Centos 7.4 install stand-alone Spark

Foreword###
Due to personal learning needs, I will study how to install Spark. However, due to my limited financial resources, I have not yet joined the cluster. Let’s try the stand-alone version of Spark first. If there is an expansion later, update the cluster installation tutorial synchronously.
All the following operations are based on the
rootuser.
0. Install Scala
0.1 Before installation
You need to install Scala before installing Spark, because Spark depends on Scala. So let's install Scala first, and download the compressed package of Scala from Scala official website.
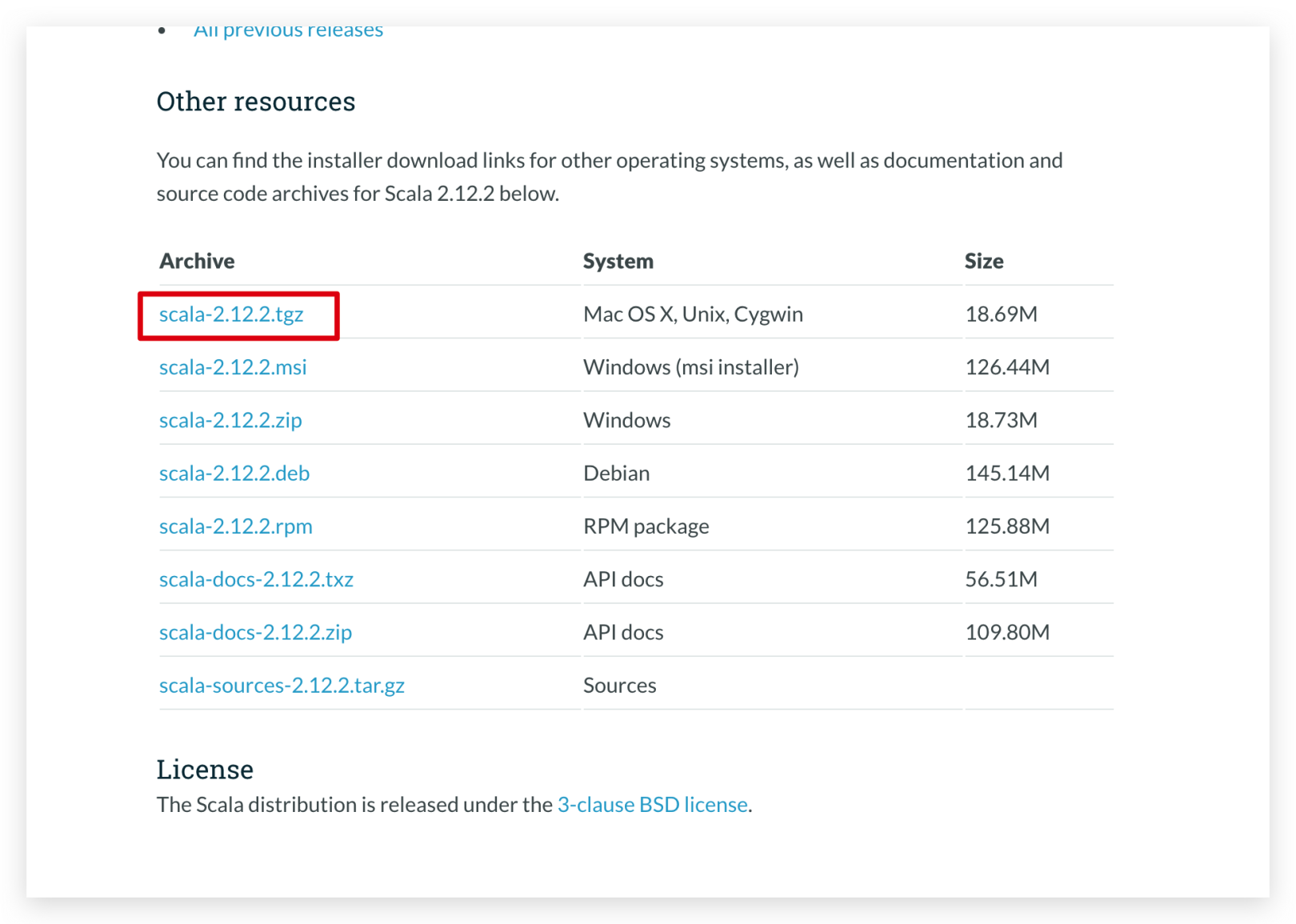
Then we upload the compressed package to the Centos server, how to upload it will not be detailed here.
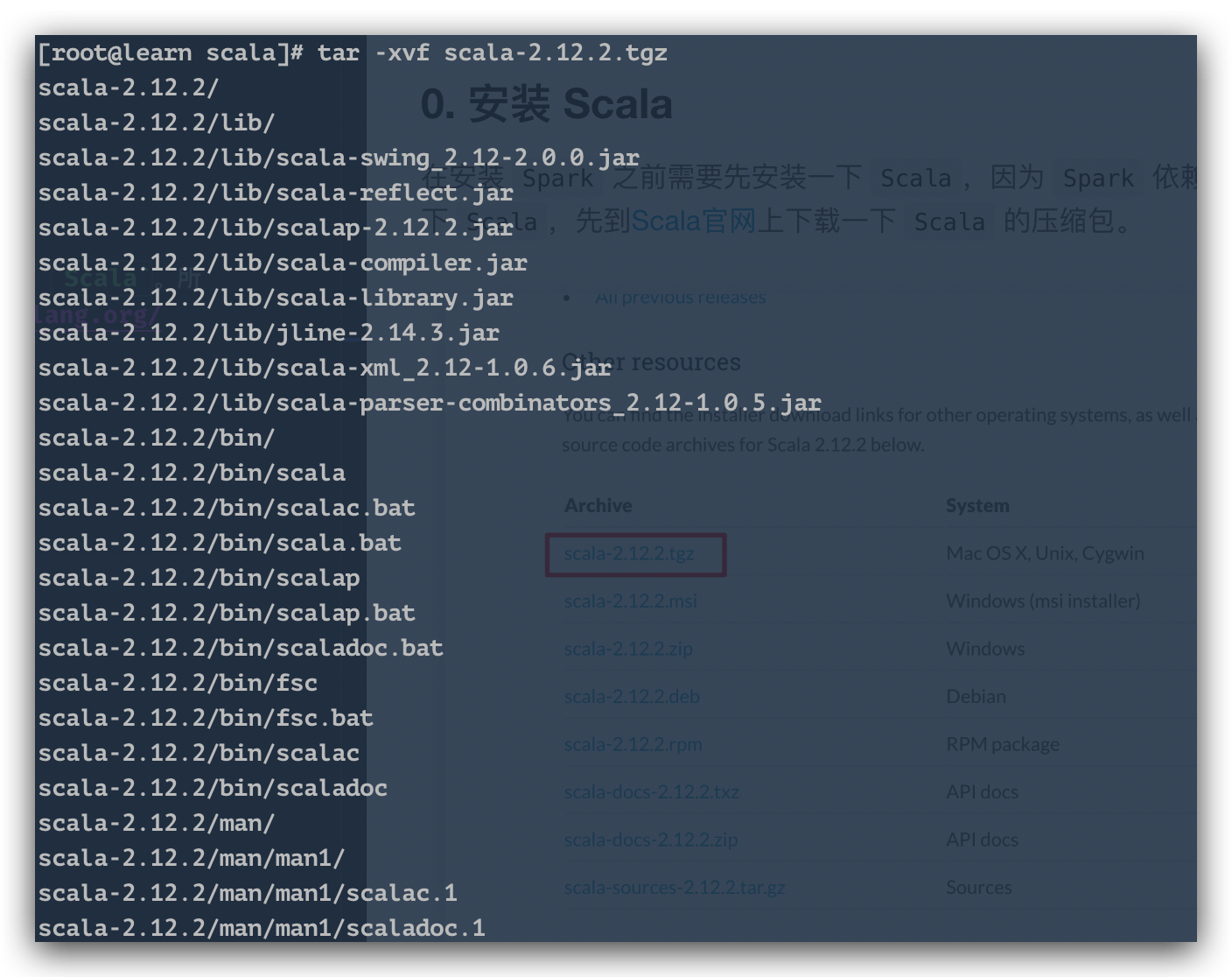
We put the compressed package in the /opt/scala directory, and then unzip it.
Unzip command
tar -xvf scala-2.12.2.tgz
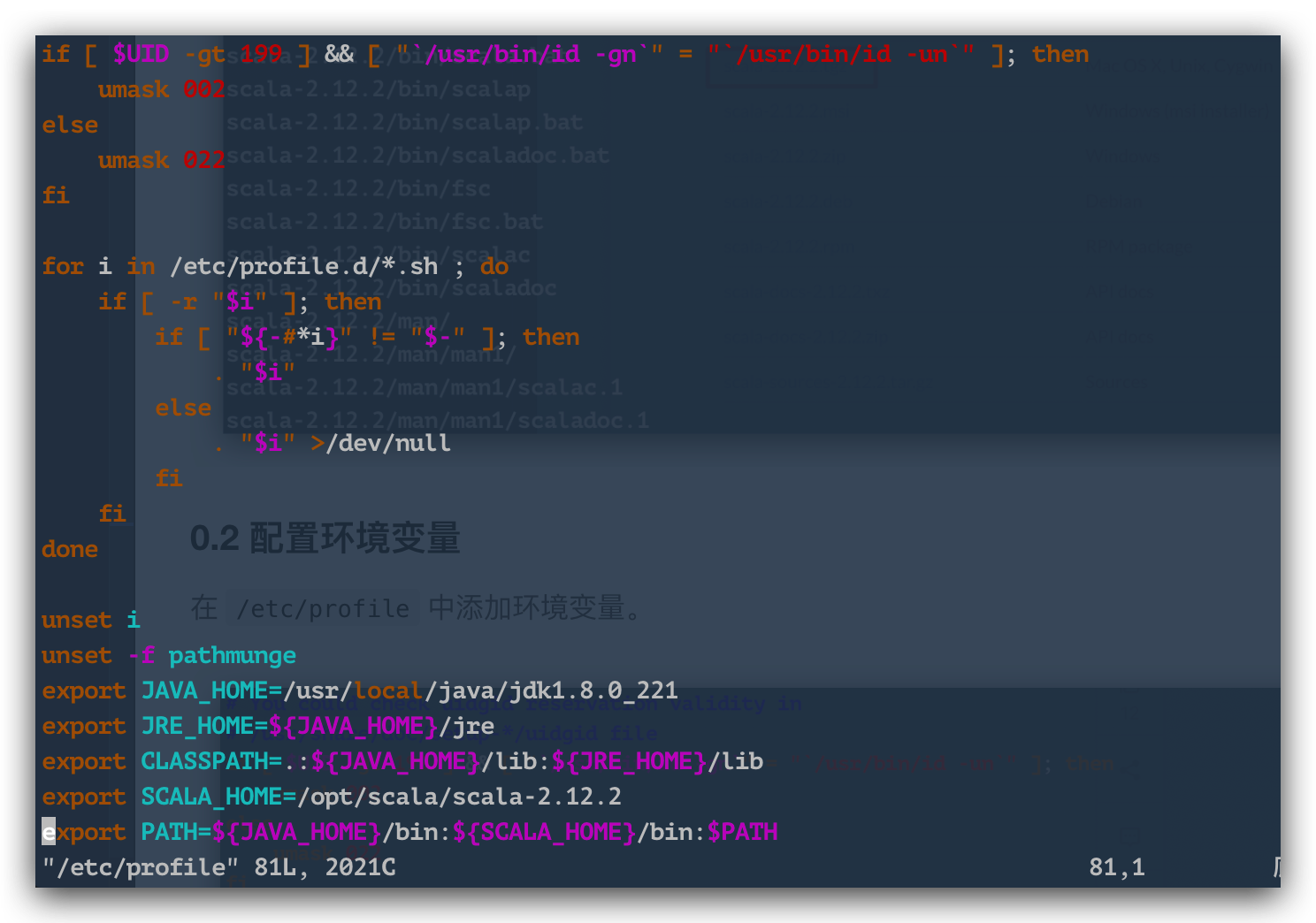
0.2 Configure environment variables
Add environment variables in /etc/profile, add export SCALA_HOME=/opt/scala/scala-2.12.2 and add ${SCALA_HOME}/bin: in path.
Below are my environment variables.
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export SCALA_HOME=/opt/scala/scala-2.12.2export PATH=${JAVA_HOME}/bin:${SCALA_HOME}/bin:$PATH
Then we can verify scala:

At this point, the installation of scala is complete, and the next step is the installation of Spark~~~
1. Install Spark
1.1 Download and unzip####
Same as Scala, let’s go shopping and download the package first, and then upload it to the server.
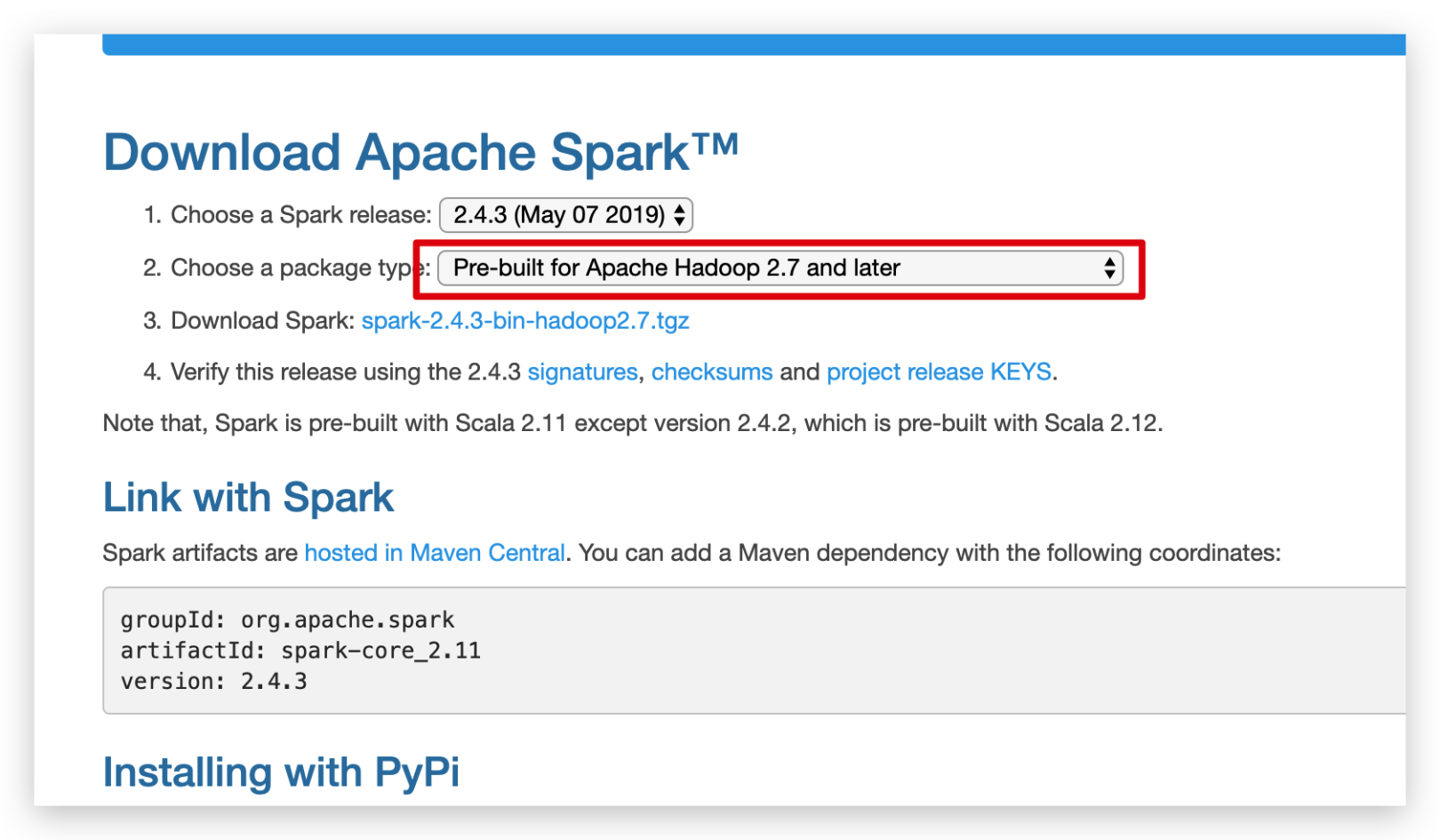
In the same way, we put the compressed package in the /opt/spark directory, and then unzip it.
Unzip command
tar -xvf spark-2.4.3-bin-hadoop2.7.tgz
1.2 Configure environment variables
Similar to the small differences, add environment variables in /etc/profile, add export SPARK_HOME=/opt/spark/spark-2.4.3-bin-hadoop2.7 and add ${SPARK_HOME}/bin in path :.
Below are my environment variables.
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export SCALA_HOME=/opt/scala/scala-2.12.2export SPARK_HOME=/opt/spark/spark-2.4.3-bin-hadoop2.7export PATH=${JAVA_HOME}/bin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
1.3 Configure Spark
First enter the conf directory of the decompressed file, which is /opt/spark/spark-2.4.3-bin-hadoop2.7/conf/, we can see that there is a template file, we copy One serving.
cp spark-env.sh.template spark-env.sh
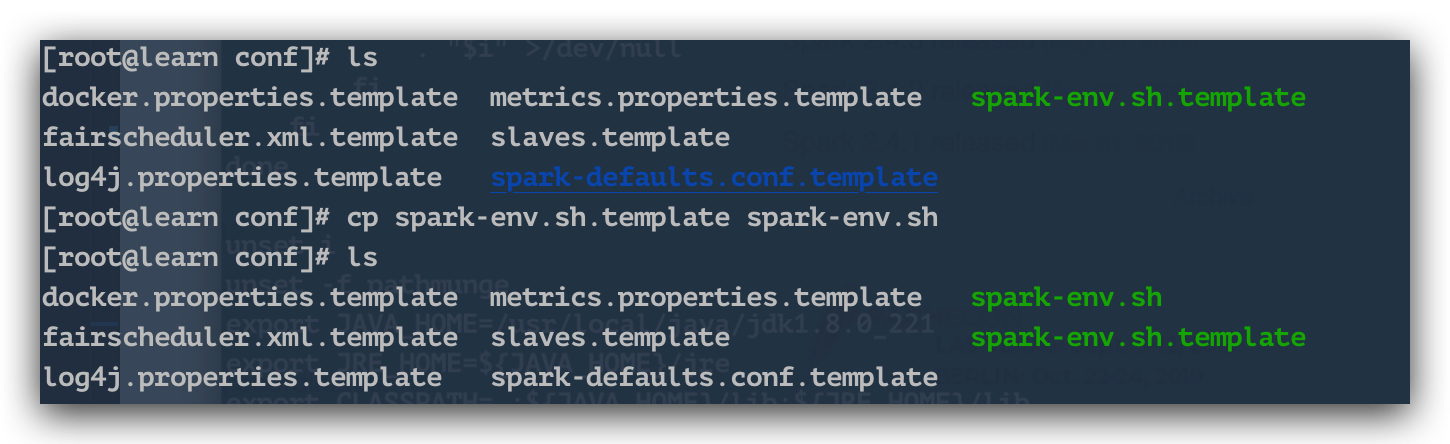
We edit the copied file and add the following content:
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export SCALA_HOME=/opt/scala/scala-2.12.2export SPARK_HOME=/opt/spark/spark-2.4.3-bin-hadoop2.7export SPARK_MASTER_IP=learn
export SPARK_EXECUTOR_MEMORY=1G
Similarly, we make a copy of slaves
cp slaves.template slaves
Edit slaves, the content is localhost:
localhost
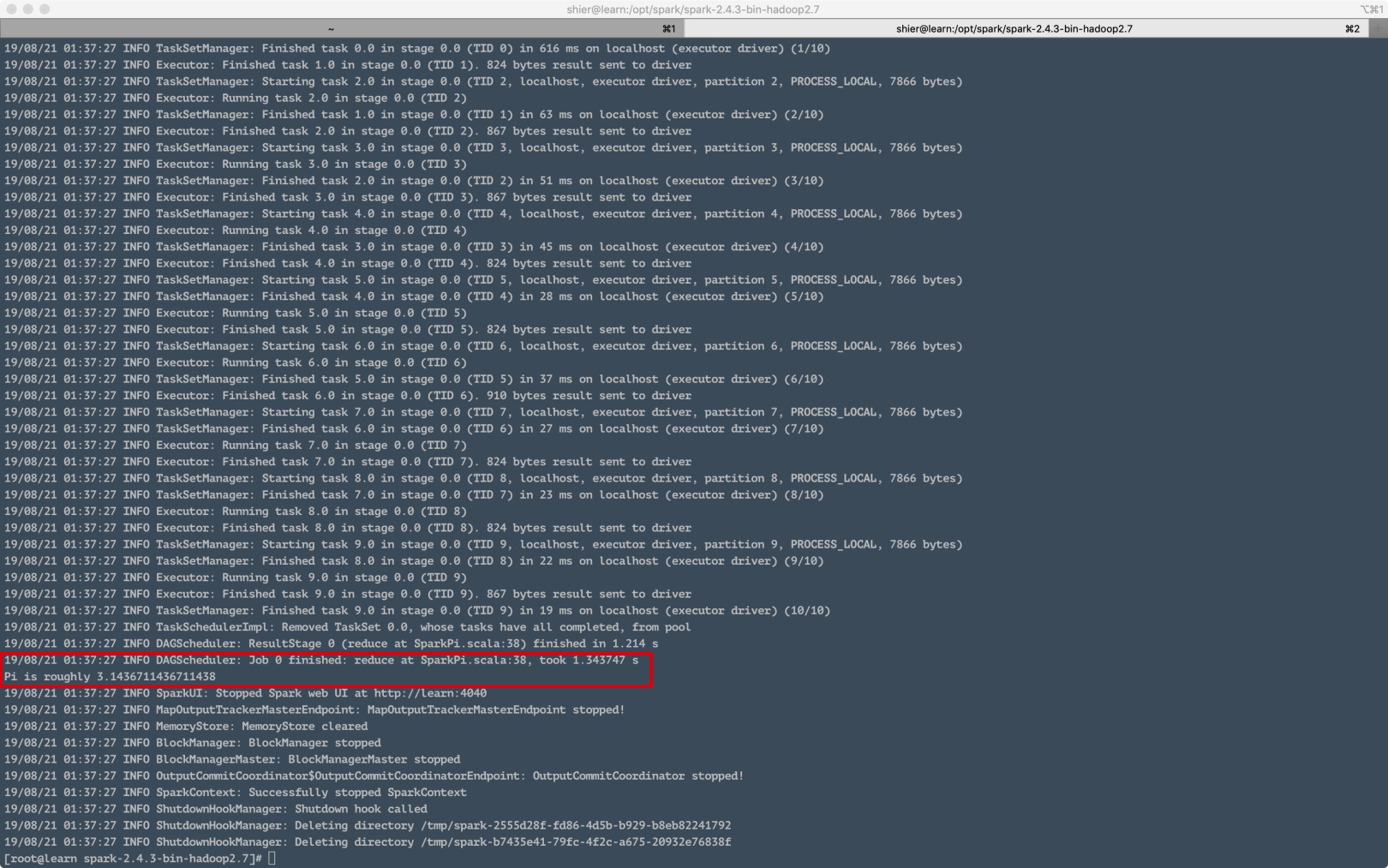
Then we can test, /opt/spark/spark-2.4.3-bin-hadoop2.7 execute in this directory:
. /bin/run-example SparkPi 10
Here we can see that the execution has been successful.
1.4 Start Spark Shell
The same as above is also in the /opt/spark/spark-2.4.3-bin-hadoop2.7 directory, execute:
. /bin/spark-shell
We can see the following results:
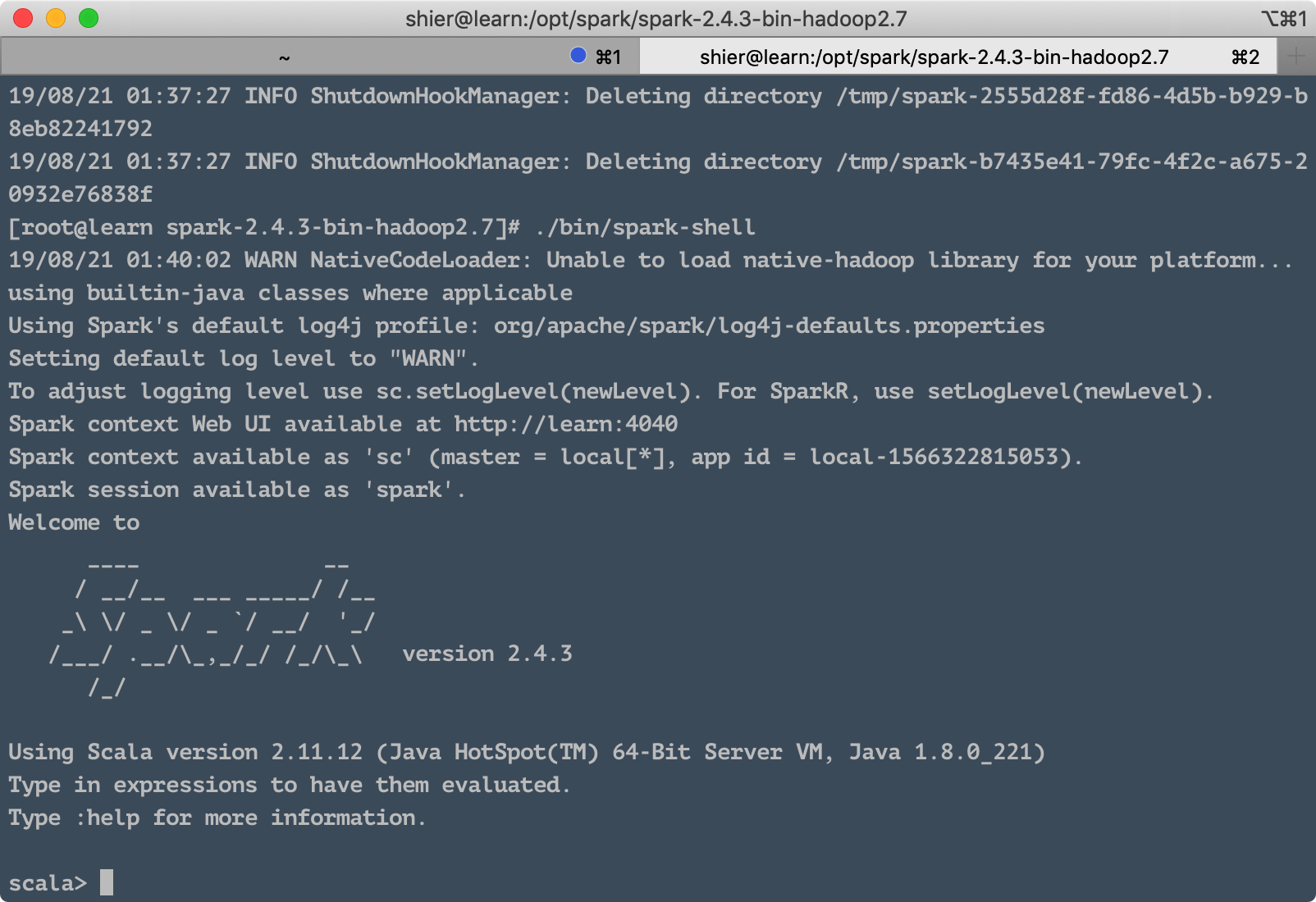
So far, the stand-alone version of Spark is installed~~~
Recommended Posts