Deep understanding of Python multithreading
Multithreading in Python is a fake multithreading. No matter how many cores there are, only one core can be operated at a time! Utilizing Python's multithreading is just taking advantage of CPU context switching. It looks like concurrency, but it is actually a single thread, so it is a fake single thread.
**So when do you use multithreading? **
The first thing to know:
- io operation does not occupy CPU
- Calculation operations occupy CPU, like 2+5=5
Python's multithreading is not suitable for CPU-intensive operations, but for io-intensive tasks, such as SocketServer
**What if there are more CPU-intensive tasks now? **
First of all, the processes of multi-process are independent, and then note that the threads of python use the native threads of the system, and the processes of python also use the native processes of the system. The native processes are maintained by the operating system. To put it bluntly Python just uses the interface of the C native code library to start a process. The real process management is still done by the operating system. Does the operating system itself have a GIL global interpreter lock? The answer is no, and one of the two processes The data between each other is completely independent and cannot access each other, so the concept of lock is not needed, so there is no concept of GIL, so in this case, each process will have at least one thread. If my operating system is now eight cores Yes, I started eight processes, and then each process has a thread, then it is equivalent to eight threads, eight threads running on eight cores, then it is equivalent to using multiple cores, then the problem is solved!
The only disadvantage is that the data between the eight threads cannot be shared, independent! Using this method can compromise the problem of multi-core computing!
First look at a simple multi-process program:
import multiprocessing
import time
def run(name):
time.sleep(2)print('hello', name)if __name__ =='__main__':for i inrange(10):
p = multiprocessing.Process(target=run, args=('bob%s'%i,))
p.start()
The execution result of the program is:
hello bob0
hello bob1
hello bob3
hello bob2
hello bob5
hello bob9
hello bob7
hello bob8
hello bob4
hello bob6
**So, if I want to get my process ID, how should I get it? **
from multiprocessing import Process
import os
def info(title):print(title)print('module name:', __name__)print('parent process:', os.getppid()) #Parent process ID
print('process id:', os.getpid()) #ID of own process
print("\n\n")
def f(name):info('3[31;1mfunction f3[0m')print('hello', name)if __name__ =='__main__':info('3[32;1mmain process line3[0m')
p =Process(target=f, args=('bob',))
p.start()
p.join()
The result of program execution is:
main process line
module name: main
parent process: 5252
process id: 6576
function f
module name: mp_main
parent process: 6576
process id: 2232
hello bob
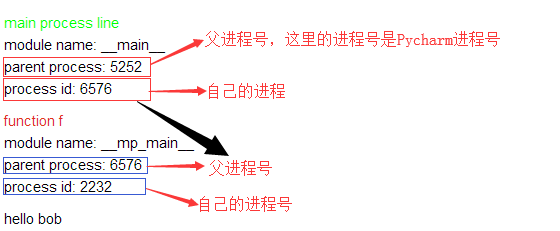
In fact, this picture means that every child process is started by his parent process.
Inter-process communication
We say that the memory between the two processes is independent of each other, so can the two processes communicate? Say process A accesses the data of process B, can you access it? It is definitely not accessible! However, I just want to access, that is, two independent memories want to access each other, so what should I do?
There are so many ways, but yes! Invariably, it means that you have to find a middleware. There are so many kinds of middleware, so let’s take a look at which ones first
The first type of Queues
The usage is similar to the queue in threading
from multiprocessing import Process, Queue
def f(q):
q.put([42, None,'hello'])if __name__ =='__main__':
q =Queue()
p =Process(target=f, args=(q,))
p.start()print(q.get()) # prints "[42, None, 'hello']"
p.join()
Let’s look at these two processes. How does the q of the parent process pass to the child process? Let's discuss
Now, do we think that the data is shared, two processes share a q, in fact it is not, it is equivalent to clone a q, and then create a child process in the parent process, that is, the parent process clones its own q The copy is handed over to the child process, and the child process puts a piece of data into this q at this time, and the parent process can obtain it. Then it’s not right to say that. Then clone a q, that is, two qs, B puts a data in q, then it has nothing to do with another q, that is, A’s q, ah, it’s supposed to be this Looks like, but in fact, does it want to share data? It is equivalent to serializing the data in A and q, and serializing it to an intermediate position, and there is a translation in the intermediate position. This data is deserialized to A and placed in A's q, then the so-called data sharing is realized.
The result of program execution is:
[42, None, ‘hello’]
The second kind of Pipes
The Pipe() function returns a connection object connected by a pipe, which is duplex (bidirectional) by default. E.g:
from multiprocessing import Process, Pipe
def f(conn):
conn.send("Father, how are you doing?") #Son sent
print("son receive:",conn.recv())
conn.close()if __name__ =='__main__':
parent_conn, child_conn =Pipe()
p =Process(target=f, args=(child_conn,))
p.start()print("father receive:",parent_conn.recv()) #Father receives
parent_conn.send("Son, how are you doing?")
p.join()
The result of the program execution is:
father receive: Father, how are you?
son receive: Son, how are you doing?
The two connection objects returned by Pipe() represent the two ends of the pipe. Each connection object has send() and recv() methods (and other methods). Note that if two processes (or threads) try to read or write to the same end of the pipe at the same time, the data in the pipe may be corrupted. Of course, there is no risk of damage in the process of using different ends of the pipe at the same time.
The third type of Managers
The manager object returned by Manager() controls a server process that saves Python objects and allows other processes to manipulate them using agents.
The manager returned by Manager() will support the type list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array. E.g,
from multiprocessing import Process, Manager
import os
def f(d, l):
d[1]='1'
d['2']=2
d[0.25]= None
l.append(os.getpid())print(l)if __name__ =='__main__':withManager()as manager:
d = manager.dict() #Use a special syntax to generate a dictionary that can be passed and shared between multiple processes
l = manager.list(range(5)) # #Use a special syntax to generate a list that can be passed and shared between multiple processes. There are 5 data in the default
p_list =[]for i inrange(10):
p =Process(target=f, args=(d, l))
p.start()
p_list.append(p)for res in p_list:
res.join()print(d)print(l)
The result of program execution is:
[0, 1, 2, 3, 4, 2100]
[0, 1, 2, 3, 4, 2100, 7632]
[0, 1, 2, 3, 4, 2100, 7632, 5788]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904, 7888]
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904, 7888, 7612]
{1: ‘1’, ‘2’: 2, 0.25: None}
[0, 1, 2, 3, 4, 2100, 7632, 5788, 6340, 5760, 7072, 7540, 3904, 7888, 7612]
Process lock and process pool
Process lock
The process also has a lock, what? Aren't the processes all independent? Doesn't involve modifying the same data at the same time, how can there be a lock?
Let’s take a look at its appearance, it’s almost exactly the same as the thread
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()try:print('hello world', i)finally:
l.release()if __name__ =='__main__':
lock =Lock()for num inrange(10):Process(target=f, args=(lock, num)).start()
The result of program execution is:
hello world 3
hello world 1
hello world 2
hello world 5
hello world 7
hello world 4
hello world 0
hello world 6
hello world 8
hello world 9
So what does this lock do?
The function is actually to prevent the information printed on the screen from being confused!
Process pool
In the above program, starting 100 processes will be slower, because starting a process is quite a clone of the memory data of the parent process, if the parent process occupies a G of memory space, then I start 100 processes, just It is equivalent to 101G. In this case, the overhead is very large. It is like starting a process and cloning a house, which will fill up Harbin in a while, so the overhead is extremely large. In order to avoid the 咵嚓. Many processes will bring down the system, so there is a limit to the process pool.
The process pool is how many processes are running on the CPU at the same time.
There are two methods in the process pool:
- apply (synchronous execution, serial)
- apply_async (asynchronous execution, parallel)
from multiprocessing import Process,Pool,freeze_support
import time
import os
def Foo(i):
time.sleep(2)print("in process",os.getpid())return i+100
def Bar(arg):print('-- exec done:',arg)if __name__ =='__main__':freeze_support()
pool =Pool(5) #Allow 5 processes to be placed in the process pool at the same time
for i inrange(10):
# pool.apply_async(func=Foo, args=(i,),callback=Bar) #callback
pool.apply(func=Foo, args=(i,)) #Serial
# pool.apply_async(func=Foo, args=(i,)) #parallel
print('end')
pool.close()
pool.join() #The process in the process pool is closed after the execution is completed. If you comment, the program is closed directly.
The execution result of the program is:
in process 7824
in process 6540
in process 7724
in process 8924
in process 9108
in process 7824
in process 6540
**Knowledge point expansion: **
__ The function of name__ =='main' is:
Manually execute the program about this code, then the program below it will be executed, if it is a program that calls this code, then the program below it will not be executed
The above is an in-depth understanding of the details of Python multithreading. For more information about Python multithreading, please pay attention to other related articles on ZaLou.Cn!
Recommended Posts