that the latter is a specific iterative implementation, while the former only cares about the results of the iteration, not how it is implemented internally.
Index iteration
In Python, iteration always takes out the element itself, not the index of the element.
For ordered collections, the elements are indeed indexed. Sometimes, we really want to get the index in the for loop, what should we do?
The method is to use the enumerate() function:
L =['Adam','Lisa','Bart','Paul']for index, name inenumerate(L):... print index,'-', name
...0- Adam
1- Lisa
2- Bart
3- Paul
Using the enumerate() function, we can bind both the index index and the element name in the for loop. However, this is not a special syntax for enumerate(). In fact, the enumerate() function puts:
[ ‘Adam’, ‘Lisa’, ‘Bart’, ‘Paul’]
Becomes something like:
[(0, ‘Adam’), (1, ‘Lisa’), (2, ‘Bart’), (3, ‘Paul’)]
Therefore, each element of the iteration is actually a tuple:
for t inenumerate(L):
index = t[0]
name = t[1]
print index,'-', name
If we know that each tuple element contains two elements, the for loop can be further abbreviated as:
for index, name in enumerate(L):
print index, ‘-‘, name
This not only makes the code simpler, but also eliminates two assignment statements.
It can be seen that index iteration is not really accessed by index, but the enumerate() function automatically turns each element into a tuple such as (index, element), and then iterates, and obtains both the index and the element itself.
Iterate the value of the dict
We have already understood that the dict object itself is an iterable object. Using a for loop to iterate the dict directly, you can get a key of the dict every time.
What if we want to iterate over the value of the dict object?
The dict object has a values() method, which converts the dict into a list containing all the values, so that we iterate over each value of the dict:
d ={'Adam':95,'Lisa':85,'Bart':59}
print d.values()
# [85,95,59] for v in d.values():
print v
# 85
# 95
# 59
If you read the Python documentation carefully, you can also find that in addition to the values() method, dict also has an itervalues() method. Replace the values() method with the itervalues() method. The iteration effect is exactly the same:
d ={'Adam':95,'Lisa':85,'Bart':59}
print d.itervalues()
# < dictionary-valueiterator object at 0x106adbb50for v in d.itervalues():
print v
# 85
# 95
# 59
**What is the difference between these two methods? **
-
The values() method actually converts a dict into a list containing values.
-
But the itervalues() method will not convert, it will take out the value from the dict in the iterative process, so the itervalues() method saves the memory required to generate the list than the values() method.
-
Print itervalues() and find that it returns a <dictionary-valueiterator 对象,这说明在Python中,for 循环可作用的迭代对象远不止 list,tuple,str,unicode,dict等,任何可迭代对象都可以作用于for循环,而内部如何迭代我们通常并不用关心。
If an object is said to be iterable, then we directly use a for loop to iterate it. It can be seen that iteration is an abstract data operation, and it does not have any requirements for the data inside the iterated object.
Iterate the key and value of dict
We know how to iterate the key and value of dict. So, in a for loop, can iterate key and value at the same time? The answer is yes.
First, let's look at the value returned by the items() method of the dict object:
d ={'Adam':95,'Lisa':85,'Bart':59}
print d.items()[('Lisa',85),('Adam',95),('Bart',59)]
As you can see, the items() method converts the dict object into a list containing tuples. We iterate over this list to obtain the key and value at the same time:
for key, value in d.items():... print key,':', value
...
Lisa :85
Adam :95
Bart :59
Similar to values() there is an itervalues(), items() also has a corresponding iteritems(), iteritems() does not convert dict to list, but constantly gives tuples during the iteration process, so iteritems() does not occupy Additional memory.
Generate list
To generate list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], we can use range(1, 11):
range(1, 11)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
But what if you want to generate [1×1, 2×2, 3×3, …, 10×10]? Method one is looping:
L =[]for x inrange(1,11):... L.append(x * x)...
L
[1,4,9,16,25,36,49,64,81,100]
But the loop is too cumbersome, and the list generation can use a line statement to replace the loop to generate the above list:
[ x * x for x inrange(1,11)][1,4,9,16,25,36,49,64,81,100]
This way of writing is a Python-specific list generation. Using the list generation formula, a list can be generated with very concise code.
When writing a list production, put the element x * x to be generated first, followed by a for loop, and then you can create a list. It is very useful. Write it a few times and you will soon be familiar with this syntax.
Complex expression
The iteration using for loop can not only iterate ordinary list, but also iterate dict.
Suppose there is the following dict:
d = { ‘Adam’: 95, ‘Lisa’: 85, ‘Bart’: 59 }
It can be turned into an HTML table through a complex list generation:
tds =['<tr <td %s</td <td %s</td </tr '%(name, score)for name, score in d.iteritems()]
print '<table '
print '<tr <th Name</th <th Score</th <tr '
print '\n'.join(tds)
print '</table '
Note: The character string can be formatted by %, replacing %s with the specified parameters. The join() method of strings can concatenate a list into a string.
Conditional filtering
An if judgment can be added after the for loop of the list-building formula. E.g:
[ x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
If we only want the square of even numbers, without changing the range(), we can add if to filter:
[ x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
With the if condition, the current element of the loop is added to the list only when if the judgment is True.
Multi-level expression
For loops can be nested, therefore, in the list production, you can also use multiple for loops to generate lists.
For the strings'ABC' and '123', two layers of loops can be used to generate full permutations:
[ m + n for m in ‘ABC’ for n in ‘123’]
[ ‘A1’, ‘A2’, ‘A3’, ‘B1’, ‘B2’, ‘B3’, ‘C1’, ‘C2’, ‘C3’]
Translated into a loop code like this:
L =[]for m in'ABC':for n in'123':
L.append(m + n)
The above example of Python calculating IV value is all the content shared by the editor. I hope to give you a reference.
Recommended Posts