CentOS6.5 install CDH5.13
Reminder: To see the high-definition uncoded set of pictures, please use your mobile phone to open and click the picture to enlarge it.
1. Document writing purpose
Cloudera released the CDH5.13 version some time ago. For the new features of 5.13, please refer to the previous article New features of CDH5.13 and CM5.13. This article mainly describes how to install CDH5.13 on CentOS6.5 For the preparation of cluster installation, you can refer to the previous article [Preparation for CDH Installation] (https://cloud.tencent.com/developer/article/1078212?from=10680), **Please ensure that you have read it carefully before installation Preparation for CDH Installation, and Prepared according to the document, including basic environment preparation related such as yum source, ntp configuration, etc. **
- Content overview
-
Precondition preparation
-
Cloudera Manager installation
-
CDH installation
-
Kudu installation
-
Component verification
- test environment
-
CentOS6.5
-
Use root user operation
- precondition
-
CM and CDH version is 5.13
-
The CM and CDH installation packages have been downloaded
2. Install Cloudera Manager Server
- Use the following command to install Cloudera Manager Server service on the CM node
root@ip-172-31-6-148~# yum -y install cloudera-manager-server

- Initialize the CM database
[ root@ip-172-31-6-148~]#/usr/share/cmf/schema/scm_prepare_database.sh mysql cm cm password
JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera
Verifying that we can write to /etc/cloudera-scm-server
Creating SCM configuration file in/etc/cloudera-scm-server
Executing:/usr/java/jdk1.7.0_67-cloudera/bin/java-cp/usr/share/java/mysql-connector-java.jar:/usr/share/java/oracle-connector-java.jar:/usr/share/cmf/schema/../lib/*com.cloudera.enterprise.dbutil.DbCommandExecutor/etc/cloudera-scm-server/db.properties com.cloudera.cmf.db.
log4j:ERRORCould not find value for keylog4j.appender.A
log4j:ERRORCould not instantiate appender named "A".
[2017- 10- 1517:49:38,476] INFO 0[main] -com.cloudera.enterprise.dbutil.DbCommandExecutor.testDbConnection(DbCommandExecutor.java) - Successfullyconnected to database.
All done, your SCM database is configured correctly!
[ root@ip-172-31-6-148~]#

- Start Cloudera Manager Server
root@ip-172-31-6-148~# service cloudera-scm-server start
Starting cloudera-scm-server: [ OK ]
root@ip-172-31-6-148~#

- Check if the port is listening
root@ip-172-31-6-148~# netstat -apn |grep 7180
tcp 0 0 0.0.0.0:7180 0.0.0.0:* LISTEN 20963/java
root@ip-172-31-6-148~#

- Visit CM via http:// 172.31.2.159:7180/cmf/login

3. CDH installation
3.1 CDH cluster installation wizard
-
Log in to Cloudera Manager to enter the web installation wizard interface
-
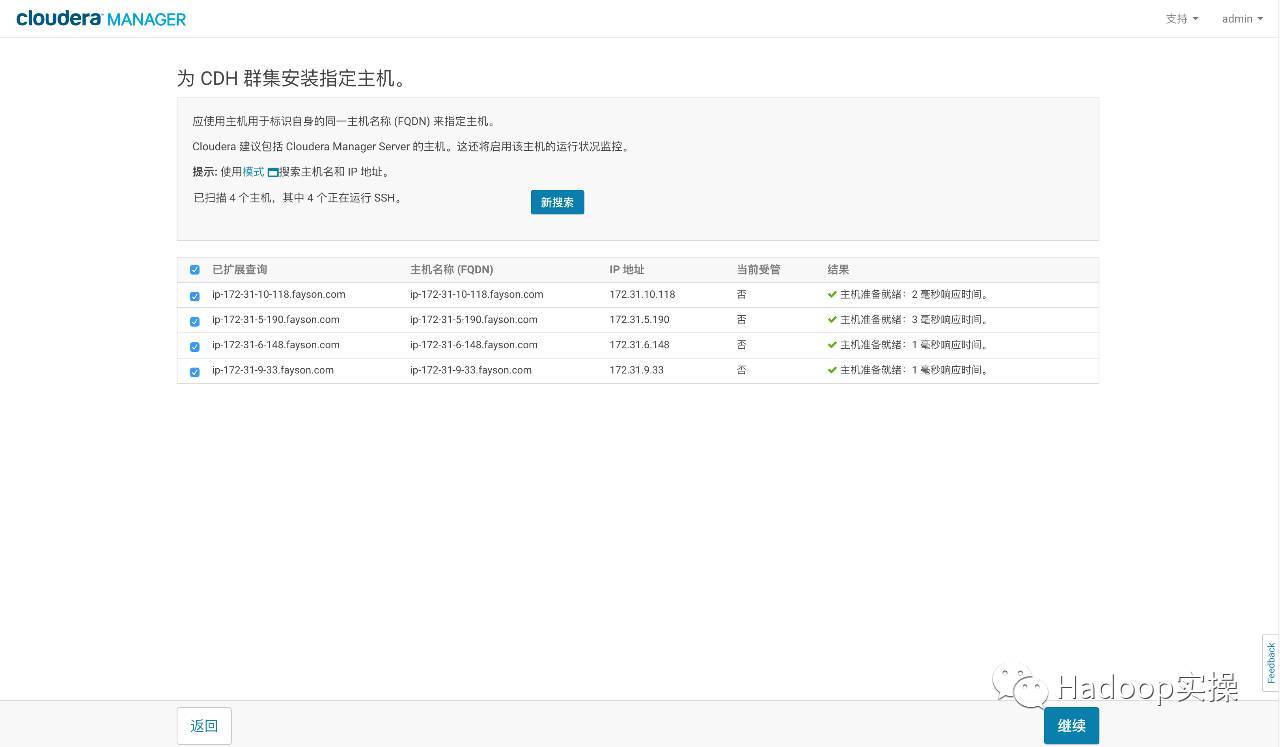
Specify the cluster installation host
- Set the Parcel address of CDH

- Set CM repository address

- Cluster installation JDK option

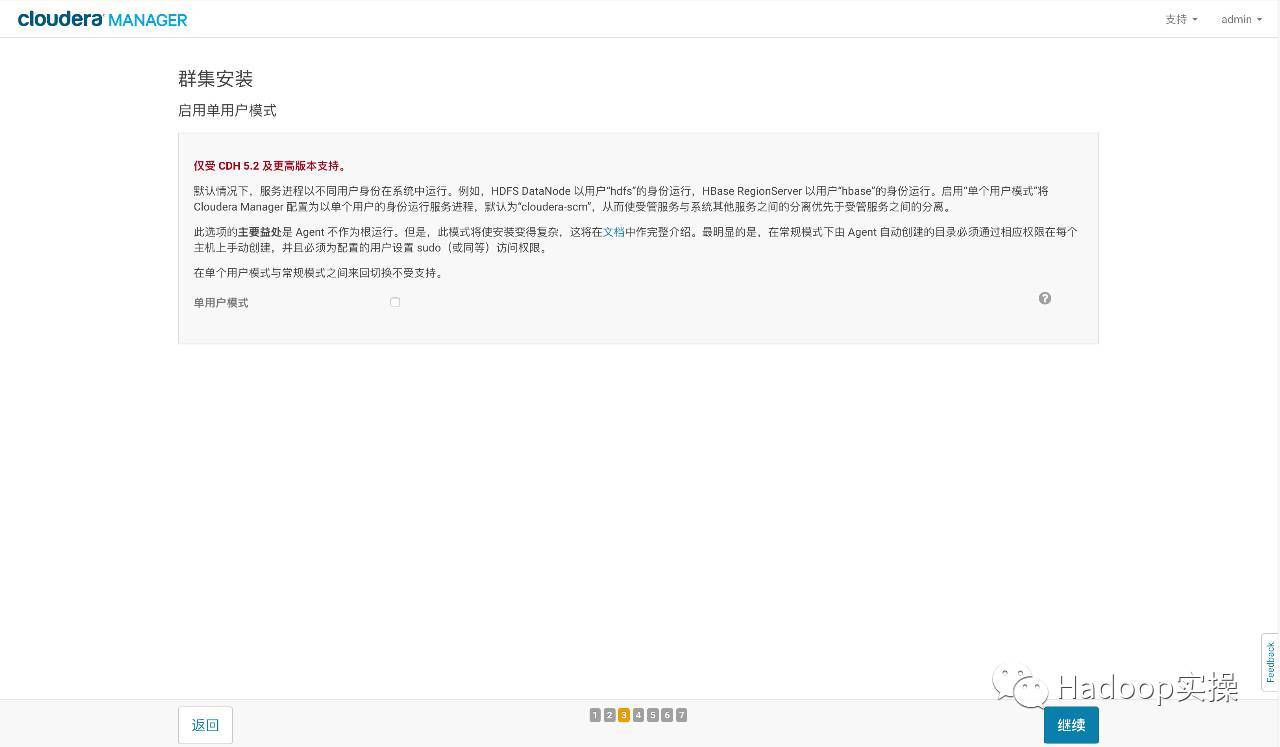
- Cluster installation mode
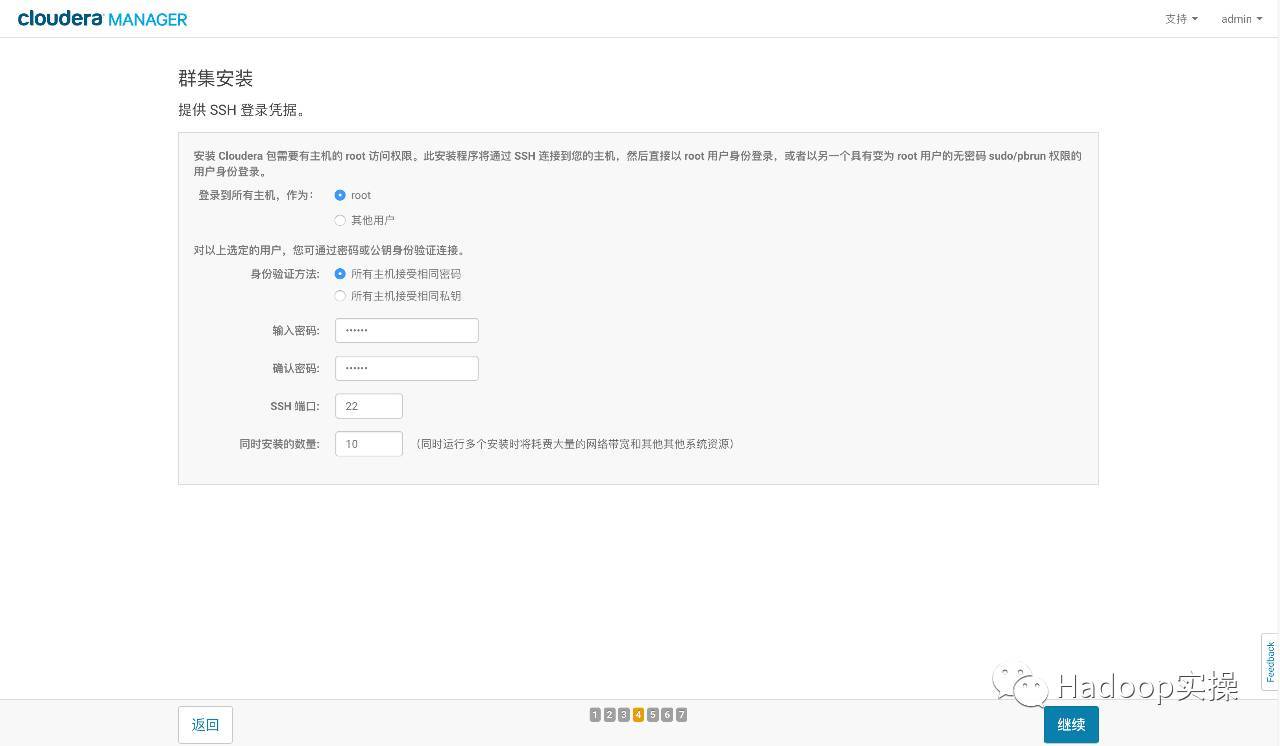
- Enter cluster SSH login information
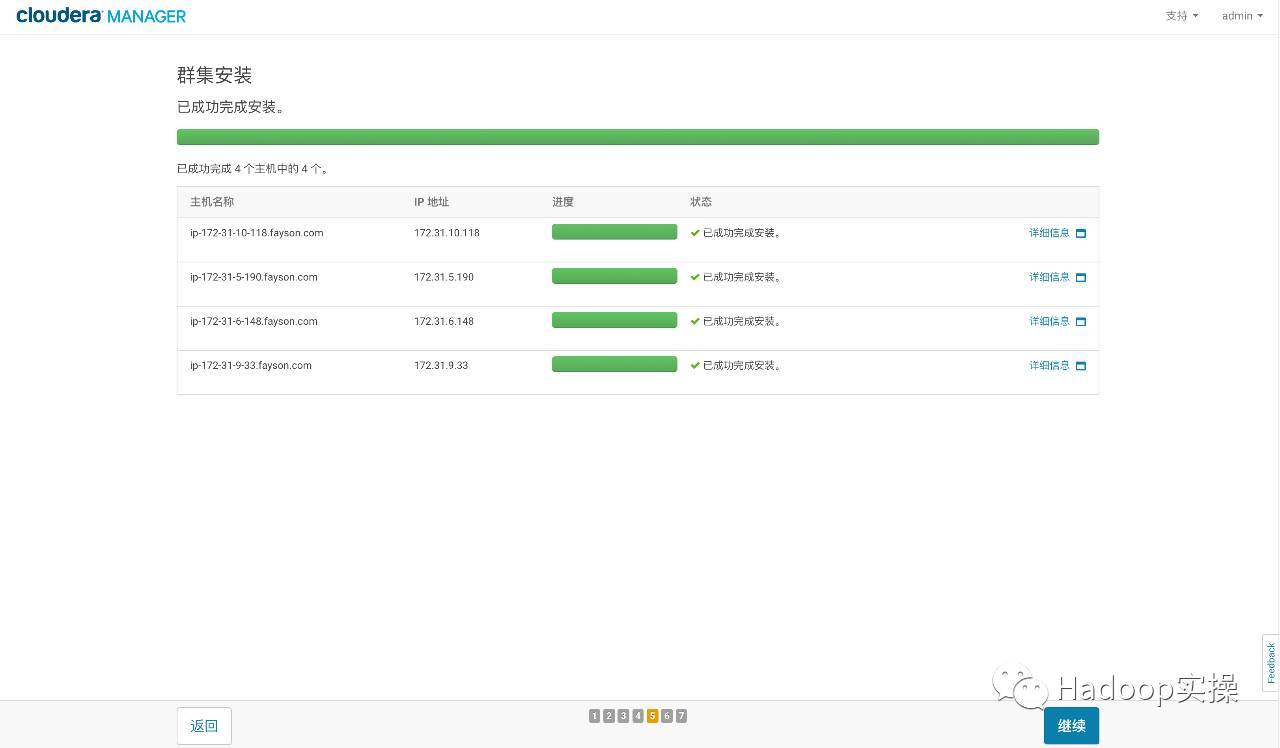
- Cluster installation of JDK and Cloudera Manager Aagent service
- Install and activate Parcel to all hosts in the cluster
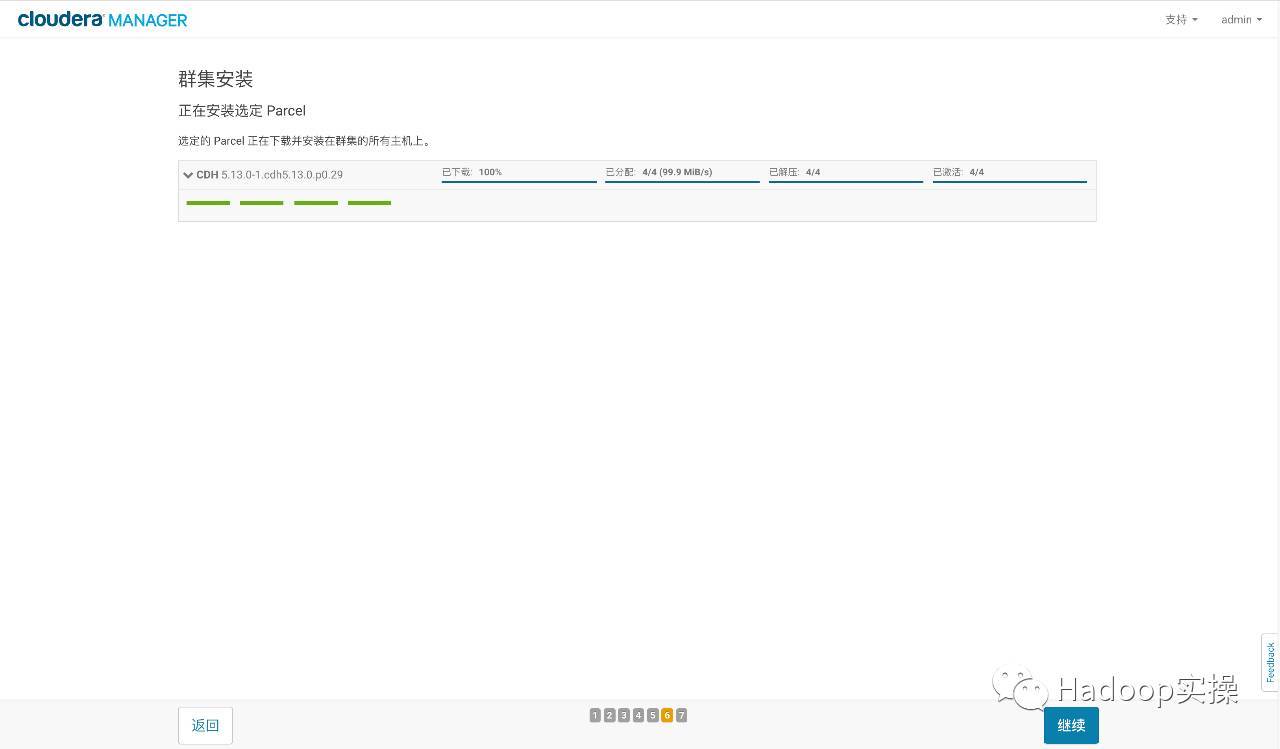
- Check the correctness of the host

3.2 CDH cluster setup wizard
- Set the service portfolio for cluster installation

- Custom role assignment
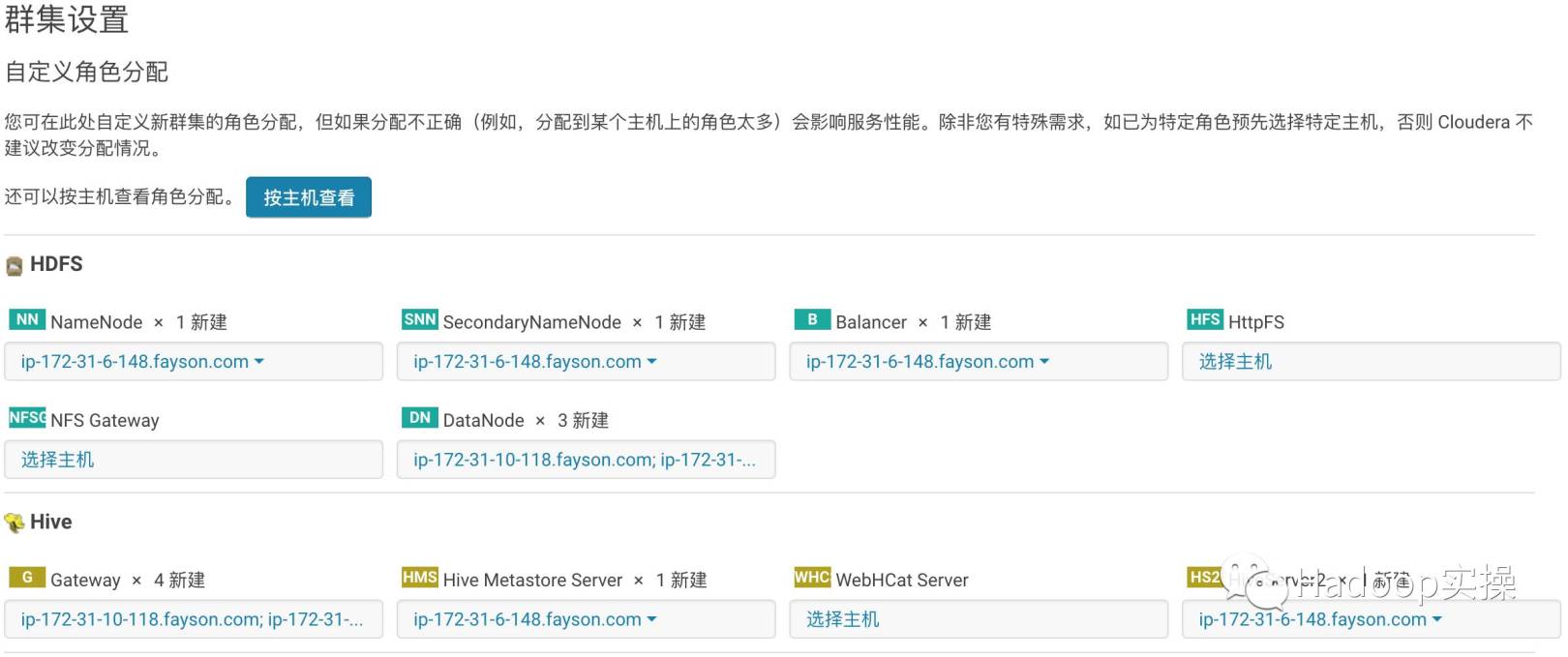
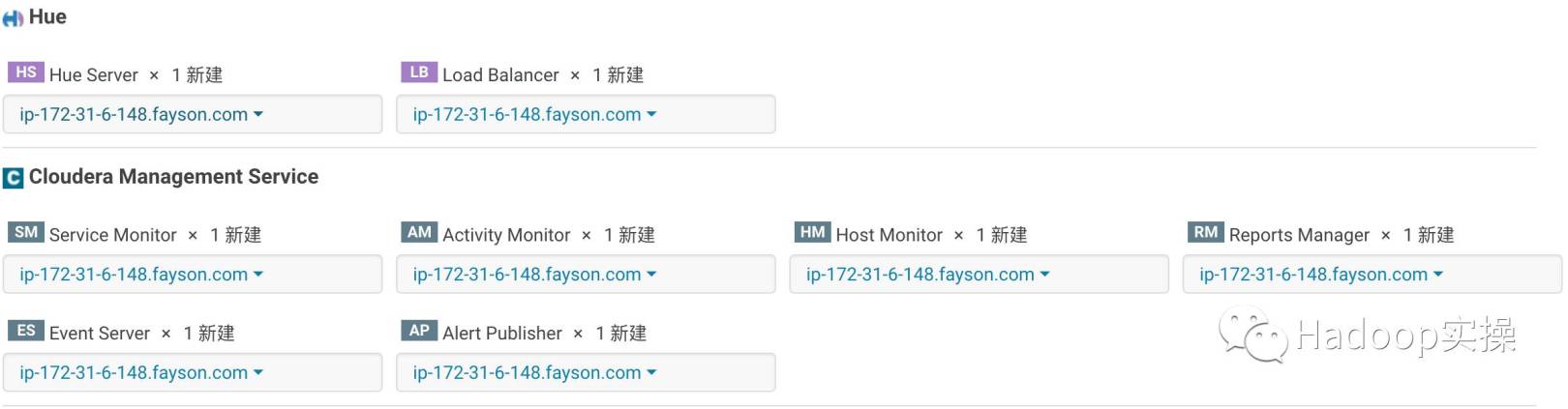
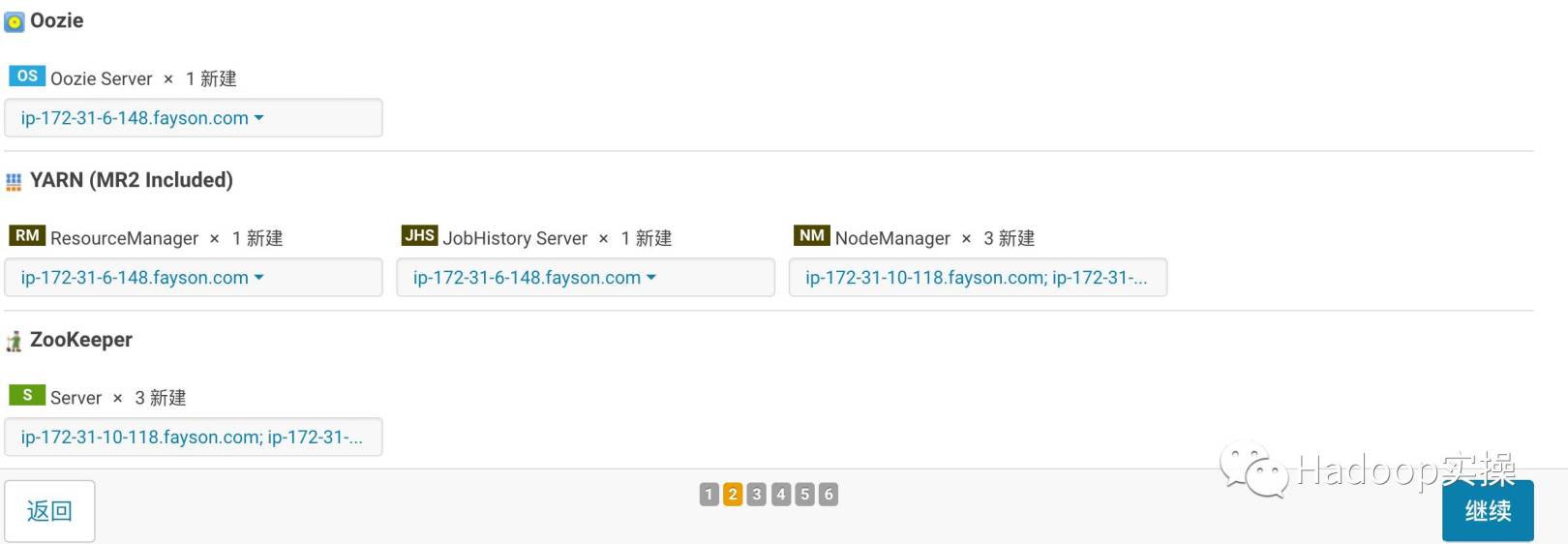
- Database settings
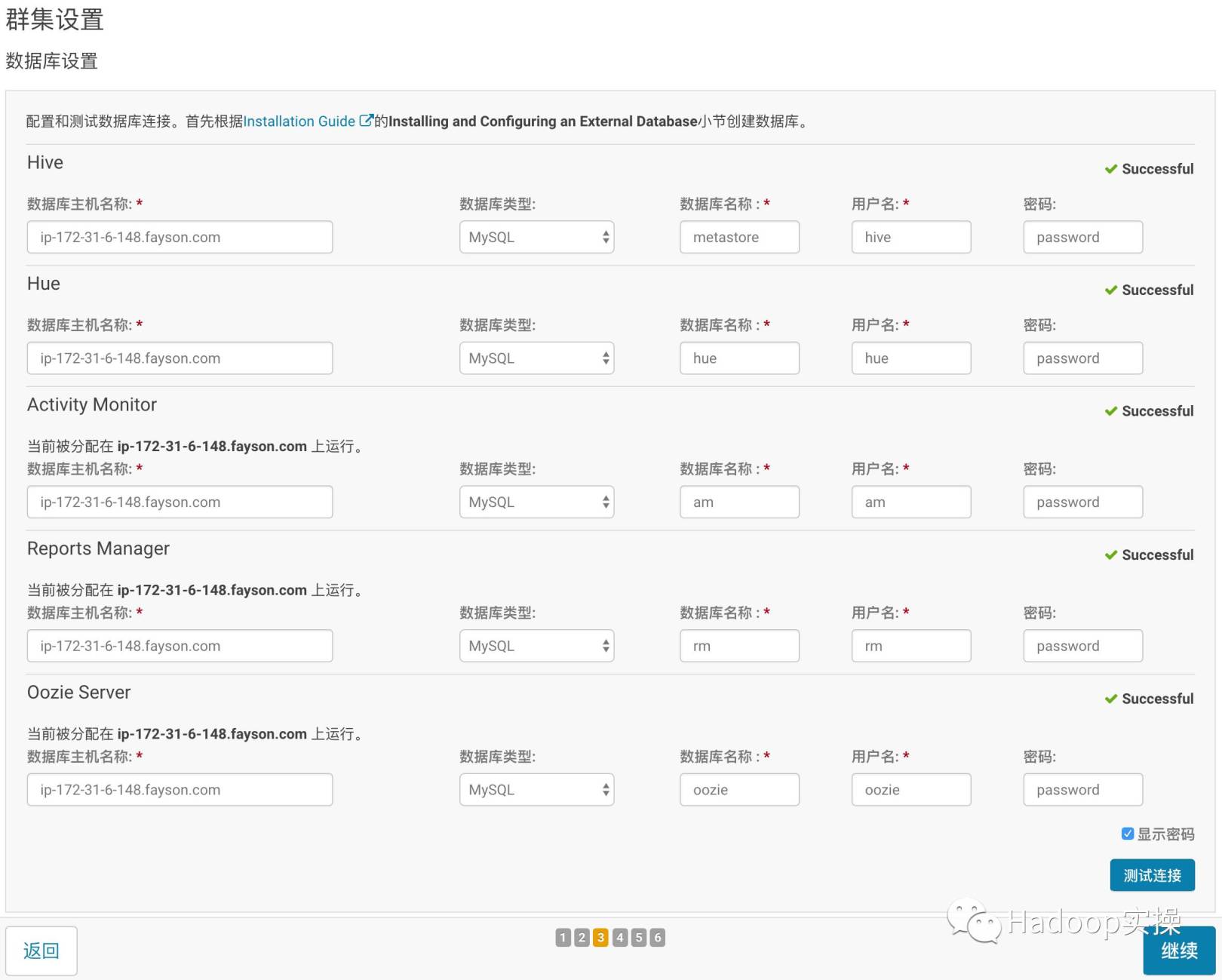
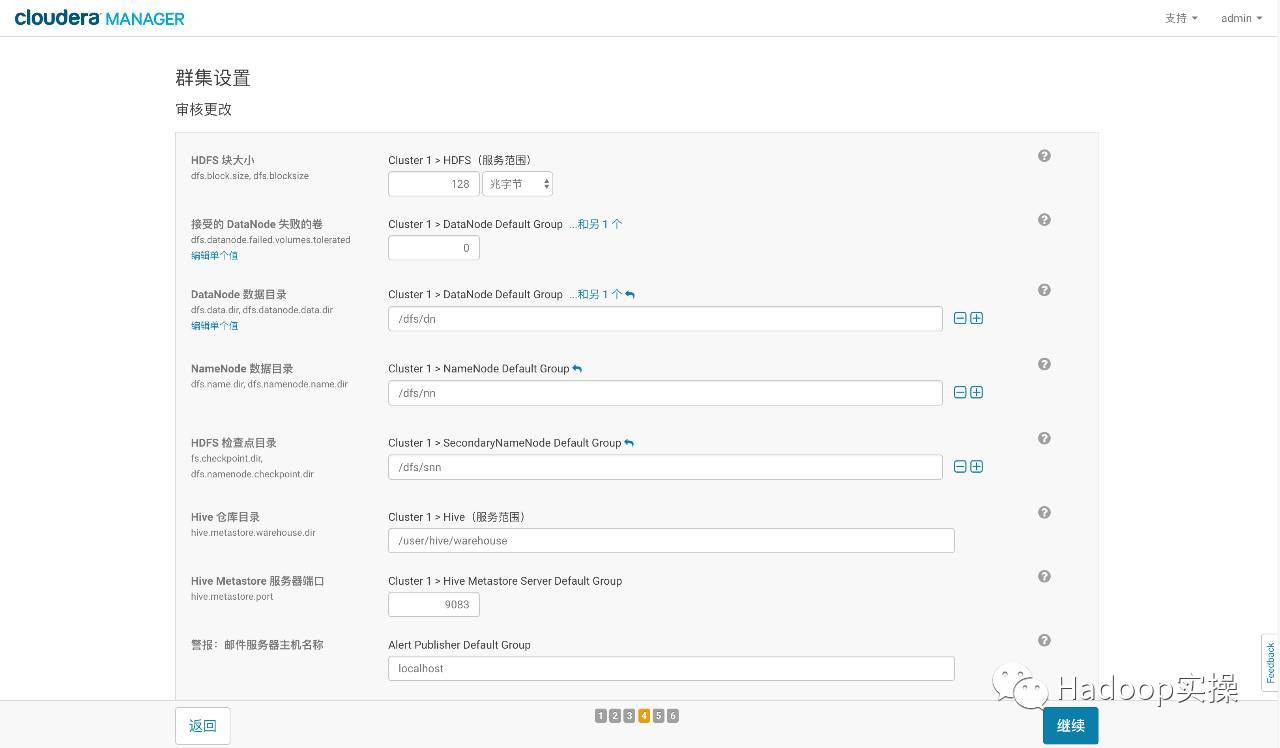
- Configuration review changes
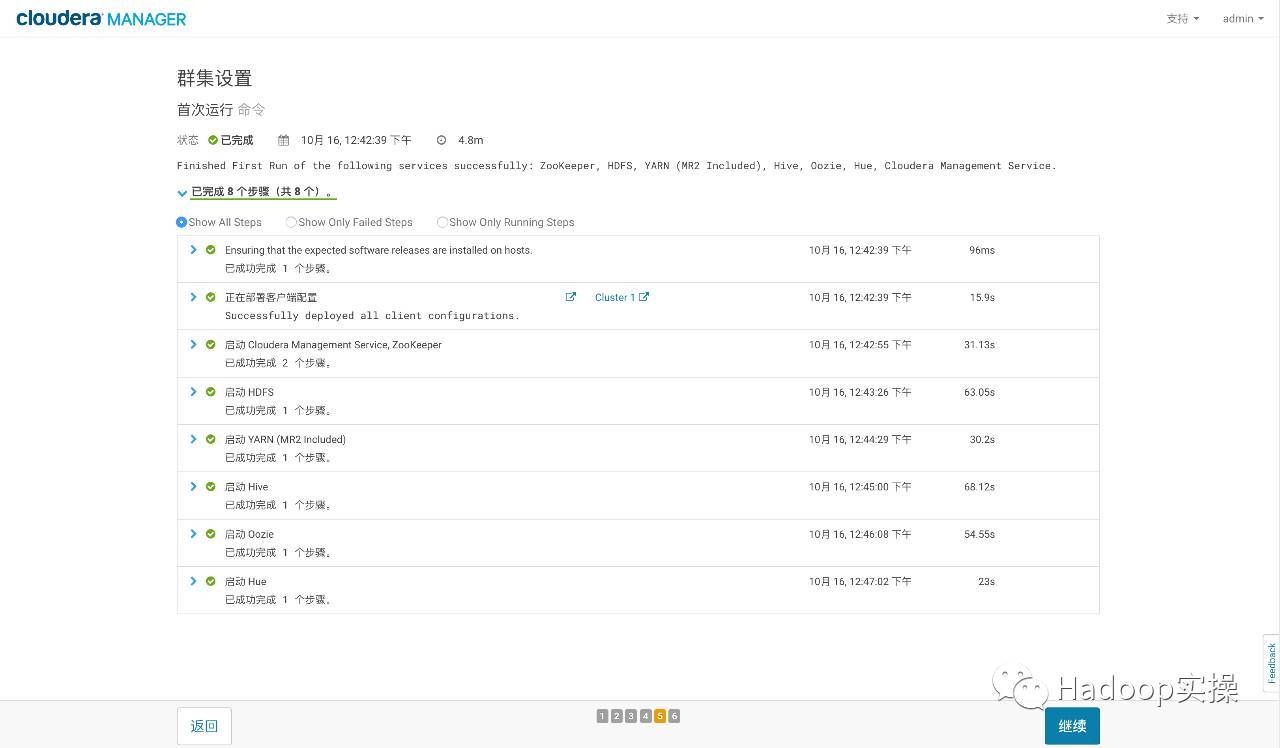
- Cluster first run
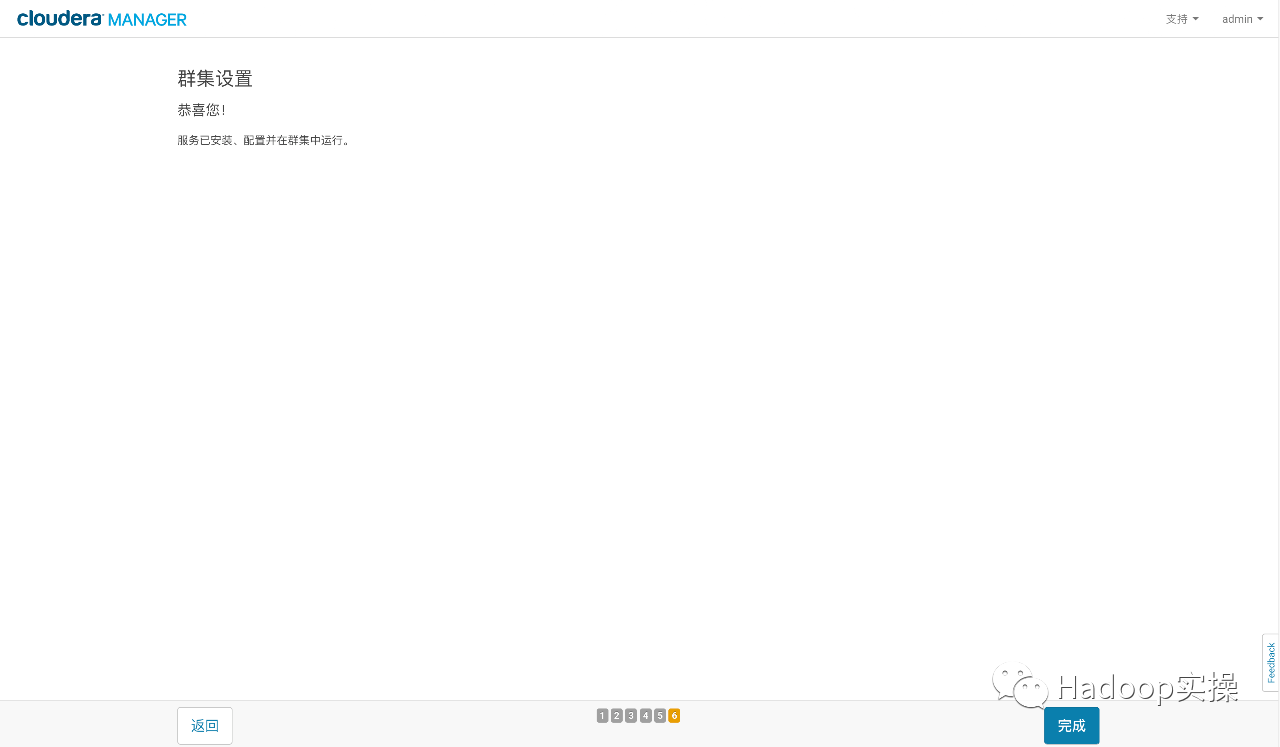
- The cluster is installed successfully
- Go to CM homepage to view CM and CDH version
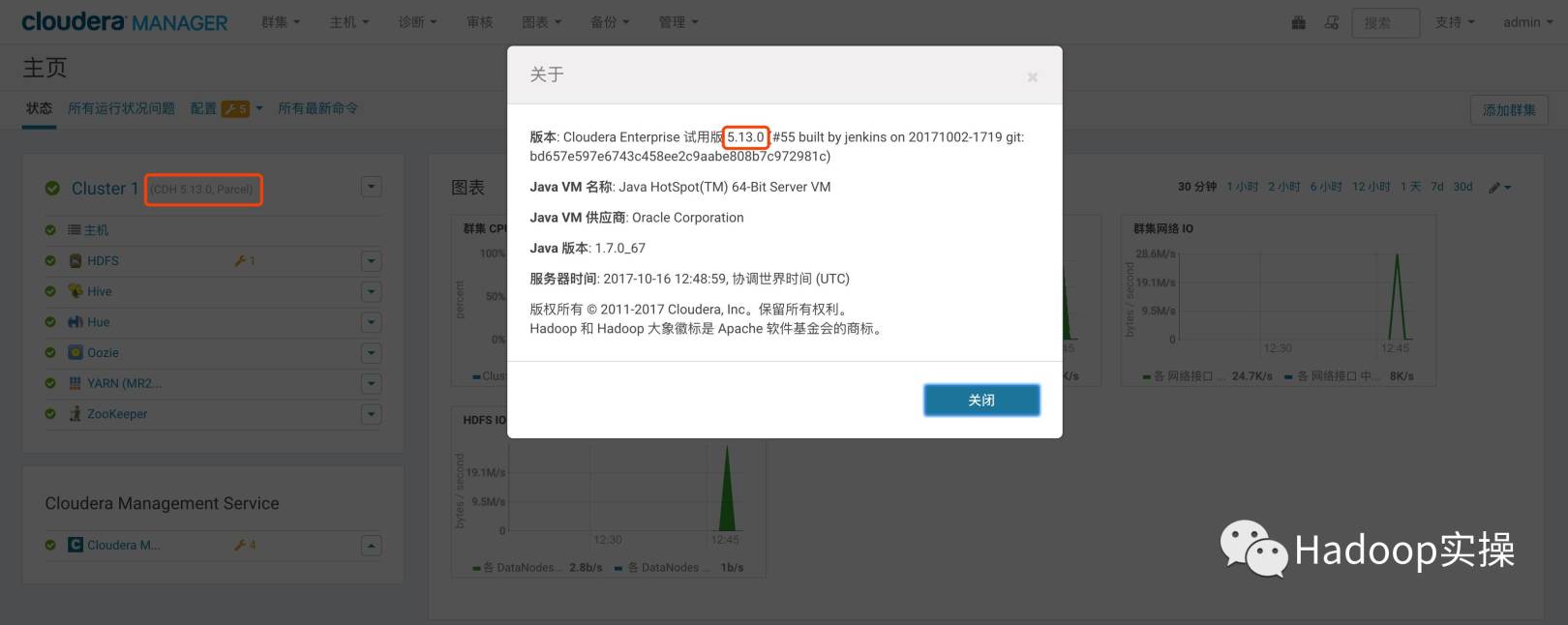
3.3 Kudu installation
Starting from the CDH 5.13.0 version, Kudu has been integrated in the Parcels package of CDH. Therefore, the installation is simpler and more convenient than before.
- Log in to CM to enter the homepage, click "Add Service" on the corresponding cluster

- Enter the service selection interface and select "Kudu"
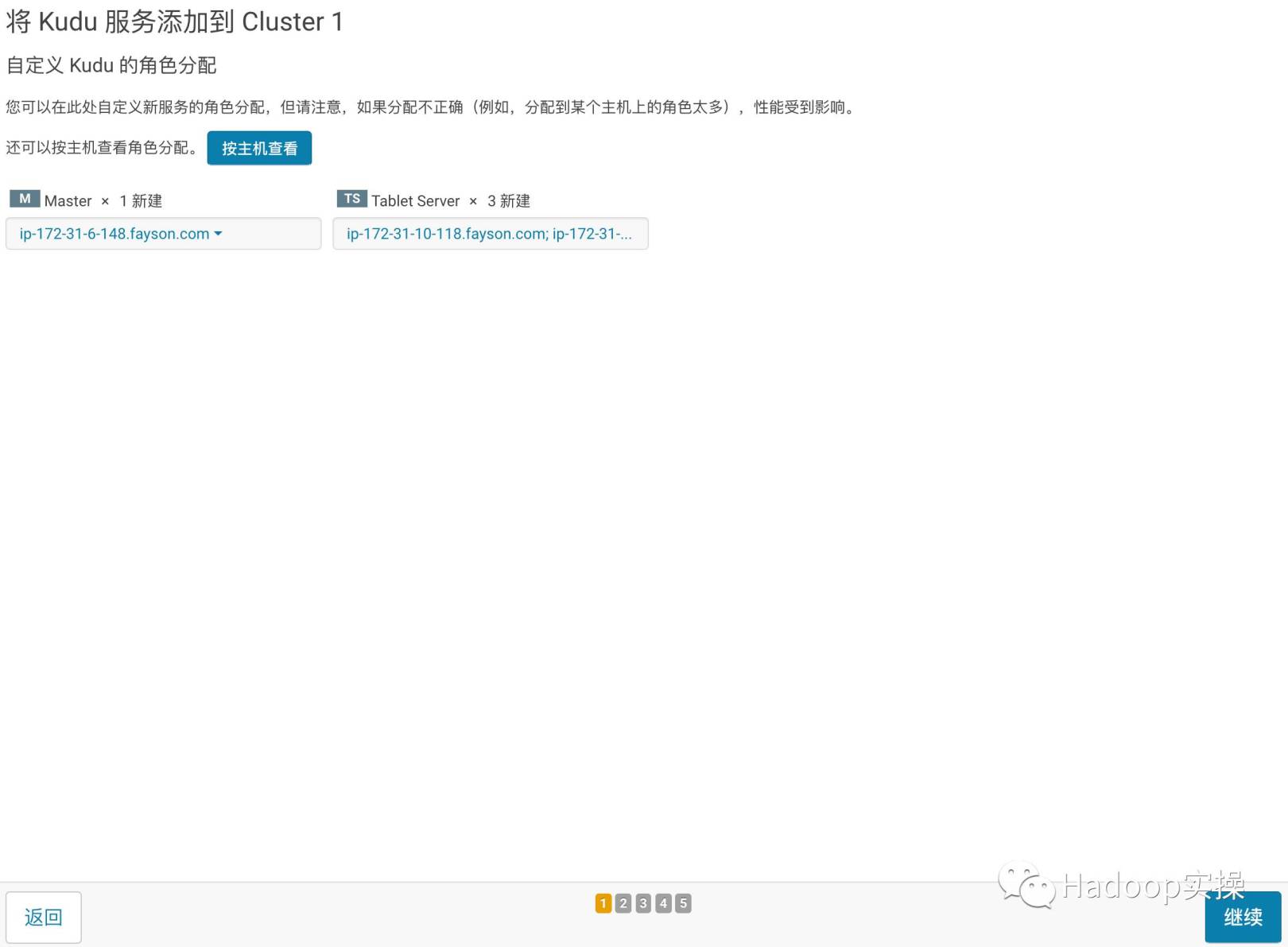
- Click Continue to enter Kudu role assignment, assign Kudu Master and Tablet Server
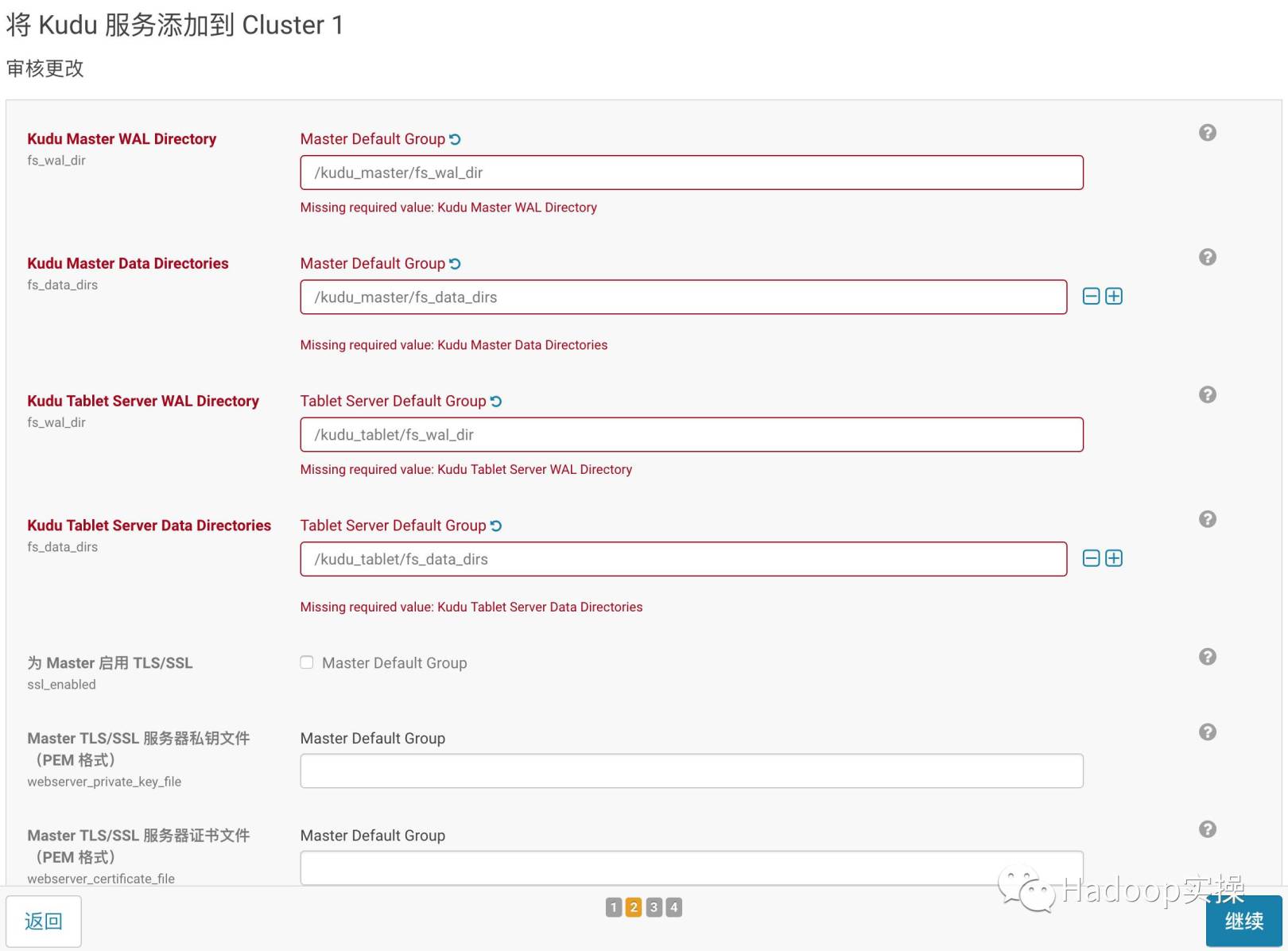
- Click Continue to configure Kudu's WAL and Data directories
- Click "Continue" to add the Kudu service to the cluster and start it

- Click "Continue" to complete the Kudu service installation

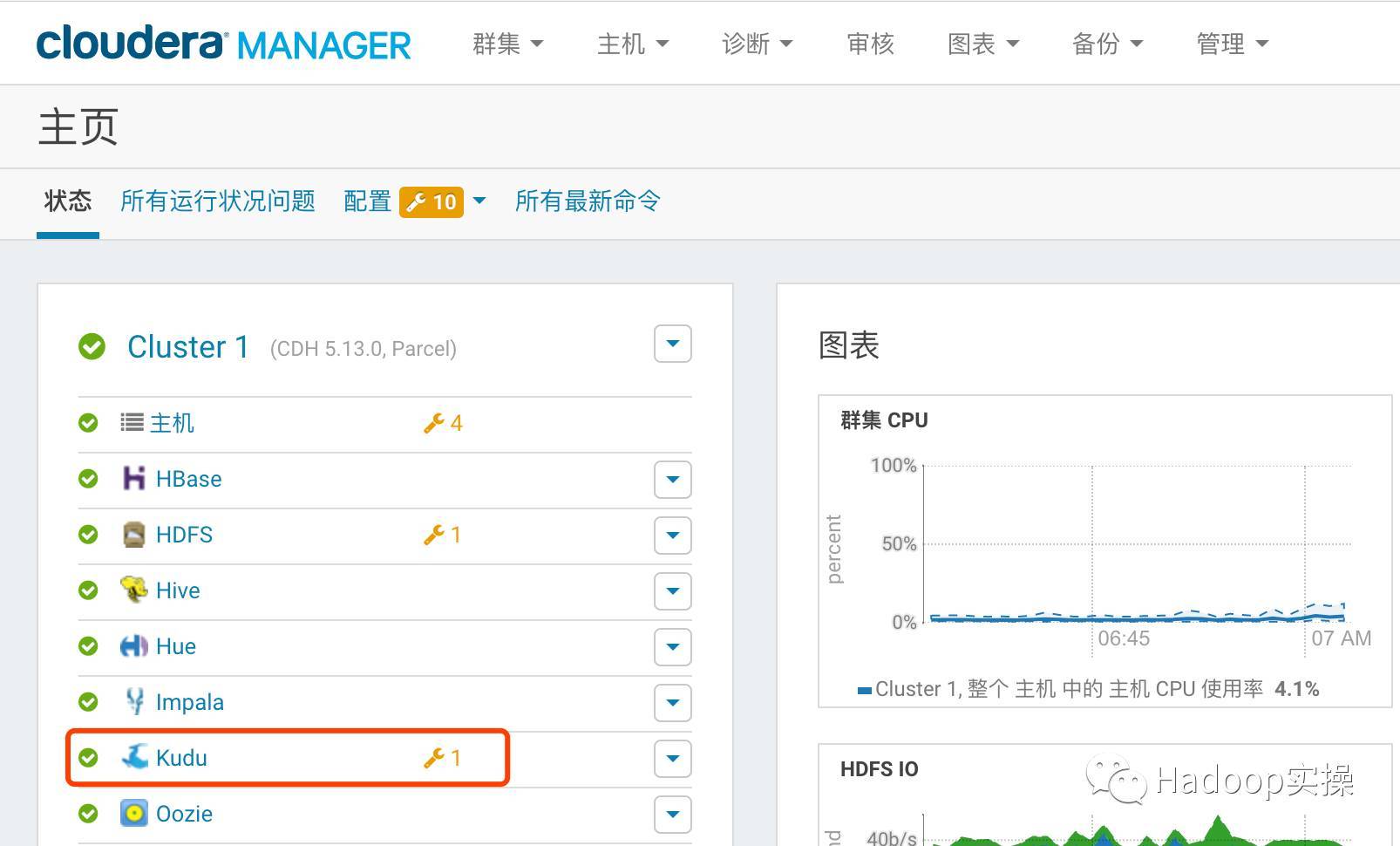
- Check the CM homepage, the Kudu service is installed successfully
- Configure Impala to integrate with Kudu
By default, Impala can directly operate Kudu for SQL operations, but in order to save the need to add the kudu_master_addresses attribute in TBLPROPERTIES every time you create a table, it is recommended to configure the address of KuduMaster in the advanced configuration of Impala: --kudu_master_hosts=ip-172-31-6- 148.fayson.com:7051

Save the configuration, return to the CM homepage, and restart the corresponding service as prompted.
4. Fast component service verification
4.1 HDFS verification (mkdir+put+cat+get)
[ root@ip-172-31-6-148~]# hadoop fs -mkdir -p /fayson/test_table
[ root@ip-172-31-6-148~]# cat a.txt
1, test
2, fayson
3, zhangsan
[ root@ip-172-31-6-148~]#hadoop fs -put a.txt /fayson/test_table
[ root@ip-172-31-6-148~]# hadoop fs -cat /fayson/test_table/a.txt
1, test
2, fayson
3, zhangsan
[ root@ip-172-31-6-148~]# rm -rf a.txt
[ root@ip-172-31-6-148~]# hadoop fs -get/fayson/test_table/a.txt .[root@ip-172-31-6-148~]# cat a.txt
1, test
2, fayson
3, zhangsan
[ root@ip-172-31-6-148~]#

4.2 Hive verification
[ root@ip-172-31-6-148~]# hive
hive>> create external table test_table(> s1 string,> s2 string
>)> row format delimited fields terminated by ','> stored as textfilelocation '/fayson/test_table';
OK
Time taken:2.117 seconds
hive> select *from test_table;
OK
1 test
2 fayson
3 zhangsan
Time taken:0.683 seconds, Fetched:3row(s)
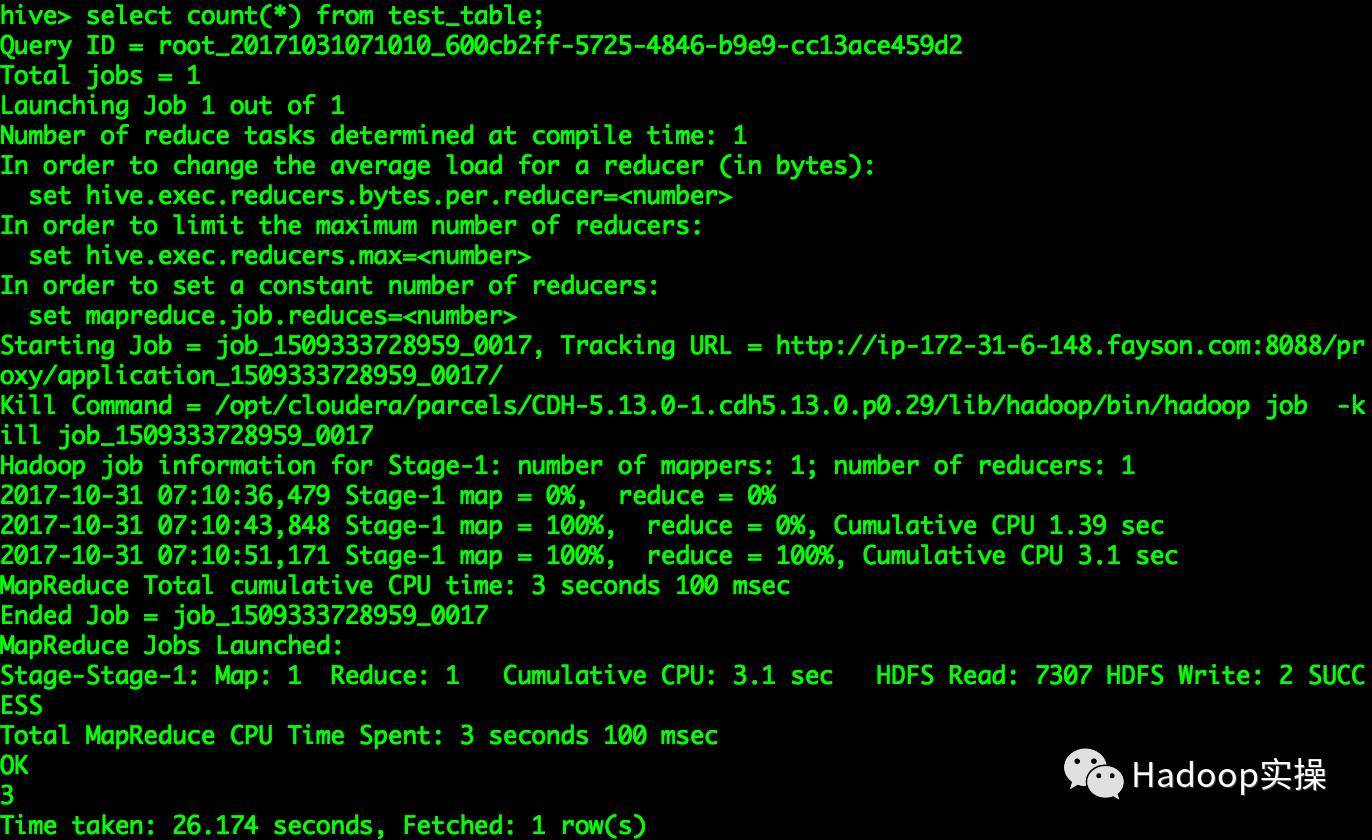
hive> select count(*)from test_table;...
OK
3
Time taken:26.174 seconds, Fetched:1row(s)
hive>

4.3 MapReduce verification
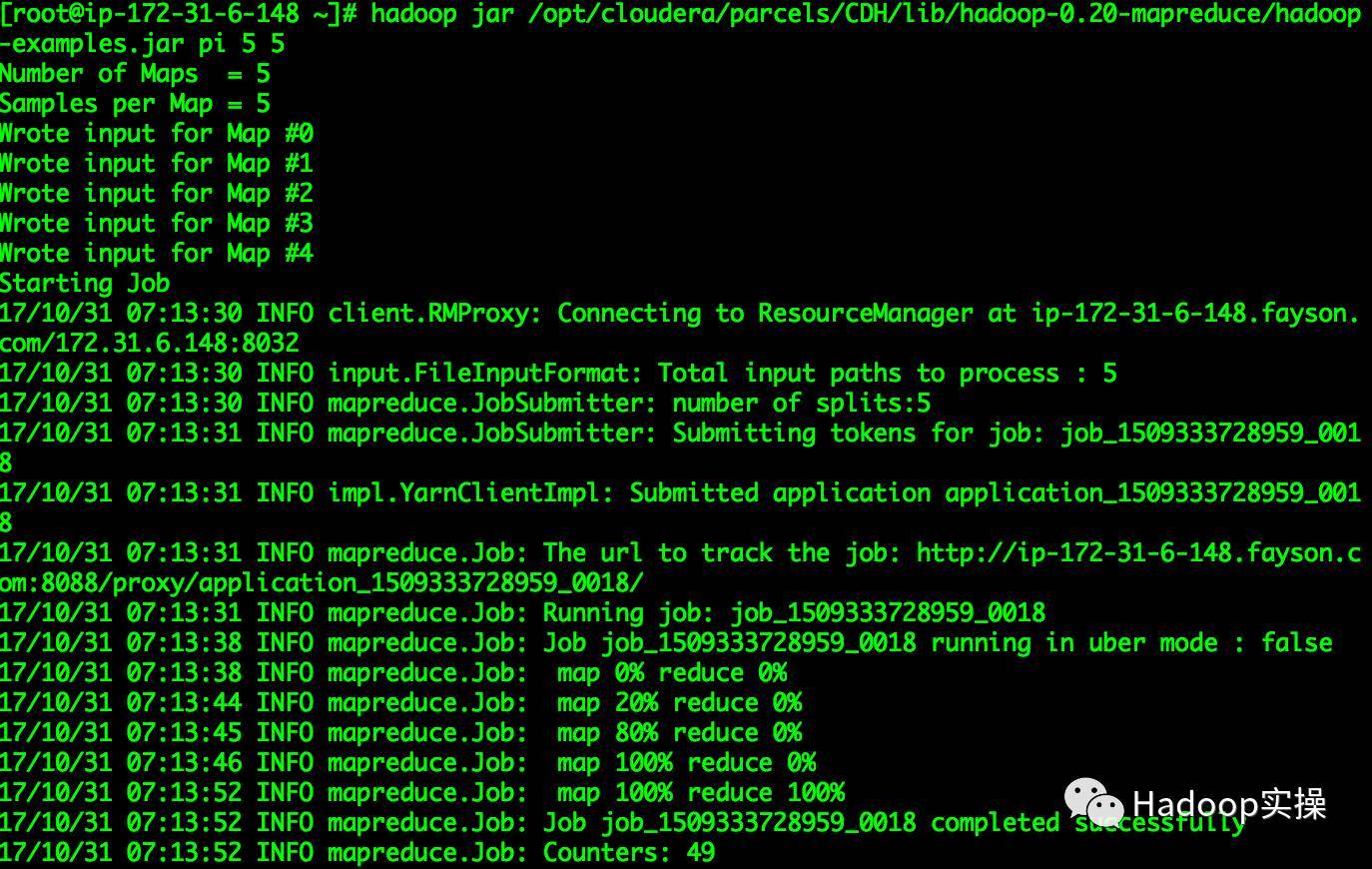
root@ip-172-31-6-148~]# hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/hadoop-examples.jar pi 55...17/10/3107:13:52 INFO mapreduce.Job: map 100% reduce 100%17/10/3107:13:52 INFO mapreduce.Job: Job job_1509333728959_0018 completedsuccessfully
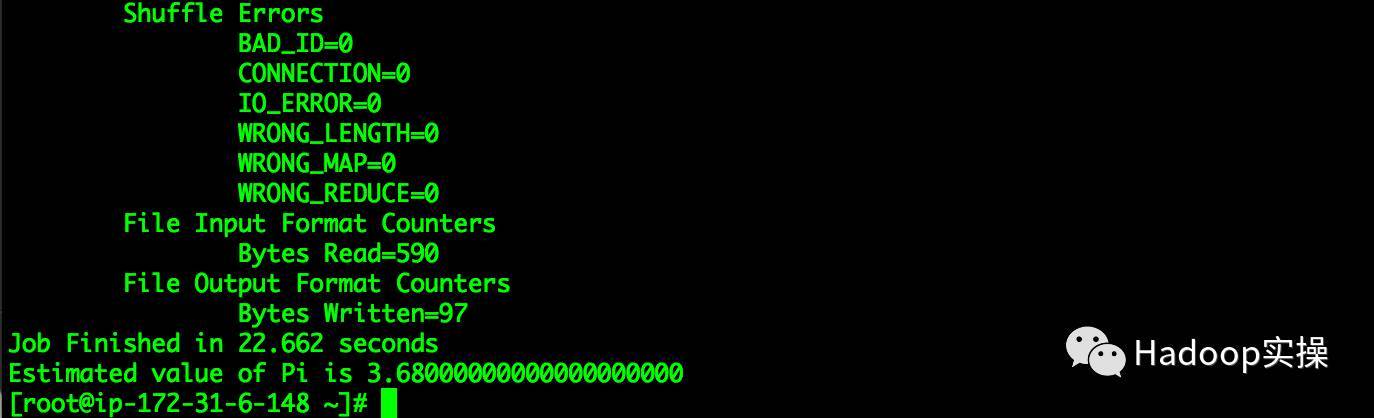
...
Job Finished in22.662 seconds
Estimated value of Pi is 3.68000000000000000000[root@ip-172-31-6-148~]#
4.4 Impala verification
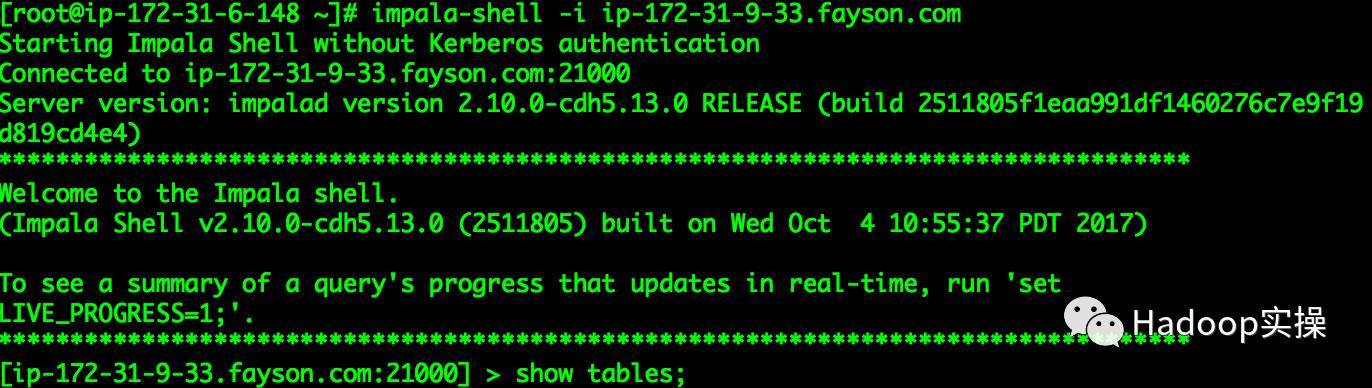
[ root@ip-172-31-6-148~]# impala-shell -i ip-172-31-9-33.fayson.com
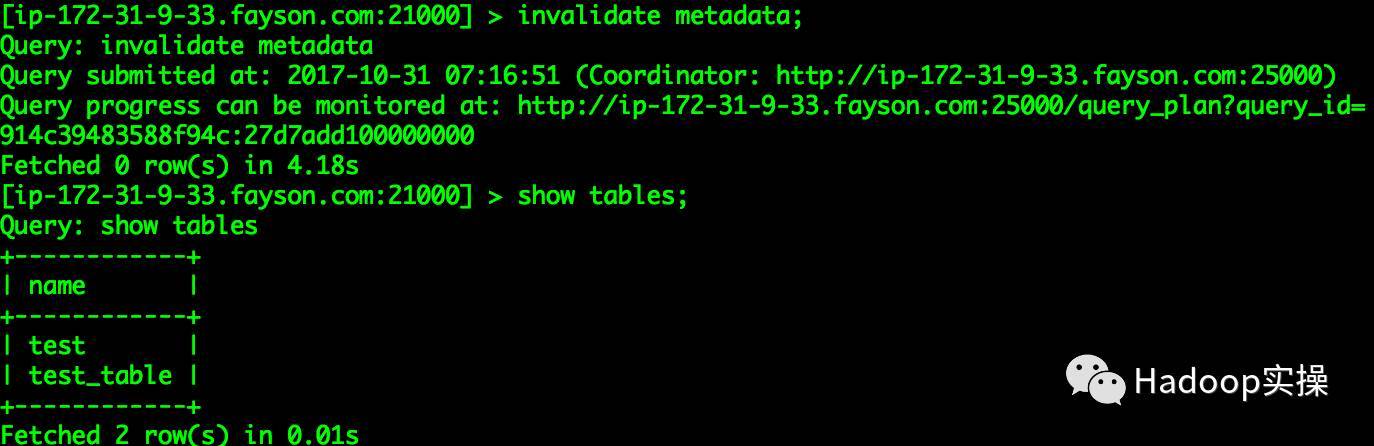
...[ ip-172-31-9-33.fayson.com:21000]> invalidate metadata;...
Fetched 0row(s)in4.18s
[ ip-172-31-9-33.fayson.com:21000]> show tables;
Query: show tables
+- - - - - - - - - - - - +| name |+------------+| test || test_table|+------------+
Fetched 2row(s)in0.01s
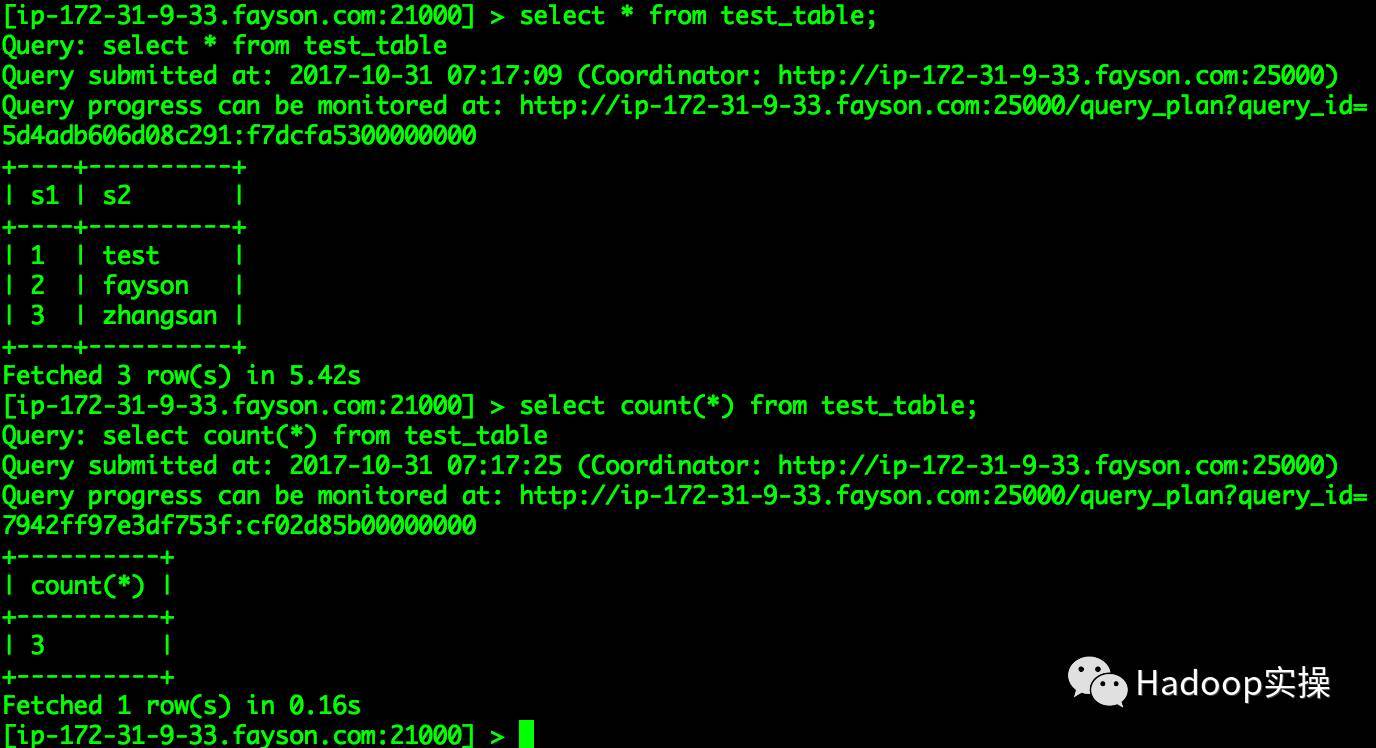
[ ip-172-31-9-33.fayson.com:21000]> select *from test_table;...+----+----------+| s1 | s2 |+----+----------+|1| test ||2| fayson ||3| zhangsan |+----+----------+
Fetched 3row(s)in5.42s
[ ip-172-31-9-33.fayson.com:21000]> select count(*)from test_table;...+----------+|count(*)|+----------+|3|+----------+
Fetched 1row(s)in0.16s
[ ip-172-31-9-33.fayson.com:21000]>
4.5 Spark verification
[ root@ip-172-31-6-148~]# spark-shell
Welcome to
____ __
/ __/__ ___ _____//__
_\ \ / _ \/ _ `/__/ '_//___/.__/\_,_/_//_/\_\ version 1.6.0/_/
Using Scala version 2.10.5(Java HotSpot(TM)64-Bit ServerVM, Java 1.7.0_67)...
scala>var textFile=sc.textFile("/fayson/test_table/a.txt")
textFile: org.apache.spark.rdd.RDD[String]=/fayson/test_table/a.txt MapPartitionsRDD[1] at textFile at <console>:27
scala> textFile.count()
res0: Long =3
scala>

4.6 Kudu verification
[ root@ip-172-31-6-148~]# impala-shell -i ip-172-31-9-33.fayson.com
...[ ip-172-31-9-33.fayson.com:21000]> CREATE TABLE my_first_table(> id BIGINT,> name STRING,> PRIMARY KEY(id)>)> PARTITION BY HASH PARTITIONS 16> STORED AS KUDU;...
Fetched 0row(s)in2.40s
[ ip-172-31-9-33.fayson.com:21000]> INSERT INTO my_first_table VALUES(99,"sarah");...
Modified 1row(s),0 row error(s)in4.14s
[ ip-172-31-9-33.fayson.com:21000]> INSERT INTO my_first_table VALUES(1,"john"),(2,"jane"),(3,"jim");...
Modified 3row(s),0 row error(s)in0.11s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+-------+| id | name |+----+-------+|1| john ||99| sarah ||2| jane ||3| jim |+----+-------+
Fetched 4row(s)in1.12s
[ ip-172-31-9-33.fayson.com:21000]>deletefrom my_first_table where id =99;...
Modified 1row(s),0 row error(s)in0.17s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+------+| id | name |+----+------+|1| john ||2| jane ||3| jim |+----+------+
Fetched 3row(s)in0.14s
[ ip-172-31-9-33.fayson.com:21000]> update my_first_table set name='fayson' where id=1;...
Modified 1row(s),0 row error(s)in0.14s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+--------+| id | name |+----+--------+|2| jane ||3| jim ||1| fayson |+----+--------+
Fetched 3row(s)in0.04s
[ ip-172-31-9-33.fayson.com:21000]> upsert into my_first_table values(1,"john"),(2,"tom");...
Modified 2row(s),0 row error(s)in0.11s
[ ip-172-31-9-33.fayson.com:21000]> select *from my_first_table;...+----+------+| id | name |+----+------+|2| tom ||3| jim ||1| john |+----+------+
Fetched 3row(s)in0.06s
[ ip-172-31-9-33.fayson.com:21000]> select count(*)from my_first_table;...+----------+|count(*)|+----------+|3|+----------+
Fetched 1row(s)in0.39s
[ ip-172-31-9-33.fayson.com:21000]>

Set up a heart for the heaven and the earth, set up a life for the people, for the sacred and inherit the best knowledge, and open peace for all ages.
Reminder: To see the high-definition uncoded set of pictures, please use your mobile phone to open and click the picture to enlarge it.
It is recommended to pay attention to the actual operation of Hadoop, and share more Hadoop dry goods at the first time. Welcome to forward and share.
Original article, welcome to reprint, please indicate: Reprinted from WeChat public account Hadoop practical operation

Recommended Posts