Pythonデータサイエンス:関連分析
現在、「Pythonによるデータ分析」と「Pythonデータサイエンス」の2冊の本が手元にあります。
すべてを学ぶために、その「ダオ」と「スキル」があります。 「タオ」は原則を意味し、「テクニック」はテクニックを意味します。
最近の2冊の本を見てみると、前者は参考書のようなものであることがわかりました。
データの分析方法は実際には教えていないので、レビューに適しています。
後者については、データ分析の原則にさらに注意を払い、データを分析して目的の結果を得る方法を教えてくれます。
したがって、後者は、記述的なデータ分析([データの視覚化](https://cloud.tencent.com/product/yuntu?from=10680))だけでなく、学習の方向として使用されます。
予測データ分析(データモデル予測の構築)により多くの時間を費やす必要があります。
また、前号の本の配達活動が終了し、2人の友人から連絡がありました。
賞品を獲得しなくても悲しんではいけません。Fはすべての人のためにより多くの利益を求めて戦うので、注意してください。
/ 01 /序文
正直なところ、「PythonDataScience」という本は本当に良いです。
専門用語の説明だけでなく、わかりやすいさまざまな事例も紹介しています。
初心者が学ぶのにとても適しています、そして私たちは間違いなく後で本を送ることの利益のために戦います!
そのため、各記事の冒頭で、「PythonDataScience」の関連コンテンツをいくつか要約します。
一方で、関連する知識についてのあなた自身の印象を深めてください。
一方で、専門的な知識を追加するために、それをみんなと共有しています。
分析プロセスでは、本のデータとケースを使用するのではなく、私自身のパブリックアカウントの記事のデータとケースを使用するようにしてください。
これはもう少し根拠があり、より深遠です。
変数は、「公称変数」、「レベル変数」、「連続変数」に分けられます。
「公称変数」は、順序付けられていないカテゴリ変数です。
たとえば、Douban映画TOP250データの「国」と「映画名」。
「ランク変数」は、通常のカテゴリ変数です。
たとえば、データ分析の投稿の「学歴」と「実務経験」。
「連続変数」とは、指定された範囲内で任意に連続変数を取得できることを意味します。
たとえば、Douban映画のTOP250データの「年」、「評価」、「人数」。
/ 02 /相関分析
上記では、変数のタイプについて簡単に説明し、関連する例も示しました。
次に、** 2つの連続変数間の関係のテストのために相関分析**を実行します。
Douban TOP250のデータを使用して、ランクと評価スコアの関係を調べます。
データを読み取り、クリーンアップします。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# ファイルを読む
df = pd.read_csv('douban.csv', header=0, names=["quote","score","info","title","people"])(dom1, dom2, dom3, dom4)=([],[],[],[])
# クリーンなデータ,映画の年と国を取得する,年列と国列を追加
for i in df['info']:
country = i.split('/')[1].split(' ')[0].strip()if country in['中国本土','台湾','香港']:
dom1.append(1)else:
dom1.append(0)
dom2.append(int(i.split('/')[0].replace('(中国本土)','').strip()))
df['country']= dom1
df['year']= dom2
# クリーンなデータ,レビューアの列を作成する
for i in df['people']:
dom3.append(int(i.replace('評価','')))
df['people_num']= dom3
# 映画ランキングリストを生成する
dom4 =[x for x inrange(1,251)]
df['rank']= dom4
print(df)
その期間のランキングスコアラー数の3次元グラフでは、ランキングが高いほど評価数が多く、スコアが高いことがわかります。
これは私たちの直感的な推測であり、実際にはデータで示されていません。
相関分析では、データを使用して推測の正しさを証明できます。
まず、スキャッターチャートでランキングと評価スコアの関係を調べ、相関関係があるかどうかを確認します。
# 散布図は散布図です
df.plot(x='rank', y='score', kind='scatter')
plt.show()
ここでは、ランキングの問題により線形の負の相関が現れますが、これは分析には影響しません。
デフォルトでは正の相関が設定されます。つまり、ランキングが高いほどスコアが高くなります。
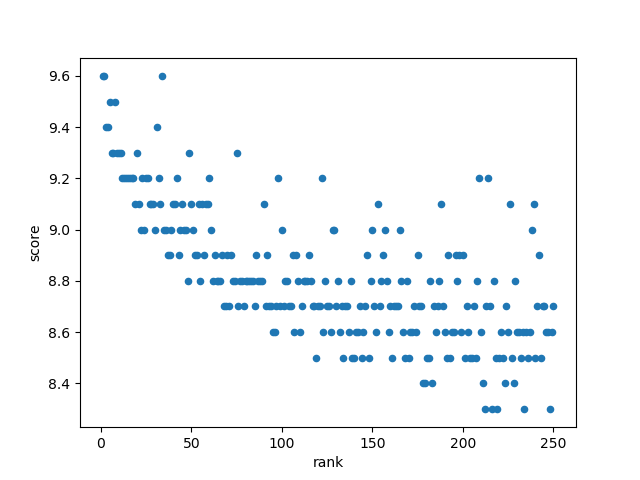
スキャッタプロットを通じて、データには線形相関があることがわかりました。
次に、ピアソンの相関係数を使用して、2つの変数間の相関を分析できます。
# corr()方法:ペアワイズ関連列を計算する,NAを含まない/ヌル値のパーション:標準相関係数
print(df[['rank','score']].corr(method='pearson'))
2つの変数の相関係数を出力します。絶対値は約0.70であり、表は相関度が高いことを示しています。

そうすれば結論は明らかです。**ランクと評価スコアの関係は線形の正の相関関係です。 ! ! ****
相関係数分析による相関分析に加えて、相関分析は散乱行列グラフを介して行うこともできます。
複数の変数間の相関関係を分析して、変数間の関係を調べます。
# 海生まれのリターン/散布図
sns.pairplot(df[['score','people_num','year','country','rank']])
plt.show()
次の散布図を生成すると、ランクがスコアおよびpeople_num(右上隅の2つのグラフ)と高度に相関していることがわかります。
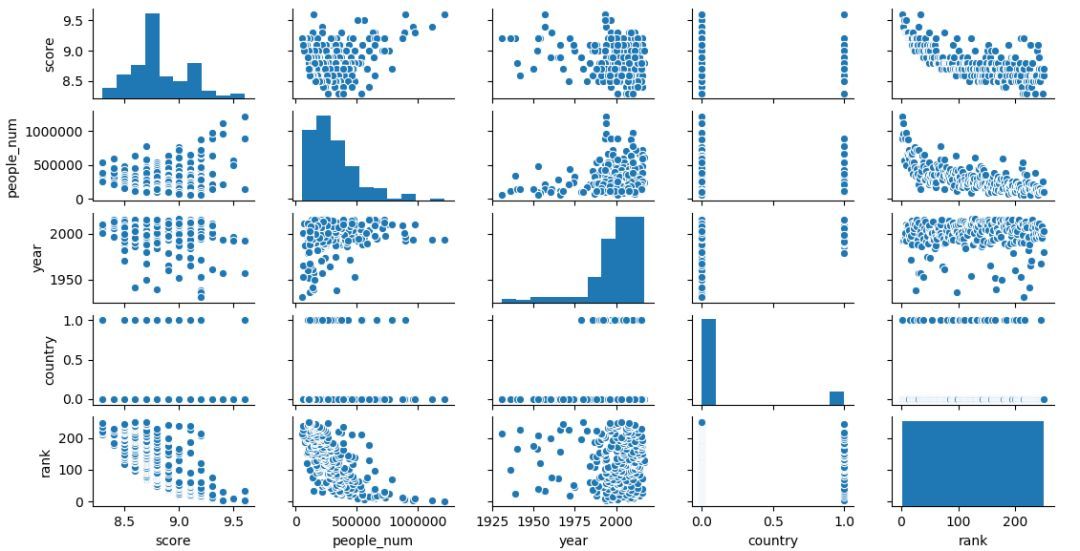
次に、グループ化変数を作成し、グループ化変数として国を指定し、中国および海外のDouban映画のTOP250データを確認します。
# 補助線を使用して散布図行列を生成する,hue:分類
sns.pairplot(df[['score','people_num','year','country','rank']], hue='country', kind='reg', diag_kind='kde', size=1.5)
plt.show()
ここでは、データの適合線と上下の浮動範囲を観察し、変数間の状況をより直感的に理解できます。
ただし、国の分類には何も見つかりません。これは、データサンプルが少なすぎることに関連している可能性があります。
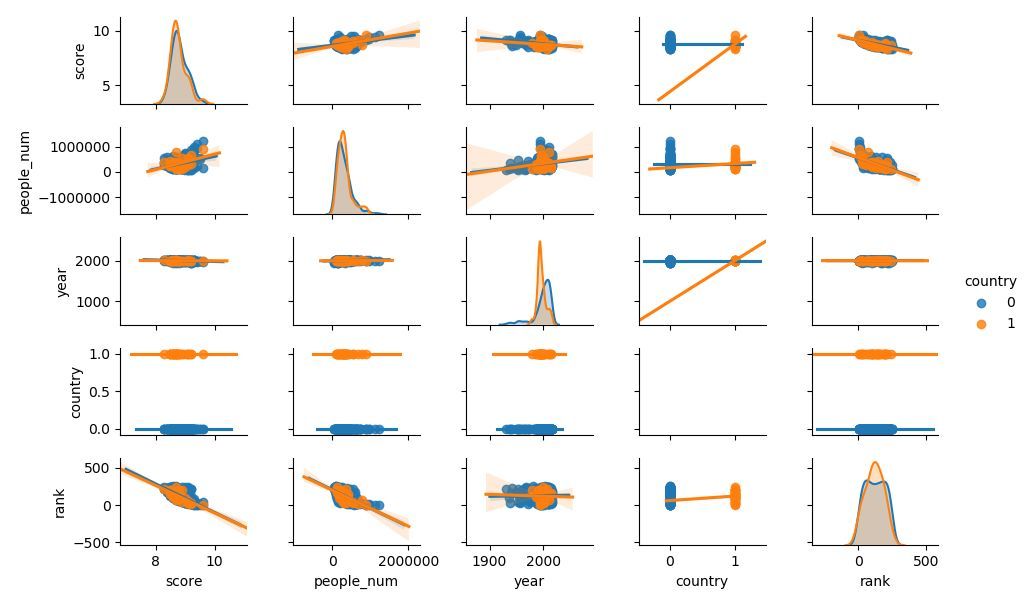
/ 03 /まとめ
今回は単純な関連分析のケースであり、数学的な知識が多すぎるため、詳細には触れません。
この本を読んだ後、学ぶことがたくさんあることに気づきました...
ただし、以前の関連するケース分析を組み合わせるのは非常に良いことだと思います。
あなたが学んだことを適用し、あなた自身の考えを持つことができます。
Recommended Posts