Python regular expression example code
The re module makes the Python language have all the regular expression functions.
Syntax that will be used
| Regular characters | Interpretation | Example |
|---|---|---|
| + | The previous element appears at least once | ab+: ab, abbbb, etc. |
| * | The preceding element appears 0 or more times | ab*: a, ab, abb, etc. |
| ? | Match the previous one or 0 times | Ab?: A, Ab, etc. |
| ^ | As the start tag | ^a: abc, aaaaaa, etc. |
| $ | as the end tag | c$: abc, cccc, etc. |
| \ d | Number | 3, 4, 9 and other regular character interpretation examples + the preceding element appears at least once ab+: ab, abbbb, etc. The preceding element appears 0 or more times ab: a, ab, abb, etc.? Match the preceding one or 0 Ab?: A, Ab, etc.^ as the start tag ^a: abc, aaaaaa, etc. $ as the end tag c$: abc, cccc, etc. \d number 3, 4, 9 etc.\D non-number A, a,-etc. [az]Any letter a, p, m, etc. between A and z [0-9] Any number 0, 2, 9, etc. between 0 and 9 |
| Regular characters | Interpretation | Example |
| + | The previous element appears at least once | ab+: ab, abbbb, etc. |
| * | The preceding element appears 0 or more times | ab*: a, ab, abb, etc. |
| ? | Match the previous one or 0 times | Ab?: A, Ab, etc. |
| ^ | As the start tag | ^a: abc, aaaaaa, etc. |
| $ | as the end tag | c$: abc, cccc, etc. |
| \ d | Numbers | 3, 4, 9, etc. |
| \ D | Non-number | A, a,-etc. |
| [ az] | Any letter between A and z | a, p, m, etc. |
| [0- 9] | 0 Any number from to 9 | 0, 2, 9, etc. |
| \ D | Non-number | A, a,-etc. |
| [ az] | Any letter between A and z | a, p, m, etc. |
| [0- 9] | 0 Any number from to 9 | 0, 2, 9, etc. |
note:
- Escape character
s
'( abc)def'
m = re.search("(\(.*\)).*", s)
print m.group(1)(abc)
re.match function
re.match tries to match a pattern from the beginning of the string. If the match is not successful at the beginning, match() returns none.
Example 1:
#! /usr/bin/python
# - *- coding: UTF-8-*-import re
print(re.match('www','www.zalou.cn').span()) #Match at the start
print(re.match('net','www.zalou.cn')) #Does not match at the beginning
Output result:
(0, 3)
None
Example 2:
#! /usr/bin/python
import re
line ="Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)else:
print "No match!!"
Output result:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
The above is the print output of python2. Just remember to add () in python, and the output of python is similar to the \n in other languages to match the obtained content.
python group()
In regular expressions, group() is used to propose the string intercepted by grouping, and () is used to group
Repeat the previous string multiple times
a ="kdlal123dk345"
b ="kdlal123345"
m = re.search("([0-9]+(dk){0,1})[0-9]+", a)
m.group(1), m.group(2)('123dk','dk')
m = re.search("([0-9]+(dk){0,1})[0-9]+", b)
m.group(1)'12334'
m.group(2)
The reason
- The three sets of brackets in the regular expression divide the matching results into three groups
group() is the same as group(0) to match the overall result of the regular expression
group(1) lists the first bracket matching part, group(2) lists the second bracket matching part, group(3) lists the third bracket matching part.
2. If there is no successful match, re.search() returns None
- Of course, there are no parentheses in the regular expression, and group(1) is definitely wrong.
Example
- Determine whether the string is all lowercase
# - *- coding: cp936 -*-import re
s1 ='adkkdk'
s2 ='abc123efg'
an = re.search('^[a-z]+$', s1)if an:
print 's1:', an.group(),'All lowercase'else:
print s1,"Not all lowercase!"
an = re.match('[a-z]+$', s2)if an:
print 's2:', an.group(),'All lowercase'else:
print s2,"Not all lowercase!"
result

The reason
-
Regular expressions are not part of python, you need to quote the re module when using
-
The matching form is: re.search (regular expression, with matching string) or re.match (regular expression, with matching string). The difference between the two is that the latter starts with a start character (^) by default. therefore,
re.search('[1]+′,s1) is equivalent to re.match('[a−z]+', s2)
- If the match fails, an = re.search('[2]+$', s1) returns None
group is used to group matching results
E.g
import re
a ="123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,Back to the whole
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
Output result
123 abc456
123
abc
456
1 ) The three sets of parentheses in the regular expression divide the matching results into three groups
group() is the same as group(0) to match the overall result of the regular expression
group(1) lists the first bracket matching part, group(2) lists the second bracket matching part, group(3) lists the third bracket matching part.
2 ) If there is no match, re.search() returns None
3 ) Of course, there are no parentheses in the regular expression, and group(1) is definitely wrong.
2. Acronym expansion
Concrete example
FEMA Federal Emergency Management Agency
IRA Irish Republican Army
DUP Democratic Unionist Party
FDA Food and Drug Administration
OLC Office of Legal Counsel
analysis
Abbreviation FEMA
Decomposed into F*** E*** M*** A***
Regular uppercase letters + lowercase (more than or equal to 1) + spaces
Reference Code
import re
def expand_abbr(sen, abbr):
lenabbr =len(abbr)
ma =''for i inrange(0, lenabbr):
ma += abbr[i]+"[a-z]+"+' '
print 'ma:', ma
ma = ma.strip(' ')
p = re.search(ma, sen)if p:return p.group()else:return''
print expand_abbr("Welcome to Algriculture Bank China",'ABC')
result

problem
The above code is correct for the first 3 in the example, but the latter two are wrong, because the words beginning with capital letters are also mixed with lowercase letters.
law
Uppercase letter + lowercase (more than or equal to 1) + space + [lower case + space] (0次或1次)
Reference Code
import re
def expand_abbr(sen, abbr):
lenabbr =len(abbr)
ma =''for i inrange(0, lenabbr-1):
ma += abbr[i]+"[a-z]+"+' '+'([a-z]+ )?'
ma += abbr[lenabbr-1]+"[a-z]+"
print 'ma:', ma
ma = ma.strip(' ')
p = re.search(ma, sen)if p:return p.group()else:return''
print expand_abbr("Welcome to Algriculture Bank of China",'ABC')
skill
The set of lowercase letters in the middle + a space, as a whole, add parentheses. Either at the same time or not at the same time, so need to use it? , To match the whole ahead.
3. Remove the comma in the number
Concrete example
When dealing with natural language, if 123,000,000 is divided by punctuation, there will be a problem. A good number is dismembered by a comma, so you can deal with the number first (remove the comma).
analysis
The number is often a group of 3 numbers, followed by a comma, so the rule is: ***, ***, ***
Regular expression
[ a-z]+,[a-z]?
Reference code 3-1
import re
sen ="abc,123,456,789,mnp"
p = re.compile("\d+,\d+?")for com in p.finditer(sen):
mm = com.group()
print "hi:", mm
print "sen_before:", sen
sen = sen.replace(mm, mm.replace(",",""))
print "sen_back:", sen,'\n'
result

skill
Use the function finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
Search for string and return an iterator that sequentially accesses each match result (Match object).
Reference code 3-2
sen ="abc,123,456,789,mnp"while1:
mm = re.search("\d,\d", sen)if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",",""))
print sen
else:break
result
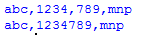
extend
Such a program is aimed at a specific problem, that is, a group of 3 digits. If the numbers are mixed with letters, eliminate the commas between the numbers, that is, convert "abc,123,4,789,mnp" into "abc,1234789,mnp"
Ideas
More specifically, find the regular expression "number, number" and replace it with the comma removed
Reference code 3-3
sen ="abc,123,4,789,mnp"while1:
mm = re.search("\d,\d", sen)if mm:
mm = mm.group()
sen = sen.replace(mm, mm.replace(",",""))
print sen
else:break
print sen
result

4. Year conversion for Chinese processing (for example: 1949-1949)
Chinese processing involves coding issues. For example, when the program below recognizes the year (****year)
# - *- coding: cp936 -*-import re
m0 ="New China was founded in 1949"
m1 ="5.2% lower than in 1990"
m2 ='Man defeated the Russian army in 1996,Achieved substantial independence'
def fuc(m):
a = re.findall("[zero|One|two|three|four|Fives|six|Seven|Eight|nine]+year", m)if a:for key in a:
print key
else:
print "NULL"fuc(m0)fuc(m1)fuc(m2)
operation result

It can be seen that there are errors in the second and third.
Improvement-standardization into unicode recognition
# - *- coding: cp936 -*-import re
m0 ="New China was founded in 1949"
m1 ="5.2% lower than in 1990"
m2 ='Man defeated the Russian army in 1996,Achieved substantial independence'
def fuc(m):
m = m.decode('cp936')
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", m)if a:for key in a:
print key
else:
print "NULL"fuc(m0)fuc(m1)fuc(m2)
result

It can be recognized by replacing Chinese characters with numbers.
reference
numHash ={}
numHash['zero'.decode('utf-8')]='0'
numHash['One'.decode('utf-8')]='1'
numHash['two'.decode('utf-8')]='2'
numHash['three'.decode('utf-8')]='3'
numHash['four'.decode('utf-8')]='4'
numHash['Fives'.decode('utf-8')]='5'
numHash['six'.decode('utf-8')]='6'
numHash['Seven'.decode('utf-8')]='7'
numHash['Eight'.decode('utf-8')]='8'
numHash['nine'.decode('utf-8')]='9'
def change2num(words):
print "words:",words
newword =''for key in words:
print key
if key in numHash:
newword += numHash[key]else:
newword += key
return newword
def Chi2Num(line):
a = re.findall(u"[\u96f6|\u4e00|\u4e8c|\u4e09|\u56db|\u4e94|\u516d|\u4e03|\u516b|\u4e5d]+\u5e74", line)if a:
print "------"
print line
for words in a:
newwords =change2num(words)
print words
print newwords
line = line.replace(words, newwords)return line
5. Multiple mobile phone numbers, separated by |
For example:
Null value
12222222222
12222222222|12222222222
12222222222|12222222222|12222222444
expression
s = “[\d]{11}(\|[\d]{11})*|”
4. Recommended
Python regular expression guide
So far this article about python regular expression example code is introduced. For more relevant python regular expression example content, please search for previous articles on ZaLou.Cn or continue to browse related articles below. Hope you will support ZaLou.Cn more in the future!
Recommended Posts