Pythonデータサイエンス:ニューラルネットワーク
( 人工神経ネットワーク(ANN)人工神経ネットワークモデル。これは、数学的および物理的方法を使用して、人間の脳神経ネットワークを単純化、抽象化、およびシミュレートします。
今回は、ニューロンモデルとBPニューラルネットワークを含む、ニューラルネットワークの簡単な紹介です。
ここでは、機械学習の3つの要素、つまりモデル、戦略、アルゴリズムについて簡単に説明します。
モデルには、非ランダム効果部分(説明変数と説明変数の関係、主に機能的関係)とランダム効果部分(外乱項)が含まれます。
戦略とは、最適な目的関数を設定する方法を指します。一般的な目的関数には、線形回帰の残差二乗和、ロジスティック回帰の尤度関数、およびSVMのヒンジ関数が含まれます。
アルゴリズムは、導出による計算や数値計算の分野でのアルゴリズムの使用など、目的関数のパラメーターを見つける方法です。
その中で、ニューラルネットワークは数値アルゴリズムを使用してパラメータを解決します。つまり、各計算で取得されるモデルパラメータは異なります。
/ 01 /ニューラルネットワーク
01 ニューロンモデル
ニューラルネットワークの最も基本的なコンポーネントはニューロンモデルです。
各ニューロンは複数入力単一出力情報処理ユニットです。入力信号は加重接続を介して送信され、しきい値と比較した後に合計入力値が取得され、**単一出力*がアクティベーション関数処理によって生成されます。 *。
ニューロンの出力は、入力の加重和をアクティベーション関数に適用した結果です。
ニューロンの活性化機能は、ニューロンの出力とその活性化状態との関係を反映して、ニューロンに異なる情報処理特性を持たせます。
今回の活性化機能には、閾値機能(ステップ機能)とシグモイド機能(シグモイド機能)があります。
02 単層パーセプトロン
パーセプトロンは、線形に分離可能なバイナリ分類問題を解決するためにのみ使用できる、単層コンピューティングユニットを備えたニューラルネットワークです。
多層パーセプトロンには適用できず、隠れ層の期待される出力を決定することはできません。
その構造は、以前のニューロンモデルと同様です。
アクティベーション機能は、ユニポーラ(またはバイポーラ)しきい値機能を使用します。
03 BPニューラルネットワーク
エラーバック伝播アルゴリズム(監視学習アルゴリズム)でトレーニングされた多層ニューラルネットワークは、BPニューラルネットワークと呼ばれます。
これは、多層フィードフォワードニューラルネットワークに属しています。モデルの学習プロセスは、信号の順方向伝搬とエラー逆方向の伝搬の2つのプロセスで構成されます。
順方向伝搬を行う場合、信号は入力層から各層の加重和を計算し、最後に各隠れ層を介して出力層に渡して出力結果を取得し、出力結果を期待値(監視信号)と比較して出力誤差を求めます。
エラー逆伝播は、勾配降下アルゴリズムに基づいて、隠れ層に沿って層ごとにエラーを入力層に伝播し、各層のすべてのユニットにエラーを割り当てて、各ユニットのエラー信号(学習信号)を取得し、それに応じて各ユニットを変更します。単位重量。
これらの2つの信号伝搬プロセスは継続的にループして重みを更新し、最終的に判断条件に従ってループを終了するかどうかを決定します。
ネットワーク構造は通常、入力レイヤー、隠しレイヤー、出力レイヤーを含む単一の隠しレイヤーネットワークです。
アクティベーション関数は主にシグモイド関数または線形関数を使用し、隠れ層と出力層の両方がシグモイド関数を使用します。
/ 02 / Pythonの実装
ニューラルネットワークが明確なトレーニングサンプルを取得した後、ネットワークの入力層ノード番号(説明変数の数)と出力層ノード番号(説明変数の数)が決定されました。
考慮する必要があるのは、非表示レイヤーの数と各非表示レイヤーのノードの数です。
本のデータを使用して、実際の戦闘の波、モバイルオフグリッドデータを実行してみましょう。
モバイル通信ユーザーの消費特性データ。ターゲットフィールドは、2つの分類レベル(はいまたはそうでない)でチャーンするかどうかです。
独立変数には、ユーザーの基本情報、消費される製品情報、およびユーザーの消費特性が含まれます。
データを読み取ります。
import pandas as pd
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
# 表示行の最大数を設定します
pd.set_option('display.max_rows',10)
# 表示される列の最大数を設定します
pd.set_option('display.max_columns',10)
# 表示幅を1000に設定します,このようにすると、IDEでラップされません
pd.set_option('display.width',1000)
# データの読み取り,skipinitialspace:区切り文字の後の空白を無視する
churn = pd.read_csv('telecom_churn.csv', skipinitialspace=True)print(churn)
3000を超えるユーザーデータを含む出力データの概要。
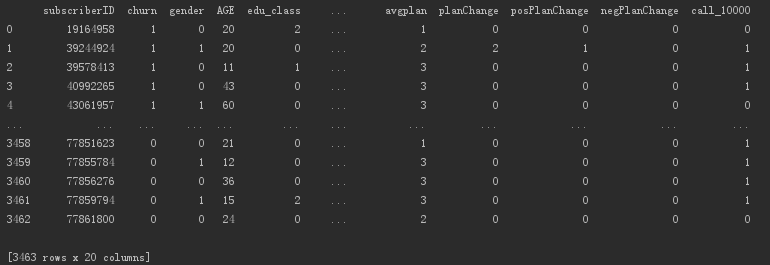
scikit-learnの関数を使用して、データセットをトレーニングセットとテストセットに分割します。
# 独立変数データを選択する
data = churn.iloc[:,2:]
# 従属変数データを選択する
target = churn['churn']
# scikitを使用する-learnは、データセットをトレーニングセットとテストセットに分割します
train_data, test_data, train_target, test_target =train_test_split(data, target, test_size=0.4, train_size=0.6, random_state=1234)
ニューラルネットワークは、データを極端に正規化する必要があります。
連続変数は極値で標準化する必要があり、カテゴリー変数はダミー変数に変換する必要があります。
その中で、マルチカテゴリの名目変数はダミー変数に変換する必要がありますが、グレード変数とバイナリカテゴリ変数は変更しないことを選択でき、連続変数として扱うことができます。
このデータでは、教育レベルとパッケージタイプはグレード変数であり、性別などの変数はバイナリ変数であり、連続変数として扱うことができます。
これは、今回のデータセットには複数のカテゴリの名目変数がなく、すべて連続変数として扱うことができることを意味します。
# 極値の正規化
scaler =MinMaxScaler()
scaler.fit(train_data)
scaled_train_data = scaler.transform(train_data)
scaler_test_data = scaler.transform(test_data)
多層パーセプトロンモデルを構築します。
# 多層パーセプトロンに対応するモデルを設定します
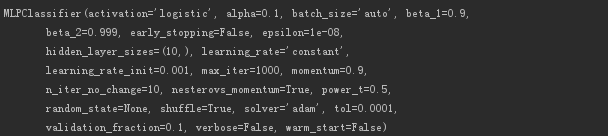
mlp =MLPClassifier(hidden_layer_sizes=(10,), activation='logistic', alpha=0.1, max_iter=1000)
# トレーニングセットのモデルトレーニング
mlp.fit(scaled_train_data, train_target)
# ニューラルネットワークモデル情報を出力する
print(mlp)
出力モデル情報は以下のとおりです。
次に、トレーニングセットでトレーニングされたモデルを使用して、トレーニングセットとテストセットの予測を行います。
# モデルを使用して予測を行う
train_predict = mlp.predict(scaled_train_data)
test_predict = mlp.predict(scaler_test_data)
予測確率、ユーザー損失の確率を出力します。
# 出力モデルの予測確率(1件)
train_proba = mlp.predict_proba(scaled_train_data)[:,1]
test_proba = mlp.predict_proba(scaler_test_data)[:,1]
モデルを評価し、評価データを出力します。
# 予測情報に基づくモデル評価結果の出力
print(metrics.confusion_matrix(test_target, test_predict, labels=[0,1]))print(metrics.classification_report(test_target, test_predict))
出力は次のとおりです。
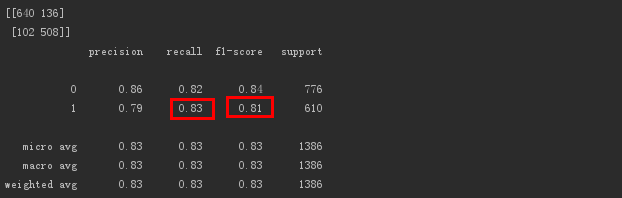
失われたユーザーに対するモデルのf1スコア(精度率とリコール率の調和した平均)値は0.81であり、効果は良好です。
さらに、失われたユーザーの感度リコールは0.83であり、モデルは失われたユーザーの83%を識別できます。これは、失われたユーザーを識別するモデルの機能が許容できることを示しています。
出力モデル予測の平均精度。
# 指定されたデータセットを使用して、モデル予測の平均精度を出力します
print(mlp.score(scaler_test_data, test_target))
# 出力値は0です.8282828282828283
平均精度値は0.8282です。
モデルのROCの下の面積を計算します。
# ROC曲線を描く
fpr_test, tpr_test, th_test = metrics.roc_curve(test_target, test_proba)
fpr_train, tpr_train, th_train = metrics.roc_curve(train_target, train_proba)
plt.figure(figsize=[3,3])
plt.plot(fpr_test, tpr_test,'b--')
plt.plot(fpr_train, tpr_train,'r-')
plt.title('ROC curve')
plt.show()
# AUC値を計算する
print(metrics.roc_auc_score(test_target, test_proba))
# 出力値は0です.9149632415075206
ROC曲線は次のとおりです。
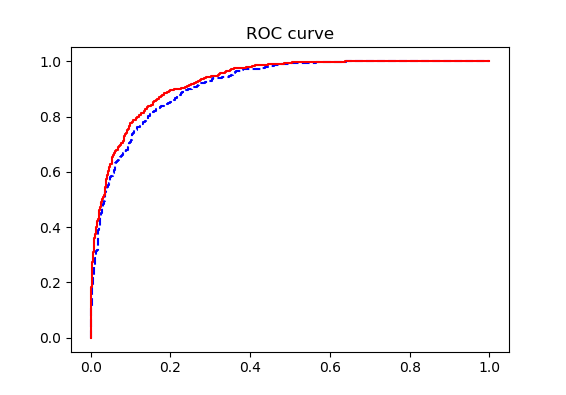
トレーニングセットとテストセットの曲線は非常に近く、オーバーフィットはありません。
AUC値は0.9149であり、モデルが非常に効果的であることを示しています。
モデルの最適なパラメータを検索し、最適なパラメータでモデルをトレーニングします。
# 最適なパラメータ検索のためにGridSearchCVを使用する
param_grid ={
# モデル内の非表示レイヤーの数
' hidden_layer_sizes':[(10,),(15,),(20,),(5,5)],
# アクティベーション機能
' activation':['logistic','tanh','relu'],
# 正規化係数
' alpha':[0.001,0.01,0.1,0.2,0.4,1,10]}
mlp =MLPClassifier(max_iter=1000)
# rocを選択してください_基準としてのauc,4倍の相互検証,n_jobs=-1マルチコアCPUのすべてのスレッドを使用する
gcv =GridSearchCV(estimator=mlp, param_grid=param_grid,
scoring='roc_auc', cv=4, n_jobs=-1)
gcv.fit(scaled_train_data, train_target)
最適なパラメータを出力するモデルの場合。
# 最適なパラメータでモデルのスコアを出力します
print(gcv.best_score_)
# 出力値は0です.9258018987136855
# 最適なパラメータでモデルのパラメータを出力します
print(gcv.best_params_)
# 出力パラメータ値は{'alpha':0.01,'activation':'tanh','hidden_layer_sizes':(5,5)}
# 指定されたデータセットを使用して、最適なモデル予測の平均精度を出力します
print(gcv.score(scaler_test_data, test_target))
# 出力値は0です.9169384823390232
モデルのroc_aucの最高スコアは0.92です。つまり、このモデルのROC曲線の下の面積は0.92です。
以前の0.9149と比較して、少し改善されています。
モデルの最適なパラメータであるアクティベーション関数はreluタイプ、アルファは0.01、隠れ層ノードの数は15です。
モデルの平均予測精度は0.9169であり、以前の0.8282よりもはるかに高くなっています。
Recommended Posts