How to install MemSQL on Ubuntu 14.04
Introduction
MemSQL is a memory database that can provide faster read and write operations than traditional databases. Even if it is a new technology, it will say [MySQL] (https://cloud.tencent.com/product/cdb?from=10680) protocol, so it is very familiar to use.
MemSQL has adopted the latest and modern features of MySQL, such as JSON support and data insertion functions. One of the biggest advantages of MemSQL over MySQL is that it can split a single query across multiple nodes, called large-scale parallel processing, to achieve faster read queries.
In this tutorial, we will install MemSQL on a single Ubuntu 14.04 server, run performance benchmarks, and insert JSON data through the command line MySQL client.
prerequisites
To follow this tutorial, you need:
-
An Ubuntu 14.04 x64 Tencent CVM, at least 8 GB RAM, students who don’t have a server can buy it from here, but I personally recommend you to use the free Tencent Cloud [Developer Experiment] Room] (https://cloud.tencent.com/developer/labs?from=10680) to test, learn to install and then [buy server] (https://cloud.tencent.com/product/cvm?from=10680).
-
A non-root user with sudo privileges.
Step 1-Install MemSQL
In this section, we will prepare the working environment for the MemSQL installation.
The latest version of MemSQL is listed on its download page. We will download and install MemSQL Ops, a program that manages downloading and preparing the server to run MemSQL correctly. At the time of writing, the latest version of MemSQL Ops is 4.0.35.
First, download the MemSQL installation package file from their website.
wget http://download.memsql.com/memsql-ops-4.0.35/memsql-ops-4.0.35.tar.gz
Next, extract the package.
tar -xzf memsql-ops-4.0.35.tar.gz
The extraction package has created a folder named memsql-ops-4.0.35. Please note that the folder name has a version number, so if the version you download is lower than the version specified in this tutorial, you will have a folder containing the downloaded version.
Change directory to this folder.
cd memsql-ops-4.0.35
Then, run the installation script, which is part of the installation package we just extracted.
sudo ./install.sh
You will see some output from the script. After a while, it will ask you if you only want to install MemSQL on this host. We will introduce how to install MemSQL on multiple machines in a future tutorial. So, for the purpose of this tutorial, let's enter y to be affirmative.
...
Do you want to install MemSQL on this host only?[y/N] y
2015- 09- 0414:30:38: Jd0af3b [INFO] Deploying MemSQL to 45.55.146.81:33062015-09-0414:30:38: J4e047f [INFO] Deploying MemSQL to 45.55.146.81:33072015-09-0414:30:48: J4e047f [INFO] Downloading MemSQL:100.00%2015-09-0414:30:48: J4e047f [INFO] Installing MemSQL
2015- 09- 0414:30:49: Jd0af3b [INFO] Downloading MemSQL:100.00%2015-09-0414:30:49: Jd0af3b [INFO] Installing MemSQL
2015- 09- 0414:31:01: J4e047f [INFO] Finishing MemSQL Install
2015- 09- 0414:31:03: Jd0af3b [INFO] Finishing MemSQL Install
Waiting for MemSQL to start...
Now you have deployed a MemSQL cluster to your Ubuntu server! However, from the above log, you will notice that MemSQL has been installed twice.
MemSQL can run as two different roles: aggregator node and leaf node. The reason for installing MemSQL before is because it requires at least one aggregator node and at least one leaf node to run the cluster.
The aggregator is your interface MemSQL. To the outside world, it looks a lot like MySQL: it listens on the same port, and you can connect tools that expect to talk to MySQL and the standard MySQL library. The job of the aggregator is to understand all MemSQL leaf nodes, process the MySQL client, and convert its queries to MemSQL.
Aleaf node the actual data stored. When the leaf node receives a request to read or write data from the aggregator node, it executes the query and returns the result to the aggregator node. MemSQL allows you to share data across multiple hosts, each leaf node has a portion of the data. (Even if you use a single leaf node, your data will be split within that leaf node.)
When you have multiple leaf nodes, the aggregator is responsible for converting the MySQL query into all the leaf nodes that should be involved in the query. Then it receives the responses from all the leaf nodes and aggregates the results into a query that returns to the MySQL client. This is how to manage parallel queries.
Our single-host setup runs the aggregator and leaf nodes on the same machine, but you can add more leaf nodes on many other machines.
Step 2-Run the benchmark
Let's see that MemSQL can be quickly run by using the MemSQL Ops tool, which is installed as part of the MemSQL installation script.
In your web browser, go to http://your_server_ip:9000
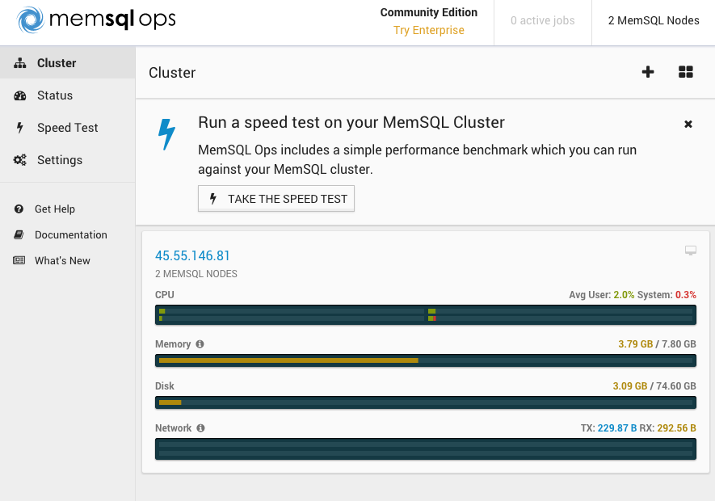
The MemSQL Ops tool provides you with an overview of the cluster. We have 2 MemSQL nodes: the main aggregator and leaf nodes.
Let's perform a speed test on a stand-alone MemSQL node. Click Speed Test in the left menu, and then click START TEST. The following are examples of results you might see:
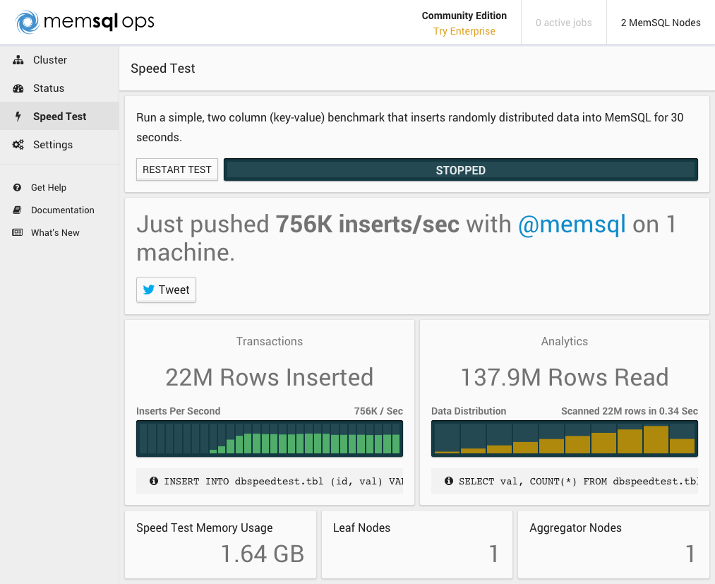
We will not cover how to install MemSQL across multiple servers in this tutorial, but for comparison, here is a benchmark test of a MemSQL cluster with three 8GB Ubuntu 14.04 nodes (one aggregator node and two leaf nodes):

By doubling the number of leaf nodes, we can almost double the insertion rate. By looking at the Rows Read section, we can see that our three-node cluster can simultaneously read 12M more rows than a single-node cluster in the same time.
Step 3-Interact with MemSQL through mysql-client
To the client, MemSQL looks like MySQL; they all have the same protocol. In order to start talking with our MemSQL cluster, let us first install a mysql-client.
First, update apt so that we can install the latest client in the next step.
sudo apt-get update
Now, install a MySQL client. This will give us a mysql execution command.
sudo apt-get install mysql-client-core-5.6
We are now ready to connect to MemSQL using the MySQL client. We will connect as the root user to the host 127.0.0.1 on port 3306 (this is our local host IP address). We will also customize the prompt message to memsql>.
mysql -u root -h 127.0.0.1-P 3306--prompt="memsql> "
You will see a memsql> prompt written after a few lines of output.
We list the databases.
show databases;
You will see this output.
+- - - - - - - - - - - - - - - - - - - - +| Database |+--------------------+| information_schema || memsql || sharding |+--------------------+3 rows inset(0.01 sec)
Create a new database named tutorial.
create database tutorial;
Then use the use command to switch to using the new database.
use tutorial;
Next, we will create a users table, which will have an id field and an email field. We must specify a type for these two fields. Let's set the id to bigint and send a varchar of length 255 via email. We will also tell the database that the id field is the primary key, and the email field cannot be empty.
create table users(id bigint auto_increment primary key, email varchar(255) not null);
You may notice that the execution time of the last command is very short (15-20 seconds). There is one main reason for the speed at which MemSQL creates this new table: code generation.
Under the hood, MemSQL uses code generation to execute queries. This means that whenever a new type of query is encountered, MemSQL needs to generate and compile code representing the query. Then send this code to the cluster for execution. This speeds up the processing of actual data, but the preparation cost is high. MemSQL does its best to reuse pre-generated queries, but new queries that have never seen a structure will slow down.
Go back to our user table and look at the table definition.
describe users;
+- - - - - - - +- - - - - - - - - - - - - - +- - - - - - +- - - - - - +- - - - - - - - - +- - - - - - - - - - - - - - - - +| Field | Type | Null | Key | Default | Extra |+-------+--------------+------+------+---------+----------------+| id |bigint(20)| NO | PRI | NULL | auto_increment || email |varchar(255)| NO || NULL ||+-------+--------------+------+------+---------+----------------+2 rows inset(0.00 sec)
Now, let's insert some sample emails in the users table. This syntax is the same as we might use for MySQL databases.
insert into users(email)values('[email protected]'),('[email protected]'),('[email protected]');
Query OK,3 rows affected(1.57 sec)
Records:3 Duplicates:0 Warnings:0
Now query the users table.
select *from users;
You can see the data we just entered:
+- - - - +- - - - - - - - - - - - - - - - - - - +| id | email |+----+-------------------+|2| [email protected] ||1| [email protected] ||3| [email protected] |+----+-------------------+3 rows inset(0.07 sec)
Step 4-Insert and query JSON
MemSQL provides the JSON type, so in this step, we will create an event table to use incoming events. The table will contain an id field (just like we did for users) and an event field, which will be a JSON type.
create table events(id bigint auto_increment primary key, event json not null);
Let's insert a few events. In JSON, we will refer to an email field, which in turn refers back to the user ID that we inserted in step 3.
insert into events(event)values('{"name": "sent email", "email": "[email protected]"}'),('{"name": "received email", "email": "[email protected]"}');
Now we can look at the event we just inserted.
select *from events;
+- - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | event |+----+-----------------------------------------------------+|2|{"email":"[email protected]","name":"received email"}||1|{"email":"[email protected]","name":"sent email"}|+----+-----------------------------------------------------+2 rows inset(3.46 sec)
Next, we can query all events whose JSON name attribute is the text "email received".
select *from events where event::$name ='received email';
+- - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | event |+----+-----------------------------------------------------+|2|{"email":"[email protected]","name":"received email"}|+----+-----------------------------------------------------+1 row inset(5.84 sec)
Try to change the query to find a query with the text "email sent" in the name attribute.
select *from events where event::$name ='sent email';
+- - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | event |+----+-------------------------------------------------+|1|{"email":"[email protected]","name":"sent email"}|+----+-------------------------------------------------+1 row inset(0.00 sec)
This latest query runs much faster than the previous query. This is because we only changed the parameters in the query, so MemSQL can skip code generation.
Let's do some advanced operations for a distributed SQL database: Let's join two tables on a non-primary key, where one join value is nested in a JSON value, but filter different JSON values.
First, we will request all fields of the user table to be added to the event table by matching the email with the event name "received email".
select *from users left join events on users.email = events.event::$email where events.event::$name ='received email';
+- - - - +- - - - - - - - - - - - - - - - - +- - - - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | email | id | event |+----+-----------------+------+-----------------------------------------------------+|2| [email protected] |2|{"email":"[email protected]","name":"received email"}|+----+-----------------+------+-----------------------------------------------------+1 row inset(14.19 sec)
Next, try the same query, but only filter to the "email sent" event.
select *from users left join events on users.email = events.event::$email where events.event::$name ='sent email';
+- - - - +- - - - - - - - - - - - - - - - - +- - - - - - +- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +| id | email | id | event |+----+-----------------+------+-------------------------------------------------+|1| [email protected] |1|{"email":"[email protected]","name":"sent email"}|+----+-----------------+------+-------------------------------------------------+1 row inset(0.01 sec)
As before, the second query is much faster than the first. As we saw in the benchmark test, the benefits of code generation paid off when executing millions of lines. The flexibility to use a horizontally scalable SQL database that understands JSON and how to connect arbitrarily between tables is a powerful user feature.
in conclusion
You have installed MemSQL, run benchmark tests of node performance, interact with your node through a standard MySQL client, and use some advanced features not available in MySQL. This should give a good idea of what an in-memory SQL database can do for you.
There is still a lot to understand how MemSQL actually distributes your data, how to build tables for optimal performance, how to scale MemSQL across multiple nodes, how to replicate data for high availability, and how to protect MemSQL.
For more Ubuntu tutorials, please go to [Tencent Cloud + Community] (https://cloud.tencent.com/developer?from=10680) to learn more.
Reference: "How to Install MemSQL on Ubuntu 14.04"
Recommended Posts